BigBrother的大数据之旅Day 12 Hbase(1)
HBASE (Hadoop Database)是个高可用,高性能, 面向列可伸缩、实时读写的分布式数据库
Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为其分布式协同服务
1 hbse的表结构
| Row Key | Time Stamp | CF1 | CF2 | CF3 |
|---|---|---|---|---|
| 11248112 | t6 | CF2:q1=val1 | CF3:q3=val3 | |
| t3 | ||||
| t2 | CF1:q2=val2 |
l RowKey
是Byte array,是表中每条记录的“主键”,Rowkey的设计非常重要;
l Timestamp
版本号,类型为Long,默认值是系统时间戳,可由用户自定义
l ColumnFamily
列族,拥有一个名称(string),包含一个或者多个相关列
l Column
属于某一个列族,格式为:familyName:columnName,每条记录可动态添加
l Value(Cell)
单元格由行键、列族、列、 时间戳唯一决定(默认保存3个时间戳记录)
单元格的数据是没有类型的,全部以字节码形式存储
2 hbase的架构及其组件和作用
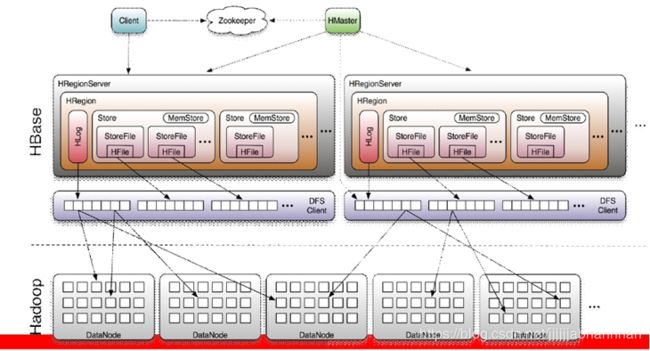
(1) client 是用户端的接口,保存cache
(2) zookeeper分布式调度框架, 集群搭建使用了zookeeper的配置元数据功能(存储HBase的schema和table元数据),是一个进程通知其他进程需要做什么的一种常用方式.ZooKeeper使用共享存储模型来实现应用间的协作和同步原语。
zookeeper 存贮所有Region的寻址入口。
(3) Hmaster
a 为 regionServer分配region,
b 负责regionserver的负载均衡,
c 发现失效端regionserver后,重新分配其上的region
d 管理用户对table端增删改查
(4)region server
多个regionserver合为一个regionserver集群(Cluster)
a 维护region处理region端IO请求
b 负责切分在运行过程中变得过大的region
(5) region
hbase的表分为多个region(横着把表切开)
ps : 数据是连续的
region裂变: region不断增大,当增大到一个阈值端时候就会分割为两个region
(6) store 分为memstore(1个)和storefile(0-n个)
a 一个store对应一个列族(竖着切行)
b 首先向memstore中存储数据,当数据到达一定阈值时,flash cache把数据写到storefile中(每次都是一个单独的文件)
c n个storefile合并为一个文件,分为大合并和小合并,大合并期间会删除多余的数据,平常只会在数据上添加墓碑标记,进行逻辑删除
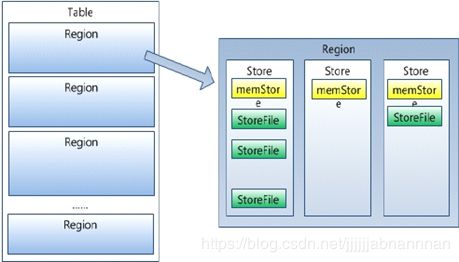
总之 region server cluster >> region server >> region>> store
3 详述hbase的读写流程
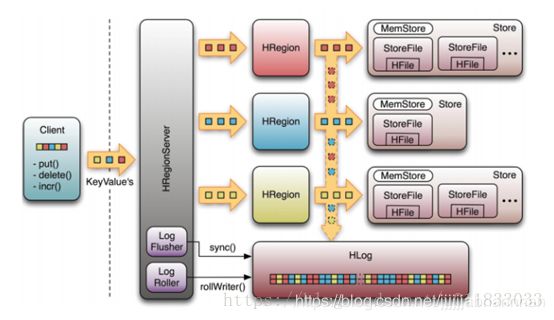
写流程:
(1) client 通过zookeeper的调度向regionserver发送请求
(2) 数据首先写入hlog和memstore(key排序)
(3)当memstroe中数据到达一定阈值时,flush(单独的一个线程)到storefile(只读文件)
(4)多个storefile文件合并为大的storefile文件
(5)单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个新的Region。父Region会下线,新Split出的2个子Region会被HMaster分配到相应的RegionServer上,使得原先1个Region的压力得以分流到2个Region上。
读操作
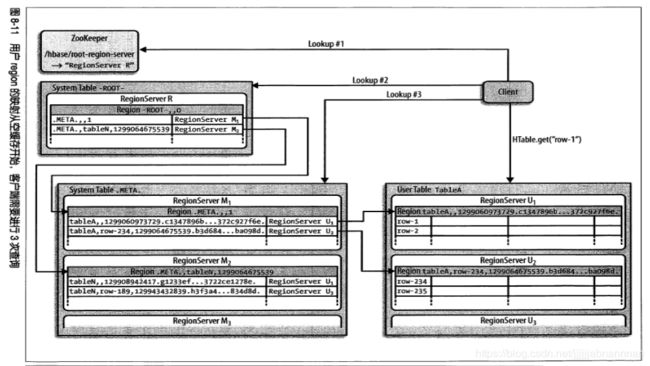
client–>Zookeeper–>-ROOT-表(好像0.96版本后就取消了)–>.META.表(内存表,存放在regionserver上)–>RegionServer–>Region–>client
(1) client访问zk,查找root表,得到.meta表的信息(region元数据)
(2) 从.meta表中找到目标region信息,找到对应端regionserver
(3) 获取数据 优先级为 blockcache > memstore> storefile
如果blockcache中没有查询到的结果,会把最后读取的结果存放到cache中(前提是读到了数据)
4 hbase集群搭建步骤
(1)copy hbase-0.98.12.1-hadoop2-bin.tar.gz到HBASE主节点
(2)解压文件到 /usr/local/hbase(记得创建hbase目录)
tar zxvf hbase-0.98.12.1-hadoop2-bin.tar.gz -C /usr/local/hbase
(3) 配置环境变量
/usr/local/hbase/hbase-0.98.12.1-hadoop2/conf下
a: hbase-env.sh中设置HBASE_MANAGES_ZK为false – 不使用hbase自带的zookeeper,使用自己的zookeeper集群
b: 配置java_home
export JAVA_HOME=/usr/java/jdk1.7.0_80
export HBASE_MANAGES_ZK=false
(4) 配置hbse-site.xml文件
/usr/local/hbase/hbase-0.98.12.1-hadoop2/conf
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://mycluster/hbasevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>node2,node3,node4value>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/var/bjsxt/hbase/zookeepervalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
configuration>
(5) 配置backup节点
在/usr/local/hbase/hbase-0.98.12.1-hadoop2/conf下
创建backup-master文件,并写入
node2 – node2 为backup节点,将来会在机器上开启从master进程
(6) 配置regionserver节点
在/usr/local/hbase/hbase-0.98.12.1-hadoop2/conf下
vim regionservers 写入
node2
node3
node4
(7) copy hdfs-site.xml文件到hbase的conf下
(8) scp hbse到每个节点(node2,node3,node4)
(9) 在每个node的profile文件中加入hbase的位置环境变量
export HBASE_HOME=/usr/local/hbase/hbase-0.98.12.1-hadoop2
export PATH=$PATH:$HBASE_HOME/bin
记得要source一下这个文件哦
(10) 在bin下面有开启和关闭的脚本
(11) 通过浏览器测试访问[外链图片转存失败
(12) 命令行访问

5 列出hbase的基本操作
| 名称 | Shell命令 |
|---|---|
| 创建表 | create ‘表名’, ‘列族名1’[,…] |
| 查看所有表 | list |
| 添加记录 | put ‘表名’, ‘RowKey’, ‘列族名称:列名’, ‘值’ |
| 查看记录 | get ‘表名’, ‘RowKey’, ‘列族名称:列名’ |
| 查看表中的记录总数 | count ‘表名’ |
| 删除记录 | delete ‘表名’ , ‘RowKey’, ‘列族名称:列名’ |
| 删除一张表 | 先要屏蔽该表,才能对该表进行删除。 第一步 disable ‘表名称’ 第二步 drop ‘表名称’ |
| 查看所有记录 | scan '表名" ’ --慎用如果表数据多的话 |
6 列出hbase的java api基本操作
//conf为配置文件,添加了zookeeper的地址
//创建一个数据库级的对象
admin = new HBaseAdmin(conf)
//创建表级的对象,tm为表的名称
table = new HTable(conf,tm.getBytes())
//表级操作
//判断tm表是否存在
admin.tableExists(tm)
//把tm表置为无效
admin.disableTable(tm)
//删除表,首先需要把表置为无效
admin.deleteTable(tm)
//创建表
admin.createTable(tm)
//行级操作
//写操作
//1 创建行级操作的对象put,并指定rowkey
Put put = new Put("001rowkey".getBytes());
//2 要插入的每一列的值
//cf列族名,name为列名,zs是值
put.add("cf".getBytes(),"name".getBytes()),"zs".getBytes());
//3 写入表
table.put(put);
//读操作 get和scan
// ----get----
//1 创建读取行对象get,并指定rowkey
Get get = new Get("001rowkey".getBytes());
//2 指定需要查询的列族和列
// 添加要获取的列和列族,减少网络的io,相当于在服务器端做了过滤
get.addColumn("cf".getBytes(),"name".getBytes());
//3 查询的返回值
Result result = table.get(get);
//4 获取查询的单元结果
Cell cel1 = result.getColumnLatestCell("cf".getBytes(),name.getBytes());
//5 输出结果
System.out.print(Bytes.toString(CellUtil.cloneValue(cel1)))
//------scan--------
//1 创建对象,并指定rowkey
Scan scan = new Scan();
//从rowkey1111扫描到rowkey1112不包含1113
scan.setStarRow("1111".getBytes());
scan.setStopRow("1113".getBytes());
//2 设置查询的列族和列
scan.addColumn("cf".getBytes(),"name".getBytes());
//3 用结果接收一下
ResultScanner rss = table.getScanner(scan);
//4 遍历结果集
for (Result result : rss) {
List<Cell> cellsName = result.getColumnCells("cf".getBytes(), "name".getBytes());
for (Cell cell : cellsName) {
//5 输出结果
System.out.print("\t\t" + Bytes.toString(CellUtil.cloneValue(cell)));
}
System.out.println();
//其他api
scan相关
addFamily指定要扫描列族中的所有列
setTimeRange指定要获取的列的timestamp范围
setTimestamp指定要获取列值的timestamp
setMaxVersions指定要获取的列值的版本数
setBatch限制next()方法返回的值的最大数量
setFilter指定过滤器
setCacheBlocks(boolean)显式指定禁用本次扫描服务端的block缓存
使用完毕后不要忘了,关闭admin哦 admin.close();
参考
版权声明:本文参考图片为CSDN博主「山上的神仙」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u011833033/article/details/79773421