第二阶段-tensorflow程序图文详解(四) Graphs and Sessions
TensorFlow uses a dataflow graph to represent your computation in terms of the dependencies between individual operations. This leads to a low-level programming model in which you first define the dataflow graph, then create a TensorFlow session to run parts of the graph across a set of local and remote devices.
TensorFlow使用数据流图来呈现你的计算过程,我们将定义一个session来运行在一些本地或者远程的设备 ,使用一个底层程序模型。
This guide will be most useful if you intend to use the low-level programming model directly. Higher-level APIs such as tf.estimator.Estimator and Keras hide the details of graphs and sessions from the end user, but this guide may also be useful if you want to understand how these APIs are implemented.
如果直接使用底层程序运行模型,这个教程是很有用的。高层API程序将隐藏graph的细节。当然这个教程也是有用的,可以使你了解这些API的实现。
1,Why dataflow graphs?
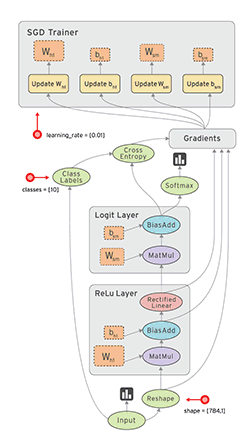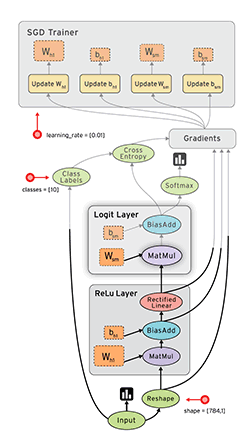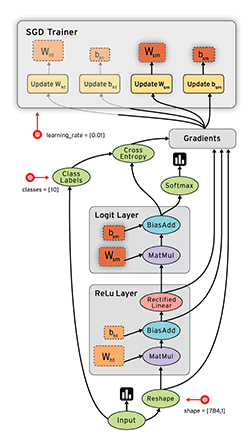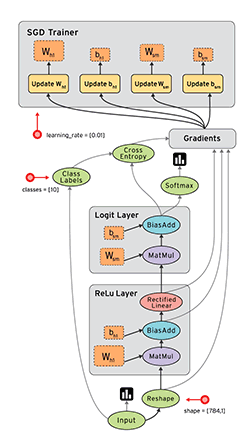
Dataflow is a common programming model for parallel computing. In a dataflow graph, the nodes represent units of computation, and the edges represent the data consumed or produced by a computation. For example, in a TensorFlow graph, the tf.matmul operation would correspond to a single node with two incoming edges (the matrices to be multiplied) and one outgoing edge (the result of the multiplication).
数据流通常是一个并行计算的程序模型,在数据流图中,节点呈现一个计算的单元。边呈现宇数据消费或者有计算产生。例如:在tensorflow图中,tf.matmul操作被转换成一个节点,并且拥有两条输入边,一条输出边。
Dataflow has several advantages that TensorFlow leverages when executing your programs:
在tensorflow执行程序中,数据流拥有几个优势。
Parallelism. By using explicit edges to represent dependencies
between operations, it is easy for the system to identify operations
that can execute in parallel.
并行处理,非常容易定义并行操作。Distributed execution. By using explicit edges to represent the
values that flow between operations, it is possible for TensorFlow
to partition your program across multiple devices (CPUs, GPUs, and
TPUs) attached to different machines. TensorFlow inserts the
necessary communication and coordination between devices.
分布式执行,显示的呈现多设备不同机器的运行协作,通信。Compilation. TensorFlow’s XLA compiler can use the information in
your dataflow graph to generate faster code, for example, by fusing
together adjacent operations.
汇编,XLA编译器能够使用这些信息,快速生成代码。例如:可以融合相邻的操作。Portability. The dataflow graph is a language-independent
representation of the code in your model. You can build a dataflow
graph in Python, store it in a SavedModel, and restore it in a C++
program for low-latency inference.
移植性,数据流不依赖于语言,可以使用python建立模型,并保存。使用C++来加载模型。2,What is a tf.Graph?
A tf.Graph contains two relevant kinds of information:
Graph structure. The nodes and edges of the graph, indicating how
individual operations are composed together, but not prescribing how
they should be used. The graph structure is like assembly code:
inspecting it can convey some useful information, but it does not
contain all of the useful context that source code conveys.
图形结构。图的节点和边,指示如何
个别的操作是组合在一起的,但是没有规定如何
他们应该使用。图结构就像汇编代码:
检查它可以传达一些有用的信息,但事实并非如此
包含源代码传达的所有有用的上下文。Graph collections. TensorFlow provides a general mechanism for
storing collections of metadata in a tf.Graph. The
tf.add_to_collection function enables you to associate a list of
objects with a key (where tf.GraphKeys defines some of the standard
keys), and tf.get_collection enables you to look up all objects
associated with a key. Many parts of the TensorFlow library use this
facility: for example, when you create a tf.Variable, it is added by
default to collections representing “global variables” and
“trainable variables”. When you later come to create a
tf.train.Saver or tf.train.Optimizer, the variables in these
collections are used as the default arguments.
图形集合。 TensorFlow提供了一个通用机制
在tf.Graph中存储元数据的集合。该
tf.add_to_collection函数使您能够关联一个列表
对象与一个键(其中tf.GraphKeys定义了一些标准
键),tf.get_collection使您能够查找所有对象
与一个关键字相关联。 TensorFlow库的很多部分都使用它
设施:例如,当你创建一个tf.Variable,它被添加
默认为代表“全局变量”的集合
“可训练变量”。当你以后来创建一个
tf.train.Saver或tf.train.Optimizer,这些变量
集合被用作默认参数。
3,Building a tf.Graph
Most TensorFlow programs start with a dataflow graph construction phase. In this phase, you invoke TensorFlow API functions that construct new tf.Operation (node) and tf.Tensor (edge) objects and add them to a tf.Graph instance. TensorFlow provides a default graph that is an implicit argument to all API functions in the same context. For example:
大多数TensorFlow程序从数据流图构建阶段开始。在这个阶段,你调用TensorFlow API函数来构造新的tf.Operation(node)和tf.Tensor(edge)对象并将它们添加到tf.Graph实例中。 TensorFlow提供了一个默认图形,它是对同一个上下文中的所有API函数的隐式参数。例如:
Calling tf.constant(42.0) creates a single tf.Operation that
produces the value 42.0, adds it to the default graph, and returns a
tf.Tensor that represents the value of the constant.
调用tf.constant(42.0)创建一个单独的tf.Operation
生成值42.0,将其添加到默认图形,并返回一个
tf.Tensor表示常数的值。Calling tf.matmul(x, y) creates a single tf.Operation that
multiplies the values of tf.Tensor objects x and y, adds it to the
default graph, and returns a tf.Tensor that represents the result of
the multiplication.
调用tf.matmul(x,y)创建一个单独的tf.Operation
将tf.Tensor对象x和y的值相乘,并将其添加到
默认图形,并返回一个表示结果的tf.Tensor
乘法。Executing v = tf.Variable(0) adds to the graph a tf.Operation that
will store a writeable tensor value that persists between
tf.Session.run calls. The tf.Variable object wraps this operation,
and can be used like a tensor, which will read the current value of
the stored value. The tf.Variable object also has methods such as
assign and assign_add that create tf.Operation objects that, when
executed, update the stored value. (See Variables for more
information about variables.)
.执行v = tf.Variable(0)将tf.Operation添加到图中
将存储可持续的可写张量值
tf.Session.run调用。 tf.Variable对象包装了这个操作,
并可以像张量一样使用,它将读取当前的值
储值。 tf.Variable对象也有类似的方法
assign和assign_add,创建tf.Operation对象的时候
执行,更新存储的值。 (有关更多信息,请参阅变量
有关变量的信息。)Calling tf.train.Optimizer.minimize will add operations and tensors
to the default graph that calculate gradients, and return a
tf.Operation that, when run, will apply those gradients to a set of
variables.
调用tf.train.Optimizer.minimize将添加操作和张量
到计算渐变的默认图形,并返回一个
运行时,运行时会将这些梯度应用到一组
变量。
Most programs rely solely on the default graph. However, see Dealing with multiple graphs for more advanced use cases. High-level APIs such as the tf.estimator.Estimator API manage the default graph on your behalf, and–for example–may create different graphs for training and evaluation.
大多数程序仅依赖于默认图形。但是,请参阅处理多个图表以获取更高级的用例。 tf.estimator.Estimator API等高级API代表您管理默认图形,例如,可以为训练和评估创建不同的图形。
Note: Calling most functions in the TensorFlow API merely adds operations and tensors to the default graph, but does not perform the actual computation. Instead, you compose these functions until you have a tf.Tensor or tf.Operation that represents the overall computation–such as performing one step of gradient descent–and then pass that object to a tf.Session to perform the computation. See the section “Executing a graph in a tf.Session” for more details.
注意:调用TensorFlow API中的大多数函数只是将操作和张量添加到默认图形中,但不会执行实际的计算。 相反,你要编写这些函数,直到你有一个tf.Tensor或者tf.Operation代表整个计算 - 比如执行梯度下降一步,然后把这个对象传给一个tf.Session来执行计算。 有关更多详细信息,请参见“在tf.Session中执行图形”一节。
4,Naming operations
A tf.Graph object defines a namespace for the tf.Operation objects it contains. TensorFlow automatically chooses a unique name for each operation in your graph, but giving operations descriptive names can make your program easier to read and debug. The TensorFlow API provides two ways to override the name of an operation:
tf.Graph对象为其包含的tf.Operation对象定义一个名称空间。 TensorFlow自动为图形中的每个操作选择一个唯一的名称,但给操作描述性名称可以使您的程序更易于阅读和调试。 TensorFlow API提供了两种方法来覆盖操作的名称:
Each API function that creates a new tf.Operation or returns a new
tf.Tensor accepts an optional name argument. For example,
tf.constant(42.0, name=”answer”) creates a new tf.Operation named
“answer” and returns a tf.Tensor named “answer:0”. If the default
graph already contained an operation named “answer”, the TensorFlow
would append “_1”, “_2”, and so on to the name, in order to make it
unique.
每个创建新的tf.Operation的API函数或返回一个新的tf.Tensor接受一个可选的名称参数。例如,tf.constant(42.0,name =“answer”)创建一个新的名为“answer”的tf.Operation,并返回一个名为“answer:0”的tf.Tensor。如果默认图表已经包含一个名为“answer”的操作,则TensorFlow会在名称后加上“_1”,“_2”等,以使其唯一。The tf.name_scope function makes it possible to add a name scope
prefix to all operations created in a particular context. The current
name scope prefix is a “/”-delimited list of the names of all active
tf.name_scope context managers. If a name scope has already been used
in the current context, TensorFlow appens “_1”, “_2”, and so on. For
example:tf.name_scope函数可以为特定上下文中创建的所有操作添加名称范围前缀。当前名称作用域前缀是“/” - 所有活动的tf.name_scope上下文管理器的名称的分隔列表。如果在当前上下文中已经使用了名称范围,则TensorFlow会显示“_1”,“_2”等。例如:
c_0 = tf.constant(0, name="c") # => operation named "c"
# Already-used names will be "uniquified".
c_1 = tf.constant(2, name="c") # => operation named "c_1"
# Name scopes add a prefix to all operations created in the same context.
with tf.name_scope("outer"):
c_2 = tf.constant(2, name="c") # => operation named "outer/c"
# Name scopes nest like paths in a hierarchical file system.
with tf.name_scope("inner"):
c_3 = tf.constant(3, name="c") # => operation named "outer/inner/c"
# Exiting a name scope context will return to the previous prefix.
c_4 = tf.constant(4, name="c") # => operation named "outer/c_1"
# Already-used name scopes will be "uniquified".
with tf.name_scope("inner"):
c_5 = tf.constant(5, name="c") # => operation named "outer/inner_1/c"The graph visualizer uses name scopes to group operations and reduce the visual complexity of a graph. See Visualizing your graph for more information.
图形可视化器使用名称范围来对操作进行分组,并减少图形的视觉复杂性。 请参阅可视化图形以获取更多信息。
Note that tf.Tensor objects are implicitly named after the tf.Operation that produces the tensor as output. A tensor name has the form “:” where:
请注意,tf.Tensor对象是以生成张量作为输出的tf.Operation隐式命名的。 张量名称的格式为“:”其中:
- “OP_NAME” is the name of the operation that produces it.
- “i” is an integer representing the index of that tensor among the
operation’s outputs.
5,Placing operations on different devices将操作放在不同的设备上
If you want your TensorFlow program to use multiple different devices, the tf.device function provides a convenient way to request that all operations created in a particular context are placed on the same device (or type of device).
A device specification has the following form:
/job:<JOB_NAME>/task:/device :where:
JOB_NAME> is an alpha-numeric string that does not start with a
number.
是一个不以a开头的字母数字字符串数。DEVICE_TYPE> is a registered device type (such as GPU or CPU).
TASK_INDEX> is a non-negative integer representing the index of the
task in the job named JOB_NAME>. See tf.train.ClusterSpec for an
explanation of jobs and tasks.
是一个非负整数表示的索引名为JOB_NAME>的作业中的任务。 请tf.train.ClusterSpec
工作和任务的解释。DEVICE_INDEX> is a non-negative integer representing the index of
the device, for example, to distinguish between different GPU devices
used in the same process.
是表示索引的非负整数该设备例如为了区分不同的GPU设备在相同的过程中使用。
You do not need to specify every part of a device specification. For example, if you are running in a single-machine configuration with a single GPU, you might use tf.device to pin some operations to the CPU and GPU:
# Operations created outside either context will run on the "best possible"
# device. For example, if you have a GPU and a CPU available, and the operation
# has a GPU implementation, TensorFlow will choose the GPU.
weights = tf.random_normal(...)
with tf.device("/device:CPU:0"):
# Operations created in this context will be pinned to the CPU.
img = tf.decode_jpeg(tf.read_file("img.jpg"))
with tf.device("/device:GPU:0"):
# Operations created in this context will be pinned to the GPU.
result = tf.matmul(weights, img)If you are deploying TensorFlow in a typical distributed configuration, you might specify the job name and task ID to place variables on a task in the parameter server job (“/job:ps”), and the other operations on task in the worker job (“/job:worker”):
如果要在典型的分布式配置中部署TensorFlow,则可以指定作业名称和任务ID,以将参数服务器作业(“/ job:ps”)中的任务中的变量以及作业中的任务中的其他操作(“/职业:工人”):
with tf.device("/job:ps/task:0"):
weights_1 = tf.Variable(tf.truncated_normal([784, 100]))
biases_1 = tf.Variable(tf.zeroes([100]))
with tf.device("/job:ps/task:1"):
weights_2 = tf.Variable(tf.truncated_normal([100, 10]))
biases_2 = tf.Variable(tf.zeroes([10]))
with tf.device("/job:worker"):
layer_1 = tf.matmul(train_batch, weights_1) + biases_1
layer_2 = tf.matmul(train_batch, weights_2) + biases_2tf.device gives you a lot of flexibility to choose placements for individual operations or broad regions of a TensorFlow graph. In many cases, there are simple heuristics that work well. For example, the tf.train.replica_device_setter API can be used with tf.device to place operations for data-parallel distributed training. For example, the following code fragment shows how tf.train.replica_device_setter applies different placement policies to tf.Variable objects and other operations:
tf.device为您提供了很大的灵活性,可以为单个操作或TensorFlow图的广泛区域选择展示位置。 在许多情况下,有简单的启发式运作。 例如,tf.train.replica_device_setter API可以与tf.device配合使用,以进行数据并行分布式培训的操作。 例如,以下代码片段显示了tf.train.replica_device_setter如何将不同的放置策略应用于tf.Variable对象和其他操作:
with tf.device(tf.train.replica_device_setter(ps_tasks=3)):
# tf.Variable objects are, by default, placed on tasks in "/job:ps" in a
# round-robin fashion.
w_0 = tf.Variable(...) # placed on "/job:ps/task:0"
b_0 = tf.Variable(...) # placed on "/job:ps/task:1"
w_1 = tf.Variable(...) # placed on "/job:ps/task:2"
b_1 = tf.Variable(...) # placed on "/job:ps/task:0"
input_data = tf.placeholder(tf.float32) # placed on "/job:worker"
layer_0 = tf.matmul(input_data, w_0) + b_0 # placed on "/job:worker"
layer_1 = tf.matmul(layer_0, w_1) + b_1 # placed on "/job:worker"6,Tensor-like objects
Many TensorFlow operations take one or more tf.Tensor objects as arguments. For example, tf.matmul takes two tf.Tensor objects, and tf.add_n takes a list of n tf.Tensor objects. For convenience, these functions will accept a tensor-like object in place of a tf.Tensor, and implicitly convert it to a tf.Tensor using the tf.convert_to_tensor method. Tensor-like objects include elements of the following types:
许多TensorFlow操作将一个或多个tf.Tensor对象作为参数。 例如,tf.matmul需要两个tf.Tensor对象,而tf.add_n需要一个tf.Tensor对象的列表。 为了方便起见,这些函数将接受张量类对象来代替tf.Tensor,并使用tf.convert_to_tensor方法将其隐式转换为tf.Tensor。 类似张量的对象包括以下类型的元素:
tf.Tensor
tf.Variable
numpy.ndarray
list (and lists of tensor-like objects)
Scalar Python types: bool, float, int, strYou can register additional tensor-like types using tf.register_tensor_conversion_function.
Note: By default, TensorFlow will create a new tf.Tensor each time you use the same tensor-like object. If the tensor-like object is large (e.g. a numpy.ndarray containing a set of training examples) and you use it multiple times, you may run out of memory. To avoid this, manually call tf.convert_to_tensor on the tensor-like object once and use the returned tf.Tensor instead.
您可以使用tf.register_tensor_conversion_function注册附加张量类型的类型。
注意:默认情况下,TensorFlow会在每次使用相同张量对象时创建一个新的tf.Tensor。 如果张量对象很大(例如包含一组训练样例的numpy.ndarray)并且多次使用它,则可能会用完内存。 为了避免这种情况,请手动调用张量类对象上的tf.convert_to_tensor一次,然后使用返回的tf.Tensor。
7,Executing a graph in a tf.Session
TensorFlow uses the tf.Session class to represent a connection between the client program—typically a Python program, although a similar interface is available in other languages—and the C++ runtime. A tf.Session object provides access to devices in the local machine, and remote devices using the distributed TensorFlow runtime. It also caches information about your tf.Graph so that you can efficiently run the same computation multiple times.
Creating a tf.Session
If you are using the low-level TensorFlow API, you can create a tf.Session for the current default graph as follows:
# Create a default in-process session.
with tf.Session() as sess:
# ...
# Create a remote session.
with tf.Session("grpc://example.org:2222"):
# ...Since a tf.Session owns physical resources (such as GPUs and network connections), it is typically used as a context manager (in a with block) that automatically closes the session when you exit the block. It is also possible to create a session without using a with block, but you should explicitly call tf.Session.close when you are finished with it to free the resources.
Note: Higher-level APIs such as tf.train.MonitoredTrainingSession or tf.estimator.Estimator will create and manage a tf.Session for you. These APIs accept optional target and config arguments (either directly, or as part of a tf.estimator.RunConfig object), with the same meaning as described below.
由于tf.Session拥有物理资源(如GPU和网络连接),因此它通常用作在退出块时自动关闭会话的上下文管理器(在with block中)。 也可以在不使用with块的情况下创建一个会话,但是当你完成它以释放资源时,你应该明确地调用tf.Session.close。
注意:tf.train.MonitoredTrainingSession或tf.estimator.Estimator等更高级别的API将为您创建和管理tf.Session。 这些API接受可选的目标和配置参数(直接或者作为tf.estimator.RunConfig对象的一部分),具有与下面描述的相同的含义。
tf.Session.init accepts three optional arguments:
target. If this argument is left empty (the default), the session
will only use devices in the local machine. However, you may also
specify a grpc:// URL to specify the address of a TensorFlow server,
which gives the session access to all devices on machines that this
server controls. See tf.train.Server for details of how to create a
TensorFlow server. For example, in the common between-graph
replication configuration, the tf.Session connects to a
tf.train.Server in the same process as the client. The distributed
TensorFlow deployment guide describes other common scenarios.graph. By default, a new tf.Session will be bound to—and only able
to run operations in—the current default graph. If you are using
multiple graphs in your program (see Programming with multiple
graphs for more details), you can specify an explicit tf.Graph when
you construct the session.config. This argument allows you to specify a tf.ConfigProto that
controls the behavior of the session. For example, some of the
configuration options include:allow_soft_placement. Set this to True to enable a “soft” device
placement algorithm, which ignores tf.device annotations that
attempt to place CPU-only operations on a GPU device, and places
them on the CPU instead.cluster_def. When using distributed TensorFlow, this option allows
you to specify what machines to use in the computation, and provide
a mapping between job names, task indices, and network addresses.
See tf.train.ClusterSpec.as_cluster_def for details.graph_options.optimizer_options. Provides control over the
optimizations that TensorFlow performs on your graph before
executing it.gpu_options.allow_growth. Set this to True to change the GPU memory
allocator so that it gradually increases the amount of memory
allocated, rather than allocating most of the memory at startup.
Using tf.Session.run to execute operations
The tf.Session.run method is the main mechanism for running a tf.Operation or evaluating a tf.Tensor. You can pass one or more tf.Operation or tf.Tensor objects to tf.Session.run, and TensorFlow will execute the operations that are needed to compute the result.
tf.Session.run requires you to specify a list of fetches, which determine the return values, and may be a tf.Operation, a tf.Tensor, or a tensor-like type such as tf.Variable. These fetches determine what subgraph of the overall tf.Graph must be executed to produce the result: this is the subgraph that contains all operations named in the fetch list, plus all operations whose outputs are used to compute the value of the fetches. For example, the following code fragment shows how different arguments to tf.Session.run cause different subgraphs to be executed:
tf.Session.run要求你指定一个确定返回值的提取列表,可以是一个tf.Operation,一个tf.Tensor,或者一个类似张量的类型,比如tf.Variable。 这些提取决定了必须执行整个tf.Graph的哪个子图来产生结果:这是包含在提取列表中命名的所有操作的子图,以及所有其输出用于计算提取值的操作的子图。 例如,下面的代码片段显示了对tf.Session.run的不同参数如何导致不同的子图被执行:
x = tf.constant([[37.0, -23.0], [1.0, 4.0]])
w = tf.Variable(tf.random_uniform([2, 2]))
y = tf.matmul(x, w)
output = tf.nn.softmax(y)
init_op = w.initializer
with tf.Session() as sess:
# Run the initializer on `w`.
sess.run(init_op)
# Evaluate `output`. `sess.run(output)` will return a NumPy array containing
# the result of the computation.
print(sess.run(output))
# Evaluate `y` and `output`. Note that `y` will only be computed once, and its
# result used both to return `y_val` and as an input to the `tf.nn.softmax()`
# op. Both `y_val` and `output_val` will be NumPy arrays.
y_val, output_val = sess.run([y, output])tf.Session.run also optionally takes a dictionary of feeds, which is a mapping from tf.Tensor objects (typically tf.placeholder tensors) to values (typically Python scalars, lists, or NumPy arrays) that will be substituted for those tensors in the execution. For example:
# Define a placeholder that expects a vector of three floating-point values,
# and a computation that depends on it.
x = tf.placeholder(tf.float32, shape=[3])
y = tf.square(x)
with tf.Session() as sess:
# Feeding a value changes the result that is returned when you evaluate `y`.
print(sess.run(y, {x: [1.0, 2.0, 3.0]}) # => "[1.0, 4.0, 9.0]"
print(sess.run(y, {x: [0.0, 0.0, 5.0]}) # => "[0.0, 0.0, 25.0]"
# Raises `tf.errors.InvalidArgumentError`, because you must feed a value for
# a `tf.placeholder()` when evaluating a tensor that depends on it.
sess.run(y)
# Raises `ValueError`, because the shape of `37.0` does not match the shape
# of placeholder `x`.
sess.run(y, {x: 37.0})tf.Session.run also accepts an optional options argument that enables you to specify options about the call, and an optional run_metadata argument that enables you to collect metadata about the execution. For example, you can use these options together to collect tracing information about the execution:
y = tf.matmul([[37.0, -23.0], [1.0, 4.0]], tf.random_uniform([2, 2]))
with tf.Session() as sess:
# Define options for the `sess.run()` call.
options = tf.RunOptions()
options.output_partition_graphs = True
options.trace_level = tf.RunOptions.FULL_TRACE
# Define a container for the returned metadata.
metadata = tf.RunMetadata()
sess.run(y, options=options, run_metadata=metadata)
# Print the subgraphs that executed on each device.
print(metadata.partition_graphs)
# Print the timings of each operation that executed.
print(metadata.step_stats)8,Visualizing your graph
TensorFlow includes tools that can help you to understand the code in a graph. The graph visualizer is a component of TensorBoard that renders the structure of your graph visually in a browser. The easiest way to create a visualization is to pass a tf.Graph when creating the tf.summary.FileWriter:
TensorFlow包含的工具可以帮助您理解图表中的代码。 图表可视化器是TensorBoard的一个组件,它在浏览器中可视化地呈现图形的结构。 创建可视化的最简单方法是在创建tf.summary.FileWriter时传递tf.Graph:
# Build your graph.
x = tf.constant([[37.0, -23.0], [1.0, 4.0]])
w = tf.Variable(tf.random_uniform([2, 2]))
y = tf.matmul(x, w)
# ...
loss = ...
train_op = tf.train.AdagradOptimizer(0.01).minimize(loss)
with tf.Session() as sess:
# `sess.graph` provides access to the graph used in a `tf.Session`.
writer = tf.summary.FileWriter("/tmp/log/...", sess.graph)
# Perform your computation...
for i in range(1000):
sess.run(train_op)
# ...
writer.close()Note: If you are using a tf.estimator.Estimator, the graph (and any summaries) will be logged automatically to the model_dir that you specified when creating the estimator.
You can then open the log in tensorboard, navigate to the “Graph” tab, and see a high-level visualization of your graph’s structure. Note that a typical TensorFlow graph—especially training graphs with automatically computed gradients—has too many nodes to visualize at once. The graph visualizer makes use of name scopes to group related operations into “super” nodes. You can click on the orange “+” button on any of these super nodes to expand the subgraph inside.
然后,您可以打开tensorboard中的日志,导航到“图形”选项卡,并查看图形结构的高级可视化。 请注意,一个典型的TensorFlow图 - 特别是具有自动计算梯度的训练图 - 具有太多的节点来一次可视化。 图表可视化器使用名称范围将相关操作分组为“超级”节点。 你可以点击这些超级节点上的橙色“+”按钮来展开里面的子图。

9,Programming with multiple graphs
Note: When training a model, a common way of organizing your code is to use one graph for training your model, and a separate graph for evaluating or performing inference with a trained model. In many cases, the inference graph will be different from the training graph: for example, techniques like dropout and batch normalization use different operations in each case. Furthermore, by default utilities like tf.train.Saver use the names of tf.Variable objects (which have names based on an underlying tf.Operation) to identify each variable in a saved checkpoint. When programming this way, you can either use completely separate Python processes to build and execute the graphs, or you can use multiple graphs in the same process. This section describes how to use multiple graphs in the same process.
注意:在训练模型时,组织代码的常用方法是使用一个图形来训练模型,并使用单独的图形来评估或执行训练模型的推理。 在许多情况下,推理图将与训练图不同:例如,丢失和批量归一化等技术在每种情况下使用不同的操作。 此外,默认情况下,tf.train.Saver等实用程序使用tf.Variable对象的名称(名称基于tf.Operation)来标识保存的检查点中的每个变量。 当以这种方式进行编程时,可以使用完全独立的Python进程来构建和执行图形,也可以在同一进程中使用多个图形。 本节介绍如何在同一个进程中使用多个图表。
As noted above, TensorFlow provides a “default graph” that is implicitly passed to all API functions in the same context. For many applications, a single graph is sufficient. However, TensorFlow also provides methods for manipulating the default graph, which can be useful in more advanced used cases. For example:
A tf.Graph defines the namespace for tf.Operation objects: each
operation in a single graph must have a unique name. TensorFlow will
“uniquify” the names of operations by appending “_1”, “_2”, and so
on to their names if the requested name is already taken. Using
multiple explicitly created graphs gives you more control over what
name is given to each operation.
tf.Graph为tf.Operation对象定义了名称空间:each
在单个图表中操作必须具有唯一的名称。 TensorFlow将会
通过附加“_1”,“_2”等来“统一”操作名称
如果所请求的名字已经被占用,则在他们的名字上。运用
多个显式创建的图形可以让您更好地控制什么
名字被赋予每个操作。The default graph stores information about every tf.Operation and
tf.Tensor that was ever added to it. If your program creates a large
number of unconnected subgraphs, it may be more efficient to use a
different tf.Graph to build each subgraph, so that unrelated state
can be garbage collected.
默认图表存储关于每个tf.Operation和的信息
tf.Tensor曾被添加到它。 如果你的程序创建一个大的
不连接子图的数量,使用a可能更有效率
不同的tf.Graph建立每个子图,这样无关的状态
可以被垃圾收集。
You can install a different tf.Graph as the default graph, using the tf.Graph.as_default context manager:
g_1 = tf.Graph()
with g_1.as_default():
# Operations created in this scope will be added to `g_1`.
c = tf.constant("Node in g_1")
# Sessions created in this scope will run operations from `g_1`.
sess_1 = tf.Session()
g_2 = tf.Graph()
with g_2.as_default():
# Operations created in this scope will be added to `g_2`.
d = tf.constant("Node in g_2")
# Alternatively, you can pass a graph when constructing a `tf.Session`:
# `sess_2` will run operations from `g_2`.
sess_2 = tf.Session(graph=g_2)
assert c.graph is g_1
assert sess_1.graph is g_1
assert d.graph is g_2
assert sess_2.graph is g_2To inspect the current default graph, call tf.get_default_graph, which returns a tf.Graph object:
# Print all of the operations in the default graph.
g = tf.get_default_graph()
print(g.get_operations())