NLP学习路径(六):NLP句法分析
1、句法分析
(1)主要任务:识别出句子所包含的的句法成分以及这些成分之间的关系,一般以句法树来表示句法分析的结果。
(2)难点:歧义;搜索空间
(3)句法分析种类:
①完全句法分析:以获取整个句子的句法结构为目的
②局部句法分析:只关注局部的一些成分,例如依存句法分析
(4)句法分析方法:基于规则(存在语法规则覆盖有限、系统可迁移差等缺陷);基于统计(一套面向候选树的评价方法,其会给正确的句法树赋予一个较高的分值,而给不合理的句法树赋予一个较低的分值)
2、句法分析的数据集与评测方法
(1)句法分析的数据集
中文树库有中文宾州树库(CTB)、清华树库(TCT)、台湾中研院树库。其中CTB是目前绝大多数的中文句法分析研究的基准语料库。不同的树库有着不同的标记体系,使用时切记使用一种树库的句法分析器,然后用其它树库的标记体系来解释。
(2)句法分析的评测方法
①主要任务:测评句法分析器生成的树结构与手工标注的树结构之间的相似程度。主要考虑两方面的性能:满意度和效率。满意度是指测试句法分析器是否合适或胜任某个特定的nlp处理任务,效率主要用于对比句法分析器的运行时间。
②评测方法:目前主流的是PARSEVAL评测体系,主要指标有准确率、召回率、交叉括号数。准确率:分析正确的短语个数在句法分析结果中所占的比例;召回率表示分析得到的正确短语个数占标准分析树全部短语个数的比例;交叉括号表示分析得到的某一个短语的覆盖范围与标准句法分析结果的某个短语的覆盖范围存在重叠又不存在包含关系。
3、句法分析的常用方法
(1)基于PCFG的句法分析
PCFG是基于概率的短语结构分析方法。
PCFG是上下文无关文法的扩展,是一种生成式的方法,其短语结构文法可以表示为一个五元组(X,V,S,R,P)
①X是一个有限词汇的集合(词典),它的元素称为词汇或终结符。
②V是一个有限标注的集合,称为非终结符集合
③S称为文法的开始符号,其包含于V
④R是有序偶对(α,β)的集合,也就是产生的规则集
⑤P代表每个产生规则的统计概率
PCFG可以解决以下问题:
①基于PCFG可以计算分析树的概率值
②若一个句子有多个分析树,可以依据概率值对所有分析树进行排序
③PCFG可以用来进行句法排歧,面对多个分析结果选择概率值最大的
(2)基于最大间隔马尔可夫网络的句法分析
最大间隔马尔可夫网络能够解决复杂的结构化问题,尤为适合用于句法分析任务。这是一种判别式的句法分析方法,通过丰富特征来消解分析过程中产生的歧义。
(3)基于CRF的句法分析
与PCFG相比,采用CRF模型进行分析,主要不同点在于概率的计算方法和概率归一化的方式。CRF模型最大化的是句法树的条件概率值而不是联合概率值,并且对概率进行归一化。基于CRF的句法分析也是一种判别式的方法,需要融合大量的特征。
(4)基于移进-归约的句法分析模型
基于移进-归约方法是一种自下而上的方法。其从输入串开始,逐步进行“归约”,直至归约到文法的开始符号。移进-归约算大类似于下推自动机的LR分析法,其操作的基本数据结构是堆栈。
主要涉及四种操作(S表示句法树的根节点)
①移进:从句子左端将一个终结符移到栈顶。
②归约:根据规则,将栈顶的若干个字符替换为一个符号。
③接受:句子中所有词语都已移进栈中,且栈中只剩下一个符号S,分析成功,结束。
④拒绝:句子中所有词语都已移进栈中,栈中并非只有一个符号S,也无法进行任何归约操作,分析失败,结束。
移进-归约的句法分析通常会出现冲突情况,一种是既可以移进又可以归约,还有一种是可以采用不同的规则进行归约。一般可通过引入规则、引入上下文以及缓冲区等方式进行改进。此方法用于分析中文时,其对词性非常敏感,常常需要和准确度较高的词性标注工具一块使用。
(5)使用Stanford Parser 的PCFG算法进行句法分析
Stanford Parser是斯坦福开发的开源句法分析器,是基于概率统计句法分析的一个java实现。该句法分析器目前提供了5个中文文法的实现。
主要有一下优点:
①是一个高度优化的概率上下文无关文法和词汇化依存分析器,又是一个词汇化上下文无关文法分析器。
②以权威的宾州树库作为分析器的训练数据,支持多种语言。
③提供了多样化的分析输出形式,除句法分析树输出外,还支持分词和词性标注、短语结构、依存关系等输出。
④内置了分词、词性标注、基于自定义树库的分析器训练等辅助工作。
⑤支持多种平台,封装了多种常用语言接口。
Stanford Parser的python封装是在nltk库中实现的,其主要针对英文,对中文支持较差,这里主要用nltk.parse中的Stanford模块。还需要下载Stanford Parser的jar包,主要有:stanford-parser.jar和stanford-parser-3.8.0-models.jar
例子:
# 分词
import jieba
from nltk.parse import stanford
import os
string = '他骑自行车去了菜市场。'
seg_list = jieba.cut(string, cut_all=False, HMM=True) # 使用精确模式进行分词
seg_str = ' '.join(seg_list) # 将词用空格切分后再重新拼接成字符串。Stanford_parser的输入是分词完后以空格隔开的句子
print(seg_str)
parser_path = 'D:/NLP/stanford_parser/stanford-parser-full-2018-10-17/stanford-parser.jar' # Stanford-parser的jar包
model_path = 'D:/NLP/stanford_parser/stanford-parser-full-2018-10-17/stanford-parser-3.9.2-models.jar' # 训练好的模型jar包
# 指定JDK路径
if not os.environ.get('JAVA_HOME'):
JAVA_HOME = 'C:/Program Files/Java/jdk1.8.0_161'
os.environ['JAVA_HOME'] = JAVA_HOME
# PCFG模型路径
pcfg_path = 'edu/stanford/nlp/models/lexparser/chinesePCFG.ser.gz'
parser = stanford.StanfordParser(path_to_jar=parser_path, path_to_models_jar=model_path, model_path=pcfg_path)
sentence = parser.raw_parse(seg_str)
for line in sentence:
print(line)
line.draw()分词效果为:
![]()
生成的句法树为:

句法树图形为:
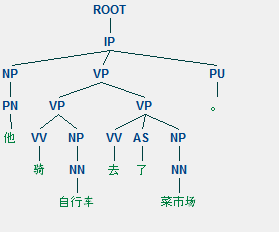
参考:《python自然语言处理实战 核心技术与算法》