Java简单实现爬虫技术,抓取整个网站所有链接+图片+文件(思路+代码)
写这个纯属个人爱好,前两天想玩爬虫,但是百度了一大圈也没发现有好一点的帖子,所以就自己研究了下,亲测小点的网站还是能随随便便爬完的,由于是单线程所以速度嘛~~你懂的
(多线程没学好,后期再慢慢加上多线程吧)
先上几张效果图
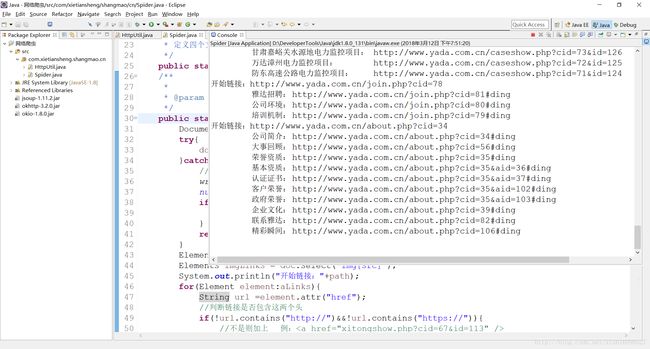
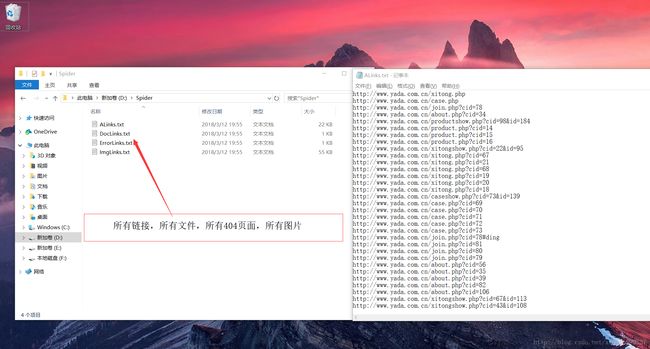
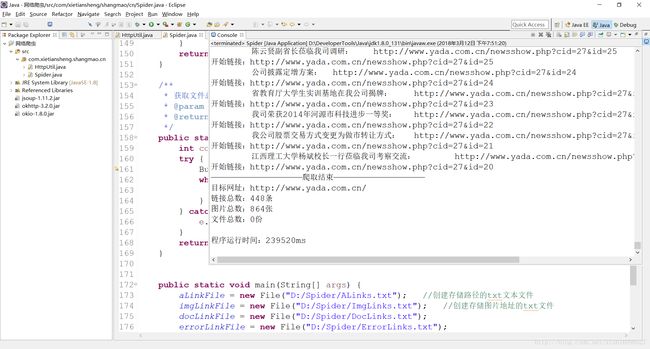
需要用到的知识点
- 网络请求(至于用哪个嘛,看个人喜好,文章用的是okhttp)
- File文件读写
- Jsoup框架(html解析器)
需要的jar包
- jsoup-1.11.2.jar
- okhttp-3.10.0.jar
- okio-1.8.0.jar
注意:okhttp内部依赖okio,别忘了同时导入okio
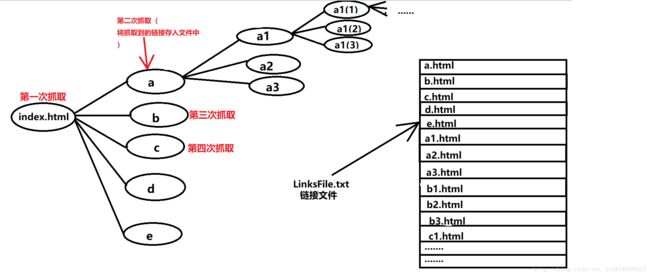
难点
- 如图(随便弄了个草图)
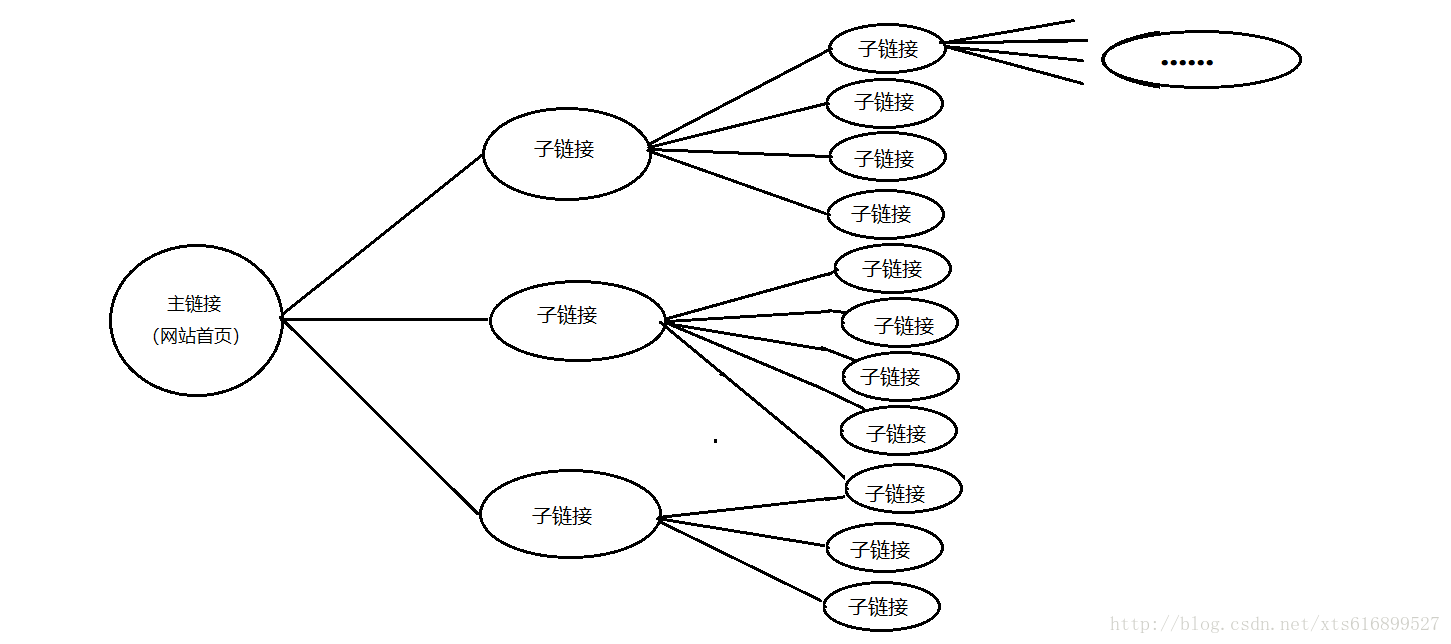
- 要说技术难点的话,无非就是如何遍历整个网站了,首先,要考虑到的是抓取到一个链接后,这个链接里面肯定还有好几十甚至上百个链接,接下来这几十个链接里面又有链接,链接里面有链接一层一层嵌套,该如何去获取这些链接?
实现思路
- 1.链接存储
- 使用文件操作储存所有链接,至于为什么不用集合存储,据博主了解,写爬虫基本都不用集合去存储数据,原因在于链接多了之后会报内存溢出错误。也就是集合里面存太多东西了,然后还要对它进行查找操作,所以不推荐使用集合进行储存。
- 2.链接读取
- 将每次读到的链接存入.txt文本文件中,这里要注意的是每次存入链接的时候要在后面加上\r\n(换行),也就是让每个链接各占一行,这样有利于后期以行的形式读取链接。
- 3.链接遍历
- ①、获取首页链接中的子链接,存入文件中,已行为单位存储。
- ②、定义一个变量num(默认为-1),用于记录当前读的是第几条链接,每次遍历完一条链接后 判断如果(num<链接文件行数 )则 num++。
- ③、遍历解析链接的方法,每一次遍历的目标链接等于 文件内的第num行
这样基本就实现了链接的遍历
举个栗子
假设index.html页面内有5个子链接分别对应 a~e.html,解析index.html页面后将该页面中的5个链接存入文件中,num++(此时num=0),文件中的1~5行就分别对应这5个链接,第二次调用读取方法的时候用到的链接就是文件中的第num行,也就是a.html。
接着解析a.html,将a.html中的所有超链接追加进文件中。
上图:
图中的遍历方式似乎有点像一个横放着的wifi信号
接下来贴代码:
- 首先创建两个类
- HttpUtil.java (网络请求类,用于获取网页源代码)
- Spider.java (爬虫主代码)
HttpUtil.java 类
import java.io.IOException;
import java.util.ArrayList;
import java.util.concurrent.TimeUnit;
import okhttp3.Call;
import okhttp3.FormBody;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
/**
* Created by XieTiansheng on 2018/3/7.
*/
public class HttpUtil {
private static OkHttpClient okHttpClient;
private static int num = 0;
static{
okHttpClient = new OkHttpClient.Builder()
.readTimeout(1, TimeUnit.SECONDS)
.connectTimeout(1, TimeUnit.SECONDS)
.build();
}
public static String get(String path){
//创建连接客户端
Request request = new Request.Builder()
.url(path)
.build();
//创建"调用" 对象
Call call = okHttpClient.newCall(request);
try {
Response response = call.execute();//执行
if (response.isSuccessful()) {
return response.body().string();
}
} catch (IOException e) {
System.out.println("链接格式有误:"+path);
}
return null;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
这个就不多写注释了 百度有一大堆okhttp教程
Spider.java 类
- 首先定义要爬的网站首页与储存链接的文件对象
public static String path = "http://www.yada.com.cn/"; //雅达公司官网
public static int num = -1,sum = 0;
/**
* 定义四个文件类(链接存储,图片储存,文件存储,错误链接存储)
*/
public static File aLinkFile,imgLinkFile,docLinkFile,errorLinkFile;
- 1
- 2
- 3
- 4
- 5
- 6
- 解析html页面的方法
/**
*
* @param path 目标地址
*/
public static void getAllLinks(String path){
Document doc = null;
try{
doc = Jsoup.parse(HttpUtil.get(path));
}catch (Exception e){
//解析出的错误链接(404页面)
writeTxtFile(errorLinkFile, path+"\r\n"); //写入错误链接收集文件
num++;
if(sum>num){ //如果文件总数(sum)大于num(当前读取位置)则继续遍历
getAllLinks(getFileLine(aLinkFile, num));
}
return;
}
//获取html代码中所有带有href属性的a标签,和图片
Elements aLinks = doc.select("a[href]");
Elements imgLinks = doc.select("img[src]");
System.out.println("本次抓取的链接:"+path);
for(Element element:aLinks){
String url =element.attr("href");
//判断链接是否包含这两个头
if(!url.contains("http://")&&!url.contains("https://")){
//不是则加上 例:
//则需要加上前缀 http://www.yada.com.cn/xitongshow.php?cid=67&id=113
//否则下次解析该链接的时候会报404错误
url = Spider.path+url;//网站首页加上该链接
}
//如果文件中没有这个链接,而且链接中不包含javascript:则继续(因为有的是用js语法跳转)
if(!readTxtFile(aLinkFile).contains(url)
&&!url.contains("javascript")){
//路径必须包含网页主链接--->防止爬入别的网站
if(url.contains(Spider.path)){
//判断该a标签的内容是文件还是子链接
if(url.contains(".doc")||url.contains(".exl")
||url.contains(".exe")||url.contains(".apk")
||url.contains(".mp3")||url.contains(".mp4")){
//写入文件中,文件名+文件链接
writeTxtFile(docLinkFile, element.text()+"\r\n\t"+url+"\r\n");
}else{
//将链接写入文件
writeTxtFile(aLinkFile, url+"\r\n");
sum++; //链接总数+1
}
System.out.println("\t"+element.text()+":\t"+url);
}
}
}
//同时抓取该页面图片链接
for(Element element:imgLinks){
String srcStr = element.attr("src");
if(!srcStr.contains("http://")&&!srcStr.contains("https://")){//没有这两个头
srcStr = Spider.path+srcStr;
}
if(!readTxtFile(imgLinkFile).contains(srcStr)){
//将图片链接写进文件中
writeTxtFile(imgLinkFile, srcStr+"\r\n");
}
}
num++;
if(sum>num){ //如果文件总数(sum)大于num(当前读取位置)则继续遍历
getAllLinks(getFileLine(aLinkFile, num));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
该方法用于解析html页面,取到所有链接,存入文件
- 两个操作文件的方法(读/取)
/**
* 读取文件
* @param file 文件类
* @return 文件内容
*/
public static String readTxtFile(File file){
String result = ""; //读取結果
String thisLine = ""; //每次读取的行
try {
BufferedReader reader = new BufferedReader(new FileReader(file));
try {
while((thisLine=reader.readLine())!=null){
result += thisLine+"\n";
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
return result;
}
/**
* 写入内容
* @param file 文件类
* @param urlStr 要写入的文本
*/
public static void writeTxtFile(File file,String urlStr){
try {
BufferedWriter writer = new BufferedWriter(new FileWriter(file,true));
writer.write(urlStr);
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
简单的文件操作方法,用于储存每次解析出来的链接
- 获取文件中的指定行内容
/**
* 获取文件指定行数的数据,用于爬虫获取当前要爬的链接
* @param file 目标文件
* @param num 指定的行数
*/
public static String getFileLine(File file,int num){
String thisLine = "";
int thisNum = 0 ;
try {
BufferedReader reader = new BufferedReader(new FileReader(file));
while((thisLine = reader.readLine())!=null){
if(num == thisNum){
return thisLine;
}
thisNum++;
}
} catch (Exception e) {
e.printStackTrace();
}
return "";
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
这个方法很重要,用于获取文件中的第几条链接
- 下面是这个类的完整代码
package com.xietiansheng.shangmao.cn;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.lang.reflect.Field;
import java.util.ArrayList;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import okio.ForwardingTimeout;
public class Spider {
public static String path = "http://www.yada.com.cn/"; //雅达公司官网
public static int num = -1,sum = 0;
/**
* 定义四个文件类(链接存储,图片储存,文件存储,错误链接存储)
*/
public static File aLinkFile,imgLinkFile,docLinkFile,errorLinkFile;
/**
*
* @param path 目标地址
*/
public static void getAllLinks(String path){
Document doc = null;
try{
doc = Jsoup.parse(HttpUtil.get(path));
}catch (Exception e){
//接收到错误链接(404页面)
writeTxtFile(errorLinkFile, path+"\r\n"); //写入错误链接收集文件
num++;
if(sum>num){ //如果文件总数(sum)大于num(当前坐标)则继续遍历
getAllLinks(getFileLine(aLinkFile, num));
}
return;
}
Elements aLinks = doc.select("a[href]");
Elements imgLinks = doc.select("img[src]");
System.out.println("开始链接:"+path);
for(Element element:aLinks){
String url =element.attr("href");
//判断链接是否包含这两个头
if(!url.contains("http://")&&!url.contains("https://")){
//不是则加上 例:
//则需要加上前缀 http://www.yada.com.cn/xitongshow.php?cid=67&id=113
//否则404
url = Spider.path+url;
}
//如果文件中没有这个链接,而且链接中不包含javascript:则继续(因为有的是用js语法跳转)
if(!readTxtFile(aLinkFile).contains(url)
&&!url.contains("javascript")){
//路径必须包含网页主链接--->防止爬入别的网站
if(url.contains(Spider.path)){
//判断该a标签的内容是文件还是子链接
if(url.contains(".doc")||url.contains(".exl")
||url.contains(".exe")||url.contains(".apk")
||url.contains(".mp3")||url.contains(".mp4")){
//写入文件中,文件名+文件链接
writeTxtFile(docLinkFile, element.text()+"\r\n\t"+url+"\r\n");
}else{
//将链接写入文件
writeTxtFile(aLinkFile, url+"\r\n");
sum++; //链接总数+1
}
System.out.println("\t"+element.text()+":\t"+url);
}
}
}
//同时抓取该页面图片链接
for(Element element:imgLinks){
String srcStr = element.attr("src");
if(!srcStr.contains("http://")&&!srcStr.contains("https://")){//没有这两个头
srcStr = Spider.path+srcStr;
}
if(!readTxtFile(imgLinkFile).contains(srcStr)){
//将图片链接写进文件中
writeTxtFile(imgLinkFile, srcStr+"\r\n");
}
}
num++;
if(sum>num){
getAllLinks(getFileLine(aLinkFile, num));
}
}
/**
* 读取文件内容
* @param file 文件类
* @return 文件内容
*/
public static String readTxtFile(File file){
String result = ""; //读取結果
String thisLine = ""; //每次读取的行
try {
BufferedReader reader = new BufferedReader(new FileReader(file));
try {
while((thisLine=reader.readLine())!=null){
result += thisLine+"\n";
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
return result;
}
/**
* 写入内容
* @param file 文件类
* @param urlStr 要写入的文本
*/
public static void writeTxtFile(File file,String urlStr){
try {
BufferedWriter writer = new BufferedWriter(new FileWriter(file,true));
writer.write(urlStr);
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 获取文件指定行数的数据,用于爬虫获取当前要爬的链接
* @param file 目标文件
* @param num 指定的行数
*/
public static String getFileLine(File file,int num){
String thisLine = "";
int thisNum = 0 ;
try {
BufferedReader reader = new BufferedReader(new FileReader(file));
while((thisLine = reader.readLine())!=null){
if(num == thisNum){
return thisLine;
}
thisNum++;
}
} catch (Exception e) {
e.printStackTrace();
}
return "";
}
/**
* 获取文件总行数(有多少链接)
* @param file 文件类
* @return 总行数
*/
public static int getFileCount(File file){
int count = 0;
try {
BufferedReader reader = new BufferedReader(new FileReader(file));
while(reader.readLine()!=null){ //遍历文件行
count++;
}
} catch (Exception e) {
e.printStackTrace();
}
return count;
}
public static void main(String[] args) {
aLinkFile = new File("D:/Spider/ALinks.txt");
imgLinkFile = new File("D:/Spider/ImgLinks.txt");
docLinkFile = new File("D:/Spider/DocLinks.txt");
errorLinkFile = new File("D:/Spider/ErrorLinks.txt");
//用数组存储四个文件对象,方便进行相同操作
File[] files = new File[]{aLinkFile,imgLinkFile,docLinkFile,errorLinkFile};
try {
for(File file: files){
if(file.exists()) //如果文件存在
file.delete(); //则先删除
file.createNewFile(); //再创建
}
} catch (IOException e) {
e.printStackTrace();
}
long startTime = System.currentTimeMillis(); //获取开始时间
Spider.getAllLinks(path); //开始爬取目标内容
System.out.println(""
+ "——————————————————爬取结束——————————————————"
+ "\n目标网址:"+path
+ "\n链接总数:"+sum+"条"
+ "\n图片总数:"+getFileCount(imgLinkFile)+"张"
+ "\n文件总数:"+getFileCount(docLinkFile)+"份");
writeTxtFile(aLinkFile, "链接总数:"+getFileCount(aLinkFile)+"条");
writeTxtFile(imgLinkFile, "图片总数:"+getFileCount(imgLinkFile)+"张");
writeTxtFile(docLinkFile, "文件总数:"+getFileCount(docLinkFile)+"份");
writeTxtFile(errorLinkFile, "问题链接总数:"+getFileCount(errorLinkFile)+"条");
long endTime = System.currentTimeMillis(); //获取结束时间
System.out.println("\n程序运行时间:" + (endTime - startTime) + "ms"); //输出程序运行时间
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
结束
代码比较初级
爬爬小网站就可以了
纯属娱乐而已
有问题可以给我留言或者在下面评论
可以用于服务端于安卓客户端结合达到想要的效果