Spark SQL从MySQL中加载数据以及将数据写入到mysql中 Spark Shell方式 Spark SQL程序
分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
1. JDBC
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中。
1.1. 从MySQL中加载数据(Spark Shell方式)
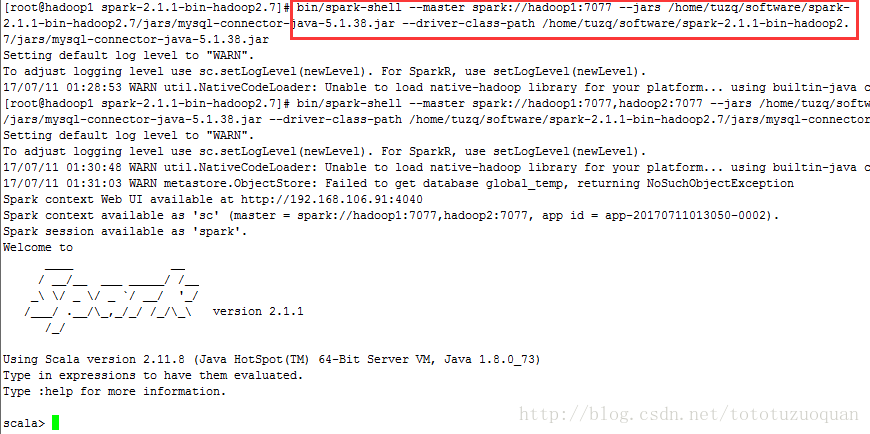
1.启动Spark Shell,必须指定mysql连接驱动jar包
[root@hadoop1 spark-2.1.1-bin-hadoop2.7]# bin/spark-shell --master spark://hadoop1:7077,hadoop2:7077 --jars /home/tuzq/software/spark-2.1.1-bin-hadoop2.7/jars/mysql-connector-java-5.1.38.jar --driver-class-path /home/tuzq/software/spark-2.1.1-bin-hadoop2.7/jars/mysql-connector-java-5.1.38.jar
- 1
2.从mysql中加载数据
进入bigdata中创建person表:
CREATE DATABASE bigdata CHARACTER SET utf8;USE bigdata;CREATE TABLE person ( id INT(10) AUTO_INCREMENT PRIMARY KEY, name varchar(100), age INT(3)) ENGINE=INNODB DEFAULT CHARSET=utf8;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
并初始化数据: 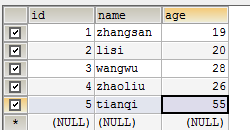
scala> val sqlContext = new org.apache.spark.sql.SQLContext(sc)
- 1
scala> val jdbcDF = sqlContext.read.format("jdbc").options(Map("url" -> "jdbc:mysql://hadoop10:3306/bigdata", "driver" -> "com.mysql.jdbc.Driver", "dbtable" -> "person", "user" -> "root", "password" -> "123456")).load()
- 1
3.执行查询
scala> jdbcDF.show+---+--------+---+| id| name|age|+---+--------+---+| 1|zhangsan| 19|| 2| lisi| 20|| 3| wangwu| 28|| 4| zhaoliu| 26|| 5| tianqi| 55|+---+--------+---+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1.2. 将数据写入到MySQL中(打jar包方式)
1.2.1编写Spark SQL程序
package cn.toto.sparkimport java.sql.DriverManagerimport org.apache.spark.rdd.JdbcRDDimport org.apache.spark.{SparkConf, SparkContext}/** * Created by toto on 2017/7/11. */object JdbcRDDDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("JdbcRDDDemo").setMaster("local[2]") val sc = new SparkContext(conf) val connection = () => { Class.forName("com.mysql.jdbc.Driver").newInstance() DriverManager.getConnection("jdbc:mysql://hadoop10:3306/bigdata","root","123456") } //这个地方没有读取数据(数据库表也用的是person) val jdbcRDD = new JdbcRDD( sc, connection, "SELECT * FROM person where id >= ? AND id <= ?", //这里表示从取数据库中的第1、2、3、4条数据,然后分两个区 1, 4, 2, r => { val id = r.getInt(1) val code = r.getString(2) (id, code) } ) //这里相当于是action获取到数据 val jrdd = jdbcRDD.collect() println(jrdd.toBuffer) sc.stop() }}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
注意在运行的时候使用的还是person这个表,表中的数据如下: 
如果是在IDEA中运行程序,程序结果如下: 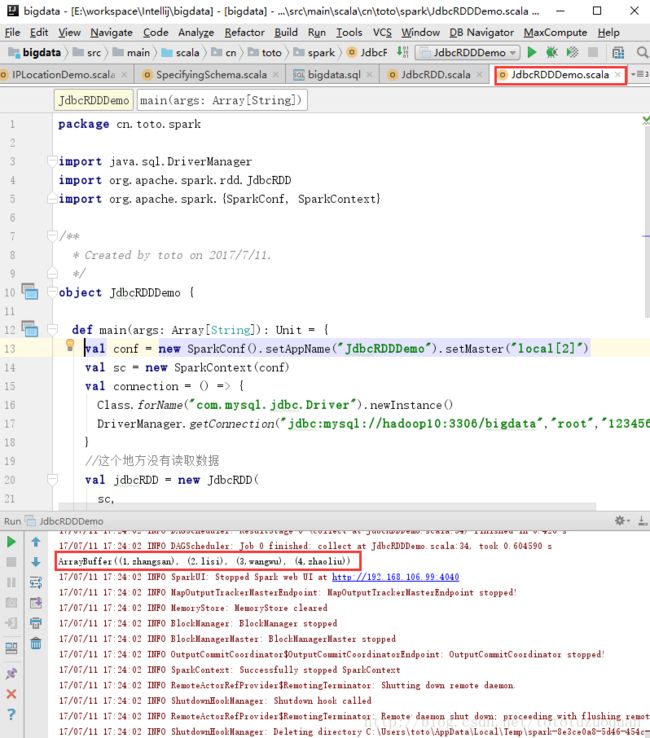
1.2.2用maven将程序打包
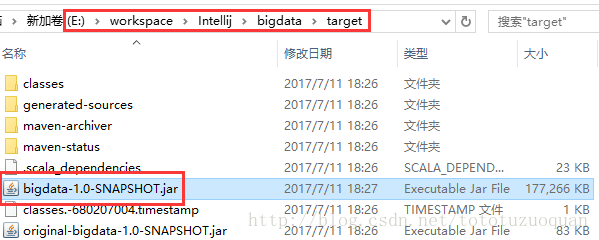
1.2.3.将Jar包提交到spark集群
将bigdata-1.0-SNAPSHOT.jar放到:/home/tuzq/software/sparkdata,如下: 
注意在运行执行,要将mysql-connector-java-5.1.38.jar 放到:/home/tuzq/software/spark-2.1.1-bin-hadoop2.7/jars/下
bin/spark-submit --class cn.toto.spark.JdbcRDDDemo --master spark://hadoop1:7077 --jars /home/tuzq/software/spark-2.1.1-bin-hadoop2.7/jars/mysql-connector-java-5.1.38.jar --driver-class-path /home/tuzq/software/spark-2.1.1-bin-hadoop2.7/jars/mysql-connector-java-5.1.38.jar /home/tuzq/software/sparkdata/bigdata-1.0-SNAPSHOT.jar
- 1
运行结果: 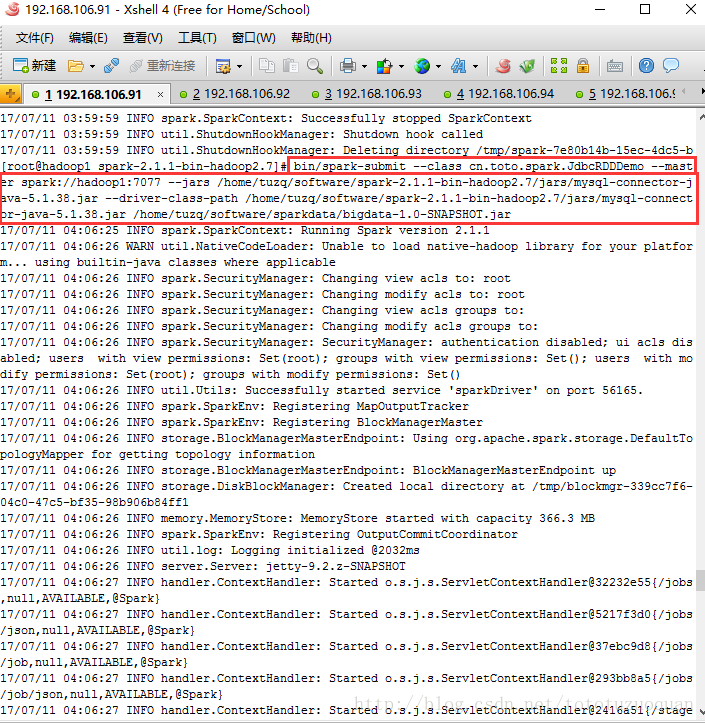
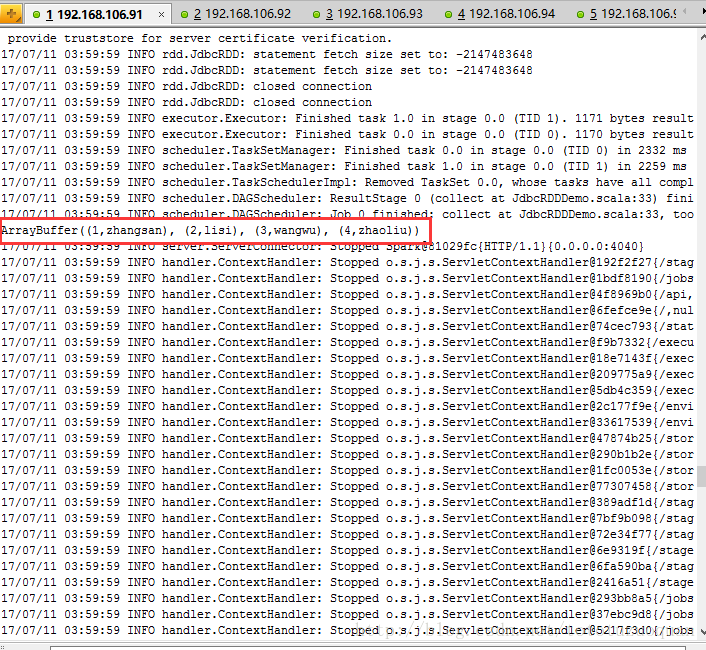
2、通过Spark-sql将数据存储到数据库中
2.2.1.代码如下:
package cn.toto.sparkimport java.util.Propertiesimport org.apache.spark.sql.{Row, SQLContext}import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}import org.apache.spark.{SparkConf, SparkContext}/** * Created by toto on 2017/7/11. */object JdbcRDD { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("MySQL-Demo").setMaster("local") val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) //通过并行化创建RDD val personRDD = sc.parallelize(Array("14 tom 5", "15 jerry 3", "16 kitty 6")).map(_.split(" ")) //通过StrutType直接指定每个字段的schema val schema = StructType( List( StructField("id",IntegerType,true), StructField("name",StringType,true), StructField("age",IntegerType,true) ) ) //将RDD映射到rowRDD val rowRDD = personRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).toInt)) //将schema信息应用到rowRDD上 val personDataFrame = sqlContext.createDataFrame(rowRDD,schema) //创建Properties存储数据库相关属性 val prop = new Properties() prop.put("user", "root") prop.put("password", "123456") //将数据追加到数据库 personDataFrame.write.mode("append").jdbc("jdbc:mysql://hadoop10:3306/bigdata", "bigdata.person",prop) //停止SparkContext sc.stop() }}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
运行结果: 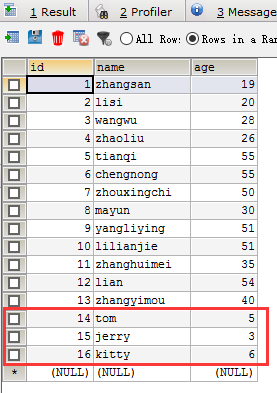
2.2.2、用maven将程序打包
2.2.3、将Jar包提交到spark集群
bin/spark-submit --class cn.toto.spark.JdbcRDD --master spark://hadoop1:7077 --jars /home/tuzq/software/spark-2.1.1-bin-hadoop2.7/jars/mysql-connector-java-5.1.38.jar --driver-class-path /home/tuzq/software/spark-2.1.1-bin-hadoop2.7/jars/mysql-connector-java-5.1.38.jar /home/tuzq/software/sparkdata/bigdata-1.0-SNAPSHOT.jar
- 1
给我老师的人工智能教程打call!http://blog.csdn.net/jiangjunshow
