【转】GANs学习系列(9):DCGAN对抗卷积神经网络总结
reference: http://blog.csdn.NET/u013139259/article/details/53590536
所谓的对抗网络可以归结为unsupervised learning 或者 generative model。从无监督学习来进行feature representation,有k-means聚类算法,auto-encoders[2],以及09年的Deep belief networks等等。从生成模型的角度来说,我们需要让算法能学习到数据的分布情况,而这个分布从Bayes观点来说,可以认为是class-conditional probability。然而对于复杂的数据,例如高分辨率的图像,学习到它的像素的分布情况是个极其困难的问题。所以,对于生成natural images,之前的算法一直没有取得好的效果。最近的一些算法就基本解决了这个问题,比如variational autoencoder[3],简称VAE.以及我们介绍过的adversarial networks[4]。Good fellow 14年提出的对抗网络,应该没有想到它现在会这么火爆。
对抗网络可以认为是一个生成模型和一个判别模型组成的。一般情况下,生成模型和判别模型都是使用的神经网络的算法,比如感知器,或者卷积神经网络。对于对抗网络,经过所谓的对抗过程的训练之后,Generative networks可以生成realistic image,接近于训练图片,但又不完全一样。所以,生成网络是学习了一个训练数据的近似分布。对于判别网络也能进行训练数据的很好的区分,比如Classify。DCGAN论文中有一个贡献就是将disciminator用于feature extractor,然后加了个l2-svm,进行分类,取得了不错的效果,而且又通过“反卷积”可视化[5],通过观察,的确学到了很明显物体结构特征。
DCGAN是将卷积神经网络和对抗网络结合起来的一篇经典论文[19]。其中作者之一是Facebook AI Rearch 的 Soumith Chintala。他和他团队发表了几篇重要的相关论文。Soumith 的github地址为[6],在youtube的关于GANs的演讲地址为[7].
(如果要从事这方面的研究,一定要关注该人的动态)。
本博文主要内容如下:
1)先介绍DCGAN
2)然后介绍下我的开源项目
3)在从理论上介绍生成模型
4)详细介绍DCGAN的架构和实验
5)介绍有条件的DCGAN网络
6)分析GANs的未来。
二.DCGAN的介绍
从上一篇博文了解到,对抗网络是由一个判别模型和生成模型组成。网络结构大致如下图。
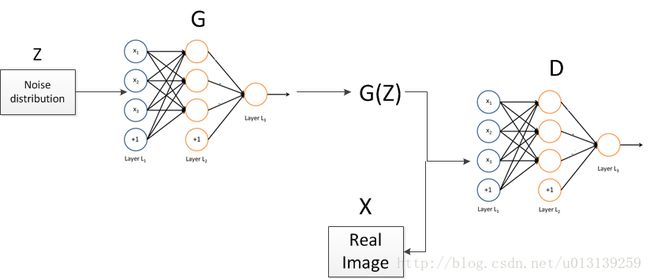
G代表生成模型,D代表判别模型。G和D的对抗过程可以认为一个假币制造者和银行柜员的对抗:银行柜员(D)不断的学习假币和真币之间的区别来预防假币制造者(G),而假币制造者也不断学习真币的样貌,制造假币,以欺骗银行柜员。
那对于基于神经网络的gan,其中的大致学习过程如下。
Z是噪声,也就是G的输入,可以是高斯噪声,一般为均匀噪声;
经过G之后生成 fake image ——G(z),然后将G(z)和X作为D的输入,最后的D的输出表示该数据为real的可能性,该值范围0-1。至于更详细的参看上一篇博文或者其他资料。
Gans的大致情况如上文所说,其中DCGAN就是基于convnets的Gans,其他没有什么差别。在DCGAN中,G的网络结构是需要进行up-sample , 所以使用的“de-convolution”层,而对于D则是比较普遍的卷基层进行下采样。
三.项目的实现
本节介绍下我根据本文实现的开源项目Condition-Gans(Tensorflow)。
https://github.com/zhangqianhui/Conditional-Gans
关于DCGAN,github很多版本的实现,那博主实现的其实是condition-dcgan,也就是有条件的卷积对抗网络,不同于原paper。2014年的一篇论文《Conditional Generative Adversarial Nets》[8],第一次提出了有条件的对抗网络,通过label,来指定生成图片的输出。但是论文并没有提供代码,所以,博主就在DCGAN上进行来小小的改进,所以也就有了Condition-Gans。做这个项目,主要为了以后的对抗网络的研究用,现在只是一个在mnist数据集上的初始版本。当然,博主提供了测试代码和可视化的代码,其中可视化是基于对权重和激活值的输出的,代码借鉴于Caffe,关于可视化的原理,附录会进行简单介绍。
四.生成模型之理论分析
本节主要介绍生成模型和判别模型的区分,以及生成模型的实质和当前生成模型算法。
我们根据对后验概率P(y|x)的建模方式将机器学习的学习方法分为两类。一类是判别模型,一类是生成模型。判别模型的话是直接对P(y|x)进行建模,所以学习的是条件概率。条件概率可以理解为给定x,y的概率,根据y的大小来判定类别,这也解释了判别模型名字的含义。
对于生成模型的话,我们说他学习的是联合概率P(x,y)。通过Bayes理论,联合概率转化为后验概率,进行间接建模。
我们知道。
然后Bayes公式为:
得到
该式子给我们的启发就是所谓的联合概率就是先验概率和类条件概率的乘积,而求联合概率的目标则转化为求类条件概率(先验概率很容易获取到)。类条件概率表达了在某一类的基础上样本的分布情况,那式子也就体现了数据的真实分布。所以,我们可以通过类条件概率做数据生成的事情,这也许就是学习联合概率叫做生成模型的原因。
当然,关键就是求类条件概率,实际上这个分布是很难学习到的。如果以图像作为样本的话,那学习到图像的像素的分布是很困难的,所以图像生成是机器学习中的一个难题。
从贝叶斯的角度上做,生成模型可以认为是都是属于ML(最大化似然)的过程,因为,ML就是找到能使样本数据的类条件概率最大化的分布参数。那如果经过训练集训练,我们找到该参数,此时我们的模型是有最大可能生成和样本训练数据具有同样分布的数据,这个也是生成模型的一个目标。当然这个方法的前提就是对数据的分布进行一个假设,然后才能求参数。比如假设数据分布是符合高斯分布的。
那么数据的分布,也就是类条件概率,对其获取方式进行分类,可以分为,Explict density 和 Implict density。当然,对抗网络自然是implict。不需要显示建立密度函数,也是Gans的一大优点。
生成模型的类别图标(来自Good fellow NIPS slides[9])。
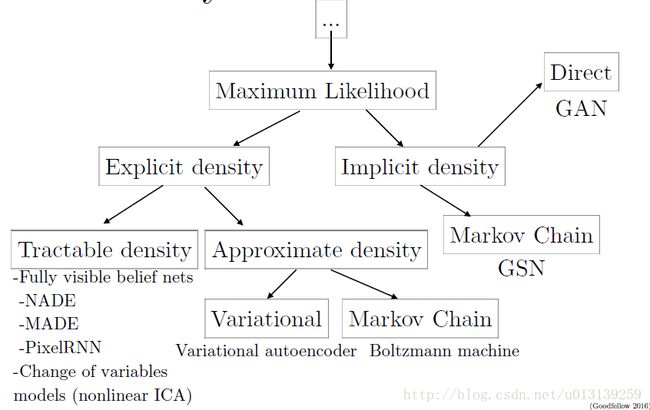
从图表中,可以看到我们上文介绍的Gan的分类。当然,最近比较火热的生成模型,还有Variational autoencoder。关于其中的细节,博主也不是非常清楚。如果有人了解,请留言。
五.对抗网络之优劣
先说个人的想法。从上文图表中,我们了解到,Gans是一个Implict的建立学习密度函数过程,减少了人为的建模,这是Gans的一个优点。当然,论文也提到的在训练过程中不需要建立Markov Chain以及复杂的Inference。
那缺点的话,就是很难稳定训练。DCGAN的一个contribution就是提高了原始论文Gans的稳定性。
Gans的训练的目标并不和传统的神经网络算法目标类似,去最小化loss,
GoodFellow的论文证明了Gans 全局最小点的充分必要条件是:
pg表示generate 生成数据的分布函数
pdata表示真实data的分布函数
在训练过程中,pg不断地接近pdata,是收敛的判断标准。
我们知道,G和D是一个对抗的过程,而这个对抗是,G不断的学习,D也不断的学习,而且需要保证两者学习速率基本一致,也就是都能不断的从对方那里学习到“知识”来提升自己。否则,就是这两者哪一个学习的过快,或过慢,以至于双方的实力不再均衡,就会导致实力差的那一方的“loss”不再能“下降”,也就不在学到“知识”。一般的对抗模型中的G和D的网络框架大小基本上是相似(可能存在较小的差异),而且,训练的过程就是先训练G一次,再训练D一次,这也是为了稳定训练的一个保证。当然这并不能完全稳定训练,所以,对抗网络的稳定训练,依然是一个研究的热点和方向。
还有就是对抗网络当然依然很难生成分辨率大的但又不blurry的图片。从理论上来说也是很困难的事情,所以这个也是一个研究的目标。
关于对抗网络其他的优劣,,以后会接着研究和添加。
六.DCGAN的的特点
相对于最原始的Gans,DCGAN的一大特点就是使用了卷积层。细节点说,我们分节讨论。
6.1 Generative networks的架构
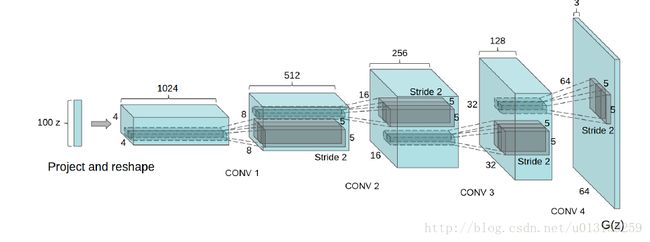
这是DCGAN的生成网络模型的架构,对于LSUN,Imagenet-1k大小的数据集,我们可以使用这个架构,但并不是说对于任何数据集,都可以,比如,更大,或者更小的,那对应的卷积架构就需要进行改变。比如,对于mnist数据集,G和D的网络架构都相应地减小了,否则不能拟合,产生不了好的结果(亲测)。
那对于判别模型的话,就是5层卷积层网络。对与生成模型的,我们可以看到,从开始的Noise采样100维度,到最后生成了64x64x3的图片,经过了“de-convolution”层,实质是transport convolution 或者up-sampling convolution。下一节介绍下什么是反卷积层。
6.2“反卷积”—上采样卷积
关于卷积和反卷积的介绍,请查看我的博文[10]。本节详细介绍下反卷积的由来。
反卷积,英文decovolution。根据wiki的定义,其实是对卷积的逆向操作,也就是通过将卷积的输出信号,经过反卷积可以还原卷积的输入信号,还原的不仅仅是shape,还有value。
但是深度学习中的所讲的反卷积实质是transport convolution。只是从2010年一篇论文[11]将其叫做了deconvolution,然后才有了这个名字。
先看下卷积的可视化(图片来源conv_arithmetic[12]):
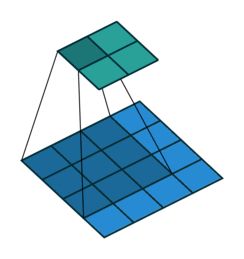
4x4的输入信号,经过3x3 的filters,产生了2x2的feature map。
那什么是transport-convolution?
可视化:
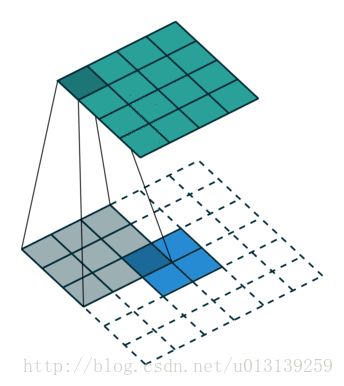
2x2的输入信号,经过3x3 的filters,产生了4x4的feature map。从小的维度产生大的维度,所以transport-convolution又称为上采样卷积。
那为什么叫做transport(转置)?
因为“反卷积”存在于卷积的反向传播中。其中反向传播的滤波器矩阵,是前向传播(卷积)的转置,所以,这就是它的名字的由来。只不过我们把反向传播的操作拿到了前向传播来做,就产生了所谓的反卷积一说。但是transport-convolution只能还原信号的大小,不能还原其value,所以,不能叫做反卷积,不是真正的逆操作。
6.3 用到的其他Trick
(1)比如D用的是lrelu激活函数,G用的是relu
(2)使用batch_normalization.
(3)去掉了pooling层,使用stride-convolution(也就是stride=2)
(4)学习率必须很小,比如论文中,rate=0.0002
七.DCGAN的实验
7.1 DCGAN之论文中的实验
LSUN 数据集的训练:

还有就是将训练好的discrimination networks用于特征提取,然后分类,和其他一些无监督的效果进行了比对,效果还不错,这个可以从论文中可以查看到。
将判别网络用于特征提取,然后进行分类,也是一个研究方向。因为既然判别网络可以学习到不同类之间的boundary,那么将其用于分类,与其他的无监督,或者半监督算法进行比较,如果效果好的话,那也是一个改进。
7.2 DCGAN中的VECTOR ARITHMETIC ON FACE SAMPLES(特征表示的向量运算)
我们先看论文中的实验结果:

具体什么意思?
上图等式左边都是噪声z(一般为均匀噪声)经过G(z)产生的人脸图片。
我们记
戴眼镜的男性的原始输入 z为
z1
同理,不带眼镜的男性:
z2
同理,不戴眼镜的女性:
z3
记:
z4= z1- z2+ z3
那么的产生的图片为:戴眼镜的女性。神奇!
所以,训练好的生成模型G,在特征表示空间具有算式属性。很神奇!
7.3 DCGAN之我的测试
我对自己编写的代码也进行了一些测试,修改了一些参数。得到的启发如下。
(1)如果模型太大,则会出现训练不稳定。
什么是模型过大,模型过大是同样大小的数据集的分类任务情况下,比监督训练的模型较大,如果较大的话,会出现,生成图片的不稳定。主要体现就是生成的图片,在开始的时候又趋于变优的过程,最后却变得越来越blurry。
(2)采样的噪声如果为10时,和100有和区别。
发现,采样噪声维度的越小,产生的图片的共性越大。
(3)将测试采样进行变动,发现高斯和均匀分布采样基本兼容,其他是乱的。
(4)训练G和D的顺序似乎没有什么关系。(值得思考)
八.DCGAN的改进
8.1 conditional GANS介绍
论文[13]第一次提出了Conditional gans的想法,主要思想是通过label值来引导生成模型的输出,比如我们给label=0,那对于mnist,也同样输出表示0的图片。
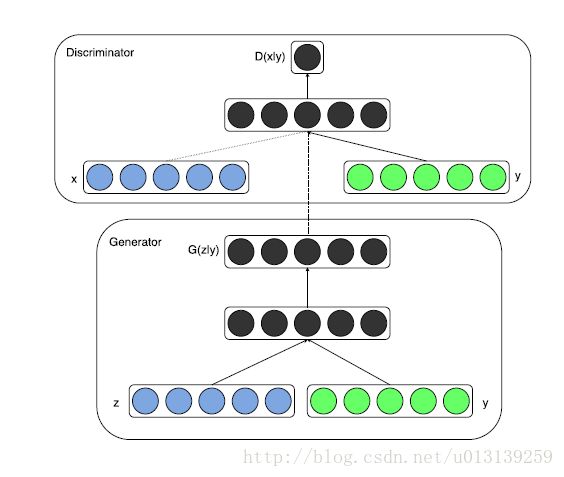
从模型架构上可以看出,我们的G的输入不再是具有一定维度的Noisy —— z,而是z 和y1。对于D的话,输入也不再是real image——x,而是 x和y2。
其中y=y1=y2,表示,是同样的标签,也意味这通过label——y将z和x联系起来,y起到连接或者区分的作用。
那对抗的目标函数为:
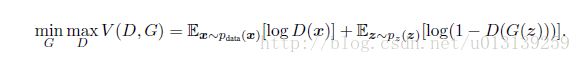
8.2 conditional DCGAN
了解了condtional gans,自然,conditional dcgan就很清楚了,只不过是网络模型使用了卷积等。博主的开源项目做的就是conditonal dcgan,不同于原文,不过从实验结果上看,结果更加真实。
8.3 实验结果
1)mnist的训练结果(无条件的)
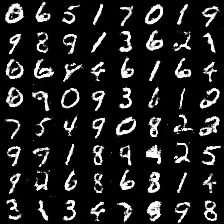
2)mnist训练的结果(有条件的):
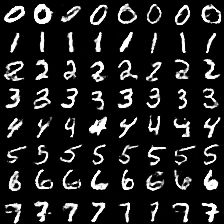
我们来看下可视化的效果
可视化权重:

可视化激活值:

九.未来的发展
无论是GANs还是DCGAN,这种对抗学习的方式,是一种比较成功的生成模型,可以从训练数据中学习到近似的分布情况,那么有了这个分布,自然可以应用到很多领域,比如,图像的修复[14],图像的超分辨率[15],图像翻译[16]。
接下来,博主谈下未来的发展趋势。
(1) conditional GANs
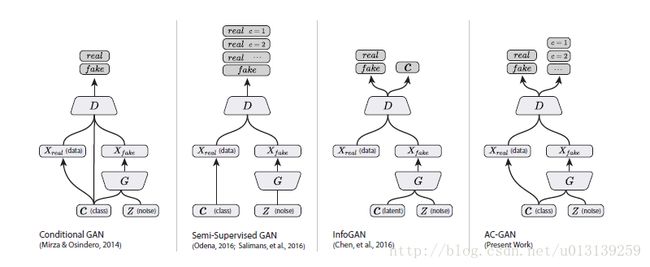
上图是最近几篇关于conditional gans的不同的架构,那通过给输入添加限制,来引导学习过程,最后产生更realistic 的结果。而且,有条件的应用更广泛。
(2)Video predict
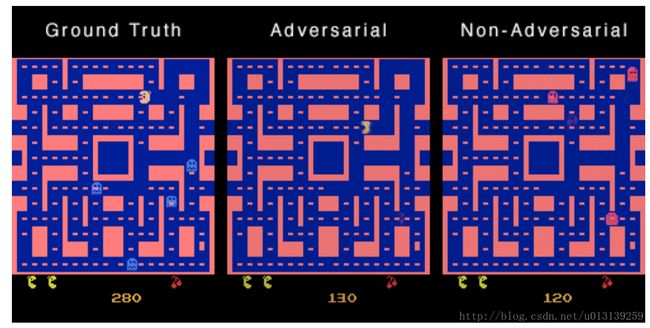
视频预测大致是通过前几帧来预测未来帧。关于视频预测,Lecun做了一篇[17],Goodfellow 做了一篇[18],大牛都在做,看来还是很有前途的。
(3) Image to Image translation
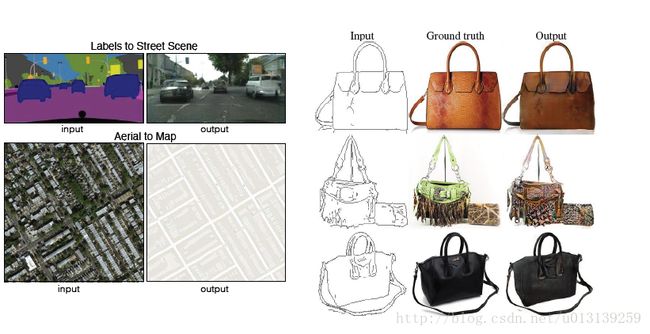
输入一张图片,生成另一种风格的图片。有几篇论文是做的关于Image translation[16]。博主认为这个也是一个不错的方向。比如由上图,通过缩略图生成完整风格的图,在现实生活中就存在着很大的应用意义。
附录:
可视化的介绍
深度学习的参数可视化是了解深度学习的学习过程或者结果的方法或者工具。那一般分为三种方法。
1.权重可视化
这个比较直观,一般都是对卷积权重进行可视化。
操作流程:直接取参数,然后进行一定的归一化,然后转化为RGB图片。
2.激活值可视化
这个是对激活函数的输出进行可视化,那么就需要进行NN的前向传播。
操作流程:先进行前向传播,去某一层的激活值,然后进行归一化,最后转化为RGB图片。
3.反卷积的可视化
这篇论文介绍的可视化,是需要经过训练,然后经过反卷积(反卷积层+反pooling层),的输出值的可视化。详细的请看论文。
引用
[1]http://blog.csdn.net/u013139259/article/details/52729191
[2] Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion
[3] https://arxiv.org/abs/1312.6114
[4]GoodFellow.Generative adversarial network
[5] Zeiler.Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014
[6] https://github.com/soumith
[7] https://www.youtube.com/watch?v=QPkb5VcgXAM&t=22s
[8] Meghdi Mirza《Conditional Generative Adversarial Nets》.2014
[9] http://www.iangoodfellow.com/slides/2016-12-04-NIPS.pdf
[10] http://blog.csdn.net/u013139259/article/details/52729191
[11] http://www.matthewzeiler.com/pubs/cvpr2010/cvpr2010.pdf
[12]https://github.com/vdumoulin/conv_arithmetic
[13]Medhi Mirza.Conditional Generative Adversarial Nets
[14]Semantic Image Inpainting with Perceptual and Contextual Losses
[15] Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
[16] Image-to-image translation using conditional adversarial nets
[17] Lecun.Deep multi-scale video prediction beyond mean square error
[18]GoodFellow. Unsupervised Learning for Physical Interaction through Video Prediction
[19]Alec Radford.Unsupervised representation learning with deep convolutional generative adversarial networks.