加速python运行-numba
numba是一个用于编译Python数组和数值计算函数的编译器,这个编译器能够大幅提高直接使用Python编写的函数的运算速度。
numba使用LLVM编译器架构将纯Python代码生成优化过的机器码,通过一些添加简单的注解,将面向数组和使用大量数学的python代码优化到与c,c++和Fortran类似的性能,而无需改变Python的解释器。
Numba的主要特性:动态代码生成 (在用户偏爱的导入期和运行期)为CPU(默认)和GPU硬件生成原生的代码集成Python的科学软件栈(Numpy)下面是使用Numba优化的函数方法,将Numpy数组作为参数:
import numba
@numba.jit
def sum2d(arr):
M, N = arr.shape
result = 0.0
for i in range(M):
for j in range(N):
result += arr[i,j]
return result
如果你对此不是太感兴趣,或者对于其他的加速方案已经很熟悉,可以到此为止,只需要了解加上jit装饰器就可以实现了。
使用jit
使用jit的好处就在于让numba来决定什么时候以及怎么做优化。
from numba import jit
@jit
def f(x, y):
# A somewhat trivial example
return x + y
比如这段代码,计算将延期到第一次函数执行,numba将在调用期间推断参数类型,然后基于这个信息生成优化后的代码。numba也能够基于输入的类型编译生成特定的代码。例如,对于上面的代码,传入整数和复数作为参数将会生成不同的代码:
>>>f(1,2)
3
>>>f(1j,2)
(2+1j)
我们也可以加上所期望的函数签名:
from numba import jit, int32
@jit(int32(int32, int32))
def f(x, y):
# A somewhat trivial example
return x + y
int32(int32, int32) 是函数签名,这样,相应的特性将会被@jit装饰器编译,然后,编译器将控制类型选择,并不允许其他特性(即其他类型的参数输入,如float)Numba编译的函数可以调用其他编译函数。 函数调用甚至可以在本机代码中内联,具体取决于优化器的启发式。 例如:
@jit
def square(x):
return x ** 2
@jit
def hypot(x, y):
return math.sqrt(square(x) + square(y))
@jit装饰器必须添加到任何库函数,否则numba可能生成速度更慢的代码。
签名规范
Explicit @jit signatures can use a number of types. Here are some common ones:void is the return type of functions returning nothing (which actually return None when called from Python)
intp and uintp are pointer-sized integers (signed and unsigned, respectively)
intc and uintc are equivalent to C int and unsigned int integer types
int8, uint8, int16, uint16, int32, uint32, int64, uint64 are fixed-width integers of the corresponding bit width (signed and unsigned)
float32 and float64 are single- and double-precision floating-point numbers, respectively
complex64 and complex128 are single- and double-precision complex numbers, respectively
array types can be specified by indexing any numeric type, e.g. float32[:] for a one-dimensional single-precision array or int8[:,:] for a two-dimensional array of 8-bit integers.
编译选项
numba有两种编译模式:nopython模式和object模式。前者能够生成更快的代码,但是有一些限制可能迫使numba退为后者。想要避免退为后者,而且抛出异常,可以传递nopython=True.
@jit(nopython=True)
def f(x, y):
return x + y
当Numba不需要保持全局线程锁时,如果用户设定nogil=True,当进入这类编译好的函数时,Numba将会释放全局线程锁。
@jit(nogil=True)
def f(x, y):
return x + y
这样可以利用多核系统,但不能使用的函数是在object模式下编译。想要避免你调用python程序的编译时间,可以这顶numba保存函数编译结果到一个基于文件的缓存中。可以通过传递cache=True实现。
@jit(cache=True)
def f(x, y):
return x + y
开启一个实验性质的特性将函数中的这些操作自动并行化。这一特性可以通过传递parallel=True打开,然后必须也要和nopython=True配合起来一起使用。编译器将编译一个版本,并行运行多个原生的线程(没有GIL)
@jit(nopython=True, parallel=True)
def f(x, y):
return x + y
generated_jit
有时候想要编写一个函数,基于输入的类型实现不同的实现,generated_jit()装饰器允许用户在编译期控制不同的特性的选择。假定想要编写一个函数,基于某些需求,返回所给定的值是否缺失的类型,具体定义如下:
- 对于浮点数,缺失的值为NaN。
- 对于Numpy的datetime64和timedelta64参数,缺失值为NaT
- 其他类型没有定义的缺失值
import numpy as np
from numba import generated_jit, types
@generated_jit(nopython=True)
def is_missing(x):
"""
Return True if the value is missing, False otherwise.
"""
if isinstance(x, types.Float):
return lambda x: np.isnan(x)
elif isinstance(x, (types.NPDatetime, types.NPTimedelta)):
# The corresponding Not-a-Time value
missing = x('NaT')
return lambda x: x == missing
else:
return lambda x: False
有以下几点需要注意:
- 调用装饰器函数是使用Numba的类型作为参数,而不是他们的值。
- 装饰器函数并不真的计算结果,而是返回一个对于给定类型,可调用的实际定义的函数执行。
- 可以在编译期预先计算一些数据,使其在编译后执行过程中重用。
- 函数定义使用和装饰器函数中相同名字的参数,这将确保通过名字传递参数能够如期望的工作。
使用@vectorize 装饰器创建Numpy的 universal 函数
Numba的vectorize允许Python函数将标量输入参数作为Numpy的ufunc使用,将纯Python函数编译成ufunc,使之速度与使用c编写的传统的ufunc函数一样。
vectorize()有两种操作模型:
- 主动,或者装饰期间编译:如果传递一个或者多个类型签名给装饰器,就将构建Numpy的universal function。后面将介绍使用装饰期间编译ufunc。
- 被动(惰性),或者调用期间编译:当没有提供任何签名,装饰器将提供一个Numba动态universal function(DUFunc),当一个未支持的新类型调用时,就动态编译一个新的内核,后面的“动态 universal functions”将详细介绍
如上所描述,如果传递一个签名给vectorizer()装饰器,函数将编译成一个numpy 的ufunc:
from numba import vectorize, float64
@vectorize([float64(float64, float64)])
def f(x, y):
return x + y
如果想传递多个签名,注意顺序,精度低的在前,高的在后,否则就会出奇怪的问题。例如int32就只能在int64之前。
@vectorize([int32(int32, int32),
int64(int64, int64),
float32(float32, float32),
float64(float64, float64)])
def f(x, y):
return x + y
如果给定的类型正确:
>>> a = np.arange(6)
>>> f(a, a)
array([ 0, 2, 4, 6, 8, 10])
>>> a = np.linspace(0, 1, 6)
>>> f(a, a)
array([ 0. , 0.4, 0.8, 1.2, 1.6, 2. ])
如果提供了不支持的类型:
>>> a = np.linspace(0, 1+1j, 6)
>>> f(a, a)
Traceback (most recent call last):
File "", line 1, in
TypeError: ufunc 'ufunc' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''
vectorizer与jit装饰器的差别:numpy的ufunc自动加载其他特性,例如:reduction, accumulation or broadcasting:
>>> a = np.arange(12).reshape(3, 4)
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> f.reduce(a, axis=0)
array([12, 15, 18, 21])
>>> f.reduce(a, axis=1)
array([ 6, 22, 38])
>>> f.accumulate(a)
array([[ 0, 1, 2, 3],
[ 4, 6, 8, 10],
[12, 15, 18, 21]])
>>> f.accumulate(a, axis=1)
array([[ 0, 1, 3, 6],
[ 4, 9, 15, 22],
[ 8, 17, 27, 38]])
vectorize() 装饰器支持多个ufunc 目标:
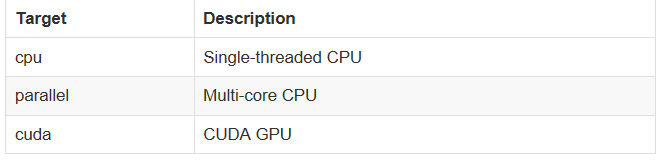
guvectorize装饰器只用了进一步的概念,允许用户编写ufuncs操作输入数组中的任意数量的元素,返回不同纬度的数组。典型的应用是运行求均值或者卷积滤波。
Numba支持通过jitclass装饰器实现对于类的代码生成。可以使用这个装饰器来标注优化,类中的所有方法都被编译成nopython function。
import numpy as np
from numba import jitclass # import the decorator
from numba import int32, float32 # import the types
spec = [
('value', int32), # a simple scalar field
('array', float32[:]), # an array field
]
@jitclass(spec)
class Bag(object):
def __init__(self, value):
self.value = value
self.array = np.zeros(value, dtype=np.float32)
@property
def size(self):
return self.array.size
def increment(self, val):
for i in range(self.size):
self.array[i] = val
return self.array
转载:https://www.jianshu.com/p/69d9d7e37bc5