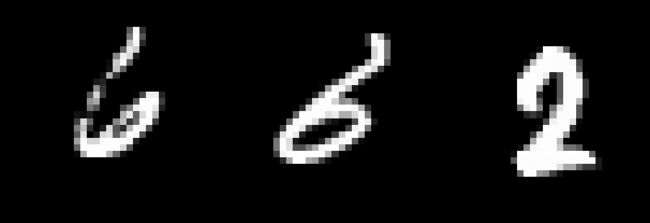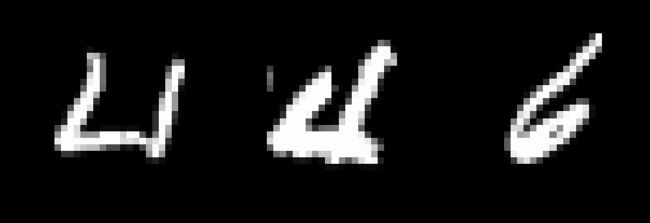Pytorch搭建FaceNet并应用于mnist
文章目录
- FaceNet
- triplet loss
- resnet-18 for triplet loss
- 小测试
- triplet dataloader
- train function for triplet loss
- test function for triplet loss
- 训练与测试
FaceNet
用triplet loss训练一个resnet18网络,并用这个网络在mnist数据集上进行KNN分类,具体的,resnet18相当于一个特征提取器,用所有的训练集图片的特征拟合一个KNN分类器,利用这个KNN分类进行预测。
embedding size
facenet的作用是将图像嵌入一个d维的空间,在这个d维空间里,同一类图像的特征之间相隔的近,不同类图像的特征之间相隔的远,这个d我们称之为embedding size,可以理解成是一个向量的维度。
triplet loss
-
lp公式:
L p ( x i , x j ) = ( ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ p ) 1 p L_p(x_i, x_j) = \left( \sum_{l=1}^{n} | x_i^{(l)} - x_j^{(l)} |^p \right)^{\frac{1}{p}} Lp(xi,xj)=(l=1∑n∣xi(l)−xj(l)∣p)p1 -
triplet loss公式:

-
torch.clamp(input, min, max, out=None) → Tensor
-
将输入input张量每个元素的夹紧到区间[min,max],并返回结果到一个新张量。
- input (Tensor) – 输入张量
- min (Number) – 限制范围下限
- max (Number) – 限制范围上限
- out (Tensor, optional) – 输出张量
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.backends.cudnn as cudnn
import os
import torchvision
import torchvision.transforms as transforms
from torch.autograd import Variable,Function
class PairwiseDistance(Function):
'''
compute distance of the embedding features, p is norm, when p is 2, then return L2-norm distance
'''
def __init__(self, p):
super(PairwiseDistance, self).__init__()
self.norm = p
def forward(self, x1, x2):
eps = 1e-6 # in case of zeros
diff = torch.abs(x1 - x2) # subtraction
out = torch.pow(diff, self.norm).sum(dim=1) # square
return torch.pow(out + eps, 1. / self.norm) # L-p norm
class TripletLoss(Function):
'''
Triplet loss function.
这里的margin就相当于是公式里的α
loss = max(diatance(a,p) - distance(a,n) + margin, 0)
forward method:
args:
anchor, positive, negative
return:
triplet loss
'''
def __init__(self, margin, num_classes=10):
super(TripletLoss, self).__init__()
self.margin = margin
self.num_classes = num_classes
self.pdist = PairwiseDistance(2) # to calculate distance
def forward(self, anchor, positive, negative):
d_p = self.pdist.forward(anchor, positive) # distance of anchor and positive
d_n = self.pdist.forward(anchor, negative) # distance of anchor and negative
dist_hinge = torch.clamp(self.margin + d_p - d_n, min=0.0) # ensure loss is no less than zero
loss = torch.mean(dist_hinge)
return loss
resnet-18 for triplet loss
class BasicBlock(nn.Module):
'''
resnet basic block.
one block includes two conv layer and one residual
'''
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNetTriplet(nn.Module):
def __init__(self, block, num_blocks, embedding_size=256, num_classes=10):
super(ResNetTriplet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
# feature map size 32x32
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
# feature map size 32x32
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
# feature map size 16x16
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
# feature map size 8x8
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
# feature map size 4x4
# as we use resnet basic block, the expansion is 1
self.linear = nn.Linear(512*block.expansion, embedding_size)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def l2_norm(self,input):
input_size = input.size()
buffer = torch.pow(input, 2)
normp = torch.sum(buffer, 1).add_(1e-10)
norm = torch.sqrt(normp)
_output = torch.div(input, norm.view(-1, 1).expand_as(input))
output = _output.view(input_size)
return output
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
# normalize the features, then we set margin easily
self.features = self.l2_norm(out)
# multiply by alpha = 10 as suggested in https://arxiv.org/pdf/1703.09507.pdf
alpha = 10
self.features = self.features * alpha
# here we get the 256-d features, next we use those features to make prediction
return self.features
def ResNet18(embedding_size=256, num_classes=10):
return ResNetTriplet(BasicBlock, [2,2,2,2], embedding_size, num_classes)
小测试
def l2_norm(input):
input_size = input.size()
buffer = torch.pow(input, 2)
print(buffer.shape)
normp = torch.sum(buffer, 1).add_(1e-10)
print(normp.shape)
norm = torch.sqrt(normp)
print(norm.shape)
_output = torch.div(input, norm.view(-1, 1).expand_as(input))
print(norm.view(-1, 1).expand_as(input))
print(_output.shape)
output = _output.view(input_size)
a = torch.randn(4,8)
l2_norm(a)
torch.Size([4, 8])
torch.Size([4])
torch.Size([4])
tensor([[2.9941, 2.9941, 2.9941, 2.9941, 2.9941, 2.9941, 2.9941, 2.9941],
[3.0485, 3.0485, 3.0485, 3.0485, 3.0485, 3.0485, 3.0485, 3.0485],
[2.9837, 2.9837, 2.9837, 2.9837, 2.9837, 2.9837, 2.9837, 2.9837],
[2.1227, 2.1227, 2.1227, 2.1227, 2.1227, 2.1227, 2.1227, 2.1227]])
torch.Size([4, 8])
triplet dataloader
np.random.choice用法解读:
np.random.choice(a=5, size=3, replace=False, p=None)
从a 中以概率P,随机选择3个, p没有指定的时候相当于是一致的分布
np.random.choice(a=5, size=3, replace=False, p=[0.2, 0.1, 0.3, 0.4, 0.0])
非一致的分布,会以多少的概率提出来,replacement 代表的意思是抽样之后还放不放回去,如果是False的话,那么出来的三个数都不一样,如果是
True的话,有可能会出现重复的,因为前面的抽的放回去了。
import numpy as np
import pandas as pd
import torch
from PIL import Image
from torch.utils.data import Dataset
class TripletFaceDataset(Dataset):
def __init__(self, root_dir, csv_name, num_triplets, transform = None):
'''
randomly select triplet,which means anchor,positive and negative are all selected randomly.
args:
root_dir : dir of data set
csv_name : dir of train.csv
num_triplets: total number of triplets
'''
self.root_dir = root_dir
self.df = pd.read_csv(csv_name)
self.num_triplets = num_triplets
self.transform = transform
self.training_triplets = self.generate_triplets(self.df, self.num_triplets)
@staticmethod
def generate_triplets(df, num_triplets):
def make_dictionary_for_pic_class(df):
'''
make csv to the format that we want
- pic_classes = {'class0': [class0_id0, ...], 'class1': [class1_id0, ...], ...}
建立类名与id一一对应的一个字典
'''
pic_classes = dict()
for idx, label in enumerate(df['class']):
if label not in pic_classes:
pic_classes[label] = []
pic_classes[label].append(df.iloc[idx, 0])
return pic_classes
triplets = []
classes = df['class'].unique()
pic_classes = make_dictionary_for_pic_class(df)
for _ in range(num_triplets):
'''
- randomly choose anchor, positive and negative images for triplet loss
- anchor and positive images in pos_class
- negative image in neg_class
- at least, two images needed for anchor and positive images in pos_class
- negative image should have different class as anchor and positive images by definition
'''
pos_class = np.random.choice(classes) # random choose positive class
neg_class = np.random.choice(classes) # random choose negative class
while len(pic_classes[pos_class]) < 2:
pos_class = np.random.choice(classes)
while pos_class == neg_class:
neg_class = np.random.choice(classes)
pos_name = df.loc[df['class'] == pos_class, 'name'].values[0] # get positive class's name
neg_name = df.loc[df['class'] == neg_class, 'name'].values[0] # get negative class's name
if len(pic_classes[pos_class]) == 2:
ianc, ipos = np.random.choice(2, size = 2, replace = False)
else:
ianc = np.random.randint(0, len(pic_classes[pos_class])) # random choose anchor
ipos = np.random.randint(0, len(pic_classes[pos_class])) # random choose positive
while ianc == ipos:
ipos = np.random.randint(0, len(pic_classes[pos_class]))
ineg = np.random.randint(0, len(pic_classes[neg_class])) # random choose negative
triplets.append([pic_classes[pos_class][ianc], pic_classes[pos_class][ipos], pic_classes[neg_class][ineg],
pos_class, neg_class, pos_name, neg_name])
return triplets
def __getitem__(self, idx):
anc_id, pos_id, neg_id, pos_class, neg_class, pos_name, neg_name = self.training_triplets[idx]
anc_img = os.path.join(self.root_dir, str(pos_name), str(anc_id) + '.png') # join the path of anchor
pos_img = os.path.join(self.root_dir, str(pos_name), str(pos_id) + '.png') # join the path of positive
neg_img = os.path.join(self.root_dir, str(neg_name), str(neg_id) + '.png') # join the path of nagetive
anc_img = Image.open(anc_img).convert('RGB') # open the anchor image
pos_img = Image.open(pos_img).convert('RGB') # open the positive image
neg_img = Image.open(neg_img).convert('RGB') # open the negative image
pos_class = torch.from_numpy(np.array([pos_class]).astype('long')) # make label transform the type we want
neg_class = torch.from_numpy(np.array([neg_class]).astype('long')) # make label transform the type we want
data = [anc_img, pos_img,neg_img]
label = [pos_class, pos_class, neg_class]
if self.transform:
data = [self.transform(img) # preprocessing the image
for img in data]
return data, label
def __len__(self):
return len(self.training_triplets)
train function for triplet loss
import torchvision.transforms as transforms
def train_facenet(epoch, model, optimizer, margin, num_triplets):
model.train()
# preprocessing function for image
transform = transforms.Compose([
transforms.Resize(32),
transforms.CenterCrop(32),
transforms.ToTensor(),
transforms.Normalize(
mean=np.array([0.4914, 0.4822, 0.4465]),
std=np.array([0.2023, 0.1994, 0.2010])),
])
# get dataset of triplet
# num_triplet is adjustable
train_set = TripletFaceDataset(root_dir = './mnist/train',
csv_name = './mnist/train.csv',
num_triplets = num_triplets,
transform = transform)
train_loader = torch.utils.data.DataLoader(train_set,
batch_size = 16,
shuffle = True)
total_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
# load data to gpu
data[0], target[0] = data[0].cuda(), target[0].cuda() # anchor to cuda
data[1], target[1] = data[1].cuda(), target[1].cuda() # positive to cuda
data[2], target[2] = data[2].cuda(), target[2].cuda() # negative to cuda
data[0], target[0] = Variable(data[0]), Variable(target[0]) # anchor
data[1], target[1] = Variable(data[1]), Variable(target[1]) # positive
data[2], target[2] = Variable(data[2]), Variable(target[2]) # negative
# zero setting the grad
optimizer.zero_grad()
# forward
anchor = model.forward(data[0])
positive = model.forward(data[1])
negative = model.forward(data[2])
# margin is adjustable
loss = TripletLoss(margin=margin, num_classes=10).forward(anchor, positive, negative) # get triplet loss
total_loss += loss.item()
# back-propagating
loss.backward()
optimizer.step()
context = 'Train Epoch: {} [{}/{}], Average loss: {:.4f}'.format(
epoch, len(train_loader.dataset), len(train_loader.dataset), total_loss / len(train_loader))
print(context)
test function for triplet loss
关于如何测试的问题,由于triplet loss训练的resnet18网络没有分类器,这个网络的最后一层的输出是一个维度为embedding_size的向量,我们把它当作由模型提取出的特征,所以利用这个特征来做测试。首先保存下训练集上所有图片的特征和标签,用sklearn库的KNeighborsClassifier()拟合成一个KNN分类器,这里的K表示领域的个数,K是一个可调节的参数,在测试集上做验证时,提取图片的特征用KNN分类器做预测即可。
from sklearn import neighbors
def KNN_classifier(model, epoch, n_neighbors):
'''
use all train set data to make KNN classifier
'''
model.eval()
# preprocessing function for image
transform = transforms.Compose([
transforms.Resize(32),
transforms.ToTensor(),
transforms.Normalize(
mean=np.array([0.485, 0.456, 0.406]),
std=np.array([0.229, 0.224, 0.225])),
])
# prepare dataset by ImageFolder, data should be classified by directory
train_set = torchvision.datasets.ImageFolder(root='./mnist/train', transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=False)
features, labels =[], [] # store features and labels
for i, (data, target) in enumerate(train_loader):
# load data to gpu
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
# forward
output = model(data)
# get features and labels to make knn classifier,extend的含义是给列表追加;列表
features.extend(output.data.cpu().numpy())
labels.extend(target.data.cpu().numpy())
# n_neighbor is adjustable
clf = neighbors.KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(features, labels)
return clf
def test_facenet(epoch, model, clf, test = True):
model.eval()
# preprocessing function for image
transform = transforms.Compose([
transforms.Resize(32),
transforms.ToTensor(),
transforms.Normalize(
mean=np.array([0.485, 0.456, 0.406]),
std=np.array([0.229, 0.224, 0.225])),
])
# prepare dataset by ImageFolder, data should be classified by directory
test_set = torchvision.datasets.ImageFolder(root = './mnist/test' if test else './mnist/train', transform = transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size = 32, shuffle = True)
correct, total = 0, 0
for i, (data, target) in enumerate(test_loader):
# load data to gpu
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
# forward
output = model.forward(data)
# predict by knn classifier
predicted = clf.predict(output.data.cpu().numpy())
correct += (torch.tensor(predicted) == target.data.cpu()).sum()
total += target.size(0)
context = 'Accuracy of model in ' + ('test' if test else 'train') + \
' set is {}/{}({:.2f}%)'.format(correct, total, 100. * float( correct) / float(total))
print(context)
训练与测试
def run_facenet():
# hyper parameter
lr = 0.01
margin = 2.0
num_triplets = 1000
n_neighbors = 5
embedding_size = 128
num_epochs=1
# embedding_size is adjustable
model = ResNet18(embedding_size, 10)
# load model into GPU device
device = torch.device('cuda:0')
model = model.to(device)
if device == 'cuda':
model = torch.nn.DataParallel(model)
cudnn.benchmark = True
# define the optimizer, lr、momentum、weight_decay is adjustable
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
print('start training')
for epoch in range(num_epochs):
train_facenet(epoch, model, optimizer, margin, num_triplets) # train resnet18 with triplet loss
clf = KNN_classifier(model, epoch, n_neighbors) # get knn classifier
test_facenet(epoch, model, clf, False) # validate train set
test_facenet(epoch, model, clf, True) # validate test set
if (epoch + 1) % 4 == 0 :
lr = lr / 3
for param_group in optimizer.param_groups:
param_group['lr'] = lr
run_facenet()
start training
Train Epoch: 0 [1000/1000], Average loss: 0.9263
Accuracy of model in train set is 1684/2000(84.20%)
Accuracy of model in test set is 792/1000(79.20%)
训练一个较好的resnet18网络,收集在测试集上所有预测错误的样本图片(1000张测试集图片,分错不应超过30张,3%)。并在训练集上找出离这个样本最近的同类样本和错类样本的图片。例如,对于一个样本sample,正确类别为A,模型将其错分为B,分别找出训练集中A类样本和B类样本中离sample最近的样本图片。
import pandas
import os
def test_facenet(epoch, model, clf, test = True, analyse = False):
train_frame = pandas.read_csv('./mnist/train.csv')
test_frame = pandas.read_csv('./mnist/test.csv')
model.eval()
# preprocessing function for image
transform = transforms.Compose([
transforms.Resize(32),
transforms.ToTensor(),
transforms.Normalize(
mean=np.array([0.485, 0.456, 0.406]),
std=np.array([0.229, 0.224, 0.225])),
])
features =[]
test_labels = []
# if analyse:
# train_set = torchvision.datasets.ImageFolder(root='./mnist/train', transform=transform)
# train_loader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=False)
# for i, (data, target) in enumerate(train_loader):
# # data, target = data.cuda(), target.cuda()
# data, target = Variable(data), Variable(target)
# output = model.forward(data)
# features.extend(output.data.cpu().numpy())
# # prepare dataset by ImageFolder, data should be classified by directory
test_set = torchvision.datasets.ImageFolder(root = './mnist/test' if test else './mnist/train', transform = transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size = 32, shuffle = not analyse)
correct, total = 0, 0
for i, (data, target) in enumerate(test_loader):
# load data to gpu
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
# forward
output = model.forward(data)
# predict by knn classifier
predicted = clf.predict(output.data.cpu().numpy())
if (analyse):
test_labels.extend(torch.tensor(predicted) == target.data.cpu())
correct += (torch.tensor(predicted) == target.data.cpu()).sum()
total += target.size(0)
if (analyse):
[os.remove('./result/testwrong/'+x) for x in os.listdir('./result/testwrong/')]
for index in range(len(test_labels)):
if (test_labels[index] == False):
image_path = os.path.join('./mnist/test', str(test_frame['name'][index]), str(test_frame['id'][index]) + '.png')
image = Image.open(image_path).convert('RGB')
image.save('./result/testwrong/'+str(test_frame['name'][index])+"test"+str(test_frame['id'][index]) + '.png')
test_set = torchvision.datasets.ImageFolder(root = './result', transform = transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size = 1, shuffle = False)
test_features = []
names = [x[:-4] for x in os.listdir('./result/testwrong/')]
for i, (data, target) in enumerate(test_loader):
# load data to gpu
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
# forward
output = finalmodel.forward(data)
test_features.extend(output.data.cpu().numpy())
test_labels = [int(x[0]) for x in names]
for i in range(len(test_labels)):
positive_pos = 0
negative_pos = 0
positive_value = 10086
negative_value = 10086
for j in range(len(features)):
distance = np.linalg.norm(features[j]-test_features[i])
if j in range(test_labels[i]*200, test_labels[i]*200+200):
if distance < positive_value:
positive_value = distance
positive_pos = j
else:
if distance < negative_value:
negative_value = distance
negative_pos = j
image_path = os.path.join('./mnist/train', str(train_frame['name'][positive_pos]), str(train_frame['id'][positive_pos]) + '.png')
image = Image.open(image_path).convert('RGB')
image.save('./result/trainpos/'+ names[i]+ '_pos.png')
image_path = os.path.join('./mnist/train', str(train_frame['name'][negative_pos]), str(train_frame['id'][negative_pos]) + '.png')
image = Image.open(image_path).convert('RGB')
image.save('./result/trainneg/'+ names[i]+ '_neg.png')
context = 'Accuracy of model in ' + ('test' if test else 'train') + \
' set is {}/{}({:.2f}%)'.format(correct, total, 100. * float( correct) / float(total))
print(context)
def run_facenet():
# hyper parameter
lr = 0.012
margin = 1
num_triplets = 1000
n_neighbors = 5
embedding_size = 128
num_epochs=14
# embedding_size is adjustable
model = ResNet18(embedding_size, 10)
# load model into GPU device
device = torch.device('cuda:0')
model = model.to(device)
if device == 'cuda':
model = torch.nn.DataParallel(model)
cudnn.benchmark = True
# define the optimizer, lr、momentum、weight_decay is adjustable
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.55, weight_decay=3e-4)
print('start training')
for epoch in range(num_epochs):
train_facenet(epoch, model, optimizer, margin, num_triplets) # train resnet18 with triplet loss
clf = KNN_classifier(model, epoch, n_neighbors) # get knn classifier
test_facenet(epoch, model, clf, False) # validate train set
test_facenet(epoch, model, clf, True, epoch==num_epochs-1) # validate test set
if (epoch + 1) % 5 == 0 :
lr = lr / 1.1
for param_group in optimizer.param_groups:
param_group['lr'] = lr
return model
finalmodel = run_facenet()
start training
Train Epoch: 0 [1000/1000], Average loss: 0.4509
Accuracy of model in train set is 1838/2000(91.90%)
Accuracy of model in test set is 900/1000(90.00%)
Train Epoch: 1 [1000/1000], Average loss: 0.1792
Accuracy of model in train set is 1903/2000(95.15%)
Accuracy of model in test set is 946/1000(94.60%)
Train Epoch: 2 [1000/1000], Average loss: 0.0898
Accuracy of model in train set is 1908/2000(95.40%)
Accuracy of model in test set is 937/1000(93.70%)
Train Epoch: 3 [1000/1000], Average loss: 0.0959
Accuracy of model in train set is 1925/2000(96.25%)
Accuracy of model in test set is 951/1000(95.10%)
Train Epoch: 4 [1000/1000], Average loss: 0.0725
Accuracy of model in train set is 1936/2000(96.80%)
Accuracy of model in test set is 959/1000(95.90%)
Train Epoch: 5 [1000/1000], Average loss: 0.0554
Accuracy of model in train set is 1934/2000(96.70%)
Accuracy of model in test set is 958/1000(95.80%)
Train Epoch: 6 [1000/1000], Average loss: 0.0371
Accuracy of model in train set is 1938/2000(96.90%)
Accuracy of model in test set is 953/1000(95.30%)
Train Epoch: 7 [1000/1000], Average loss: 0.0344
Accuracy of model in train set is 1952/2000(97.60%)
Accuracy of model in test set is 965/1000(96.50%)
Train Epoch: 8 [1000/1000], Average loss: 0.0141
Accuracy of model in train set is 1950/2000(97.50%)
Accuracy of model in test set is 961/1000(96.10%)
Train Epoch: 9 [1000/1000], Average loss: 0.0324
Accuracy of model in train set is 1949/2000(97.45%)
Accuracy of model in test set is 963/1000(96.30%)
Train Epoch: 10 [1000/1000], Average loss: 0.0248
Accuracy of model in train set is 1944/2000(97.20%)
Accuracy of model in test set is 962/1000(96.20%)
Train Epoch: 11 [1000/1000], Average loss: 0.0320
Accuracy of model in train set is 1949/2000(97.45%)
Accuracy of model in test set is 968/1000(96.80%)
Train Epoch: 12 [1000/1000], Average loss: 0.0460
Accuracy of model in train set is 1968/2000(98.40%)
Accuracy of model in test set is 969/1000(96.90%)
Train Epoch: 13 [1000/1000], Average loss: 0.0203
Accuracy of model in train set is 1961/2000(98.05%)
Accuracy of model in test set is 970/1000(97.00%)
测试集上错误的三十张图片,以及训练集上同类和不同类中与之相距最近的图片,都存放在了result下面的三个文件夹里面。
# 展示所有的图片。
#coding:utf-8
from PIL import Image
import matplotlib.pyplot as plt
path0 = ['./result/testwrong/'+x for x in os.listdir('./result/testwrong/')]
path1 = ['./result/trainpos/'+x for x in os.listdir('./result/trainpos/')]
path2 = ['./result/trainneg/'+x for x in os.listdir('./result/trainneg/')]
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
for i in range(len(path0)):
fig, ax = plt.subplots(1, 3, figsize=(12, 8))
ax[0].imshow(Image.open(path0[i]).convert('RGB'))
ax[0].set_title(str(test_labels[i])+'类被预测错误')
ax[1].imshow(Image.open(path1[i]).convert('RGB'))
ax[1].set_title(str('训练集距离最近的同类样本'))
ax[2].imshow(Image.open(path2[i]).convert('RGB'))
ax[2].set_title(str('训练集距离最近的异类样本'))
plt.close()