Hadoop生态圈(四):Yarn
目录
1 Yarn
1.1 Yarn概述
1.2 Yarn基本结构
1.3 Yarn工作机制
1.4 资源调度器
2 hadoop企业优化
2.1 MapReduce跑的慢的原因
2.2 MapReduce优化方法
2.2.1 数据输入
2.2.2 Map阶段
2.2.3 Reduce阶段
2.2.4 数据倾斜问题
3 常见错误及解决方案
1 Yarn
1.1 Yarn概述
Yarn是一个资源调度平台,负责为运算程序调度服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序相当于运算在操作系统上的应用程序
1.2 Yarn基本结构
Yarn主要有ResourceManager、NodeManager、ApplicationMaster和Container等组件构成

1) ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
1.3 Yarn工作机制
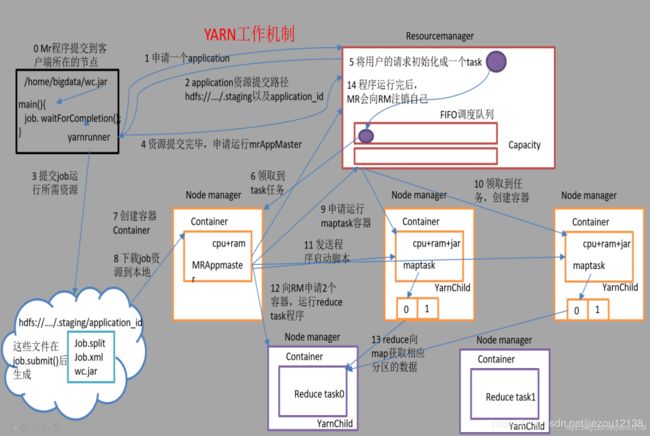
工作机制详细流程:
- 先将MR程序提交到客户端所在节点,准备运行MR
- Yarnrunner向ResourceManager申请启动一个Application
- RM将该应用程序所需要的资源路径返回给yarnrunner
- 该程序将运行所需要的资源信息提及到HDFS上
- 程序资源信息提交完毕之后,申请运行MrApplicationMaster
- RM将及用户的请求初始化为一个task放入任务队列中
- 一个NodeManager领取到task任务
- 该NodeManager节点创建容器Container,并产生一个MrApplicationMaster
- Container从HDFS上将该task'所需要的资源信息拷贝到本地
- MrApplicationMaster向RM申请运行maptask所需要的资源
- MR将运行maptask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务创建Container容器
- MrApplicationMaster向两个接受到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动maptask,maptask对数据进行处理
- MrApplicationMaster等所有的maptask运行完毕之后,向RM申请容器、资源,运行reduce task
- reduce task 向maptask获取对应的分区的数据
- 程序运行完毕之后。MR向RM申请注销
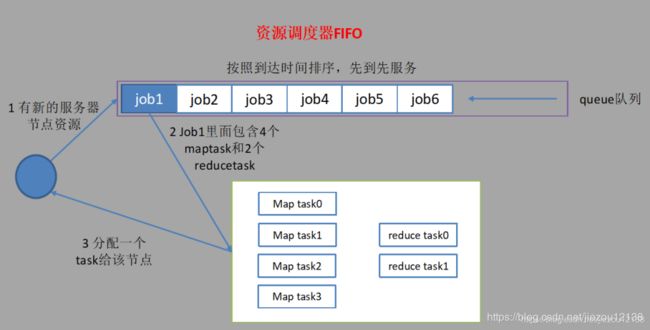
1.4 资源调度器
目前,Hadoop作业调度器主要有三种:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop2.7.2默认的资源调度器是Capacity Scheduler。具体设置详见:yarn-default.xml
The class to use as the resource scheduler.
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
1. 先进先出调度器(FIFO)
2. 容量调度器(Capacity Scheduler)

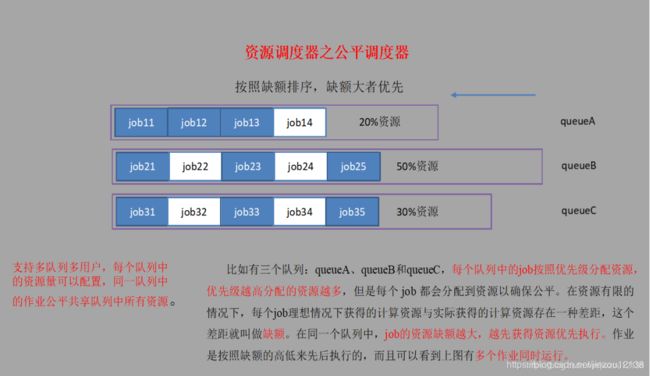
3. 公平调度器(Fair Scheduler)
2 hadoop企业优化
2.1 MapReduce跑的慢的原因
Mapreduce 程序效率的瓶颈在于两点:
1.计算机性能
CPU、内存、磁盘健康、网络
2.I/O 操作优化
(1)数据倾斜
(2)map和reduce数设置不合理 combineTextinputformat,分区
(3)map运行时间太长,导致reduce等待过久
(4)小文件过多
(5)spill(溢出)次数过多,溢出数据到磁盘,
(6)merge次数过多等。Shuffule,溢出之后会有合并,reduce端也会有合并
2.2 MapReduce优化方法
MapReduce优化方法主要从六个方面考虑:数据输入、Map阶段、Reduce阶段、IO传输、数据倾斜问题和常用的调优参数。
2.2.1 数据输入
(1)合并小文件:在执行mr任务前将小文件进行合并,大量的小文件会产生大量的map任务,大量节点资源被占用,从而导致mr整体运行较慢。
(2)采用CombineTextInputFormat来作为输入,解决输入端大量小文件场景。
2.2.2 Map阶段
1)减少溢写(spill)次数:通过调整io.sort.mb及sort.spill.percent参数值(在mapred-default.xml),增大触发spill的内存上限,减少spill次数,从而减少磁盘IO。
2)减少合并(merge)次数:通过调整io.sort.factor参数(在mapred-default.xml),增大merge的文件数目,减少merge的次数,从而缩短mr处理时间。
3)在map之后,不影响业务逻辑前提下,先进行combine处理,减少 I/O。
2.2.3 Reduce阶段
1)合理设置map和reduce数:两个都不能设置太少,也不能设置太多。太少,会导致task等待,延长处理时间;太多,会导致 map、reduce任务间竞争资源,造成处理超时等错误。
2)设置map、reduce共存:调整slowstart.completedmaps参数,使map运行到一定程度后,reduce也开始运行,减少reduce的等待时间。
3)合理设置reduce端的buffer:默认情况下,数据达到一个阈值的时候,buffer中的数据就会写入磁盘,然后reduce会从磁盘中获得所有的数据。也就是说,buffer和reduce是没有直接关联的,中间多一个写磁盘->读磁盘的过程,既然有这个弊端,那么就可以通过参数来配置,使得buffer中的一部分数据可以直接输送到reduce,从而减少IO开销:mapred.job.reduce.input.buffer.percent,默认为0.0。当值大于0的时候,会保留指定比例的内存读buffer中的数据直接拿给reduce使用。这样一来,设置buffer需要内存,读取数据需要内存,reduce计算也要内存,所以要根据作业的运行情况进行调整。
2.2.4 数据倾斜问题
1.数据倾斜现象
数据频率倾斜——某一个区域的数据量要远远大于其他区域。
2.如何收集倾斜数据
在reduce方法中加入记录map输出键的详细情况的功能。
public static final String MAX_VALUES = "skew.maxvalues";
private int maxValueThreshold;
@Override
public void configure(JobConf job) {
maxValueThreshold = job.getInt(MAX_VALUES, 100);
}
@Override
public void reduce(Text key, Iterator values,
OutputCollector output,
Reporter reporter) throws IOException {
int i = 0;
while (values.hasNext()) {
values.next();
i++;
}
if (++i > maxValueThreshold) {
log.info("Received " + i + " values for key " + key);
}
} 3.减少数据倾斜的方法
方法1:自定义分区
基于输出键的背景知识进行自定义分区。例如,如果map输出键的单词来源于一本书。且其中某几个专业词汇较多。那么就可以自定义分区将这这些专业词汇发送给固定的一部分reduce实例。而将其他的都发送给剩余的reduce实例。
方法2:Combine
使用Combine可以大量地减小数据倾斜。在可能的情况下,combine的目的就是聚合并精简数据。
方法3:采用Map Join,尽量避免Reduce Join。
3 常见错误及解决方案
1) 导包容易出错。尤其Text和CombineTextInputFormat。
2) Mapper中第一个输入的参数必须是LongWritable或者NullWritable,不可以是IntWritable. 报的错误是类型转换异常。
3) java.lang.Exception: java.io.IOException: Illegal partition for 13926435656 (4),说明partition和reducetask个数没对上,调整reducetask个数。
4) 如果分区数不是1,但是reducetask为1,是否执行分区过程。答案是:不执行分区过程。因为在maptask的源码中,执行分区的前提是先判断reduceNum个数是否大于1。不大于1肯定不执行。
5)在Windows环境编译的jar包导入到linux环境中运行,
hadoop jar wc.jar com.bigdata.mapreduce.wordcount.WordCountDriver /user/bigdata/ /user/bigdata/output
报如下错误:
Exception in thread "main" java.lang.UnsupportedClassVersionError: com/bigdata/mapreduce/wordcount/WordCountDriver : Unsupported major.minor version 52.0
原因是Windows环境用的jdk1.7,linux环境用的jdk1.8。
解决方案:统一jdk版本。
6)缓存pd.txt小文件案例中,报找不到pd.txt文件
原因:大部分为路径书写错误。还有就是要检查pd.txt的问题。还有个别电脑写相对路径找不到pd.txt,可以修改为绝对路径。
7)报类型转换异常。
通常都是在驱动函数中设置map输出和最终输出时编写错误。Map输出的key如果没有排序,也会报类型转换异常。
8)集群中运行wc.jar时出现了无法获得输入文件。
原因:wordcount案例的输入文件不能放在hdfs集群的根目录。