2019腾讯广告算法大赛题目理解与数据探索(含代码)
2019腾讯广告算法大赛题目理解与数据探索
1.题目介绍
1.1 背景介绍
广告曝光预估的目的是在广告主创建新广告和修改广告设置时,为广告主提供 未来的广告曝光效果参考。通过这个预估参考,广告主能避免盲目的优化尝试,有效缩短广 告的优化周期,降低试错成本,使广告效果尽快达到广告主的预期范围。比赛中使用的数据 经过脱敏处理,通过本次大赛,我们旨在挑选出更为优秀的曝光预估算法以及遴选出杰出的 社交广告算法达人。
1.2 赛题介绍
腾讯效果广告采用的是 GSP(Generalized Second-Price)竞价机制,广告的实际曝光取 决于广告的流量覆盖大小和在竞争广告中的相对竞争力水平。其中广告的流量覆盖取决于广 告的人群定向(匹配对应特征的用户数量)、广告素材尺寸(匹配的广告位)以及投放时段、 预算等设置项。
测试集是新的一 批广告设置(有完全新的广告 id,也有老的广告 id 修改了设置),要求预估这批广告的日曝 光 。
1.3 注意点
- 目标为预测广告在特定配置下指定日期的曝光量
- 数据没有直接给出label,需要自己从曝光日志数据中统计每个广告在每天的曝光量
2.数据介绍
2.1 所有数据集
(以下图片源于网友分享)

共5部分数据,其中“历史曝光日志数据”、“用户特征属性”、“广告静态数据”和“广告操作数据”可用于构造训练集
3.数据探索
3.1 历史曝光日志数据
1)读取数据
exposure_log_data_df = pd.read_csv('testA/totalExposureLog.out', header=None, sep='\t')
exposure_log_data_df.columns = [
'广告请求 id',
'广告请求时间',
'广告位 id',
'用户 id',
'广告 id',
'曝光广告素材尺寸',
'曝光广告出价 bid',
'曝光广告 pctr',
'曝光广告 quality_ecpm',
'曝光广告 totalEcpm',
]
一条记录代表一条广告的曝光。
2)去重重复数据。
一个请求可能在不同广告位曝光多个不同广告,如果同请求id同一广告位有多条记录(网络不好时可能会出现多条记录的现象),则为重复数据,应该先过滤重复广告。
exposure_log_data_df = exposure_log_data_df.drop_duplicates(
subset=['广告请求 id', '广告位 id'], keep='last')
3)曝光时间
exposure_log_data_df['广告请求时间'] = exposure_log_data_df['广告请求时间'] + 28800
exposure_log_data_df['广告请求时间'] = pd.to_datetime(
exposure_log_data_df['广告请求时间'], unit='s')
exposure_log_data_df['广告请求日期'] = exposure_log_data_df['广告请求时间'].apply(
lambda x: x.strftime('%Y%m%d'))
exposure_log_data_df['DayOfWeek'] = exposure_log_data_df['广告请求时间'].apply(
lambda x: x.dayofweek)
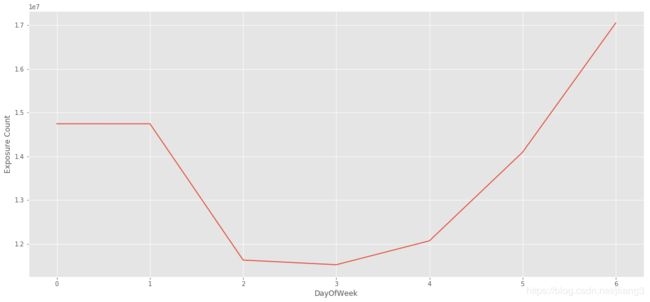
从下图可以看出,曝光量与“星期几”有关系。因此统计曝光量时要把时间转换成北京时间,否则训练集数据中的曝光量不准确。
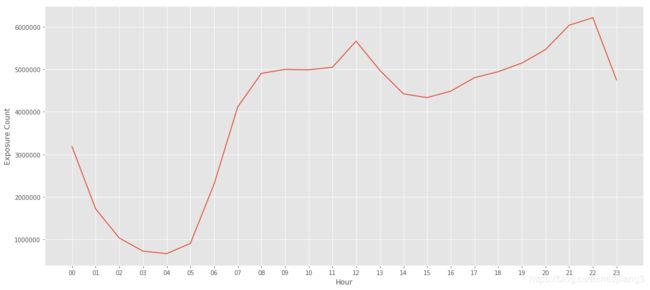
下图是把曝光时间+8h后每个小时的曝光量,0-5点之间的曝光量非常小,12点和22点的曝光量最大,符合常识,所以曝光时间应该+8h。
4)广告出价
广告出价特征对预测目标曝光值非常重要,曝光日志中有每次广告曝光对应的出价特征,广告动态配置数据中也有出价特征。另外,广告配置数据一天内可能会被多次修改,如果只使用某个设置中的出价特征会影响最终的预测,所以此处使用广告曝光日志中每个广告在每天的出价的均值作为当天的出价特征。
5)类标值曝光量统计
exposure_group_df = exposure_log_data_df.groupby(['广告 id', '广告请求日期'])\
.agg({'用户 id': 'count'}).reset_index().rename(columns={'用户 id': '曝光数'})
3.2 用户特征属性数据
1)读取数据
user_info_df = pd.read_csv('testA/user_data', header=None, sep='\t')
user_info_df.columns = [
'用户 id',
'年龄(Age)',
'性别(Gender)',
'地域(area)',
'婚恋状态(Status)',
'学历(Education)',
'消费能力(ConsuptionAbility)',
'设备(device)',
'工作状态(work)',
'连接类型(ConnectionType)',
'行为兴趣(behavior)',
]
2)用户数据使用
由于广告曝光日志只包含部分用户数据,并不是全量的用户数据,所以很难直接联合曝光数据来使用用户数据。此处可以结合广告配置数据中的人群定向字段来统计每个配置中人群定向单个特征覆盖的用户数量以及人群定向所有特征覆盖的用户数量,这些特征在后续的建模中被证明贡献比较大。但是这些特征的计算比较复杂,计算量比较大,后续文章会介绍并发计算的方法。
3.3 广告静态数据
1)读取数据
ad_static_feature_df = pd.read_csv('testA/ad_static_feature.out', header=None, sep='\t')
ad_static_feature_df.columns = [
'广告 id',
'创建时间',
'广告账户 id',
'商品 id',
'商品类型',
'广告行业 id',
'素材尺寸',
]
2)时间格式转换
每个广告有一条静态数据,后面需要使用根据广告创建时间来联合广告操作数据,所以需要进行格式转换,以便后续比较时间先后。
ad_static_feature_df['创建时间'] = ad_static_feature_df['创建时间'] + 28800
ad_static_feature_df['创建时间'] = pd.to_datetime(
ad_static_feature_df['创建时间'], unit='s')
ad_static_feature_df['创建日期'] = ad_static_feature_df['创建时间'].apply(
lambda x: x.strftime('%Y%m%d'))
3.4 广告操作数据
1)读取数据
ad_operation_df = pd.read_csv('testA/ad_operation.dat', header=None, sep='\t')
ad_operation_df.columns = [
'广告 id',
'创建/修改时间',
'操作类型',
'修改字段',
'操作后的字段值',
]
2)脏数据处理
创建/修改时间存在两种脏数据“20190230000000”和“0”,此处把“20190230000000”修改成“20190228000000”,把“0”修改成“19700101000000”。
invalid_time_dict = {
20190230000000: 20190228000000,
0: 19700101000000,
}
ad_operation_df['创建/修改时间'].fillna(0, inplace=True)
ad_operation_df['创建/修改时间'] = ad_operation_df['创建/修改时间'].apply(
lambda x: invalid_time_dict[x] if x in invalid_time_dict else x)
3)时间格式转换
ad_operation_df['创建/修改时间'] = ad_operation_df['创建/修改时间'].progress_apply(
lambda x: pd.Timestamp(x))
ad_operation_df['创建/修改日期'] = ad_operation_df['创建/修改时间'].progress_apply(
lambda x: x.strftime('%Y%m%d'))
4)广告操作特征
每条广告操作数据为一条创建/修改记录,而每条创建/修改记录只包含一个字段。广告配置包含“广告状态”、“出价(单位分)”、“时段设置”和“人群定向”四个特征,广告配置创建后的特征由多条记录组成;每次广告配置修改只会修改一个特征,所以另外3个特征保持修改前的特征。
创建广告配置的特征
ad_create_operation_df = ad_operation_df[ad_operation_df['操作类型'] == 2]
print('广告创建操作广告shape={}'.format(ad_create_operation_df.shape))
display(ad_create_operation_df.head(3))
create_ad_id_list = list(ad_create_operation_df['广告 id'].unique())
print('新建操作广告数据量={}'.format(len(create_ad_id_list)))
ad_create_operation_feature_df = pd.DataFrame({'广告 id': create_ad_id_list})
ad_create_operation_feature_df['广告状态'] = 1
field_name_value_dict = {
'广告状态': 1,
'出价(单位分)': 2,
'时段设置': 3,
'人群定向': 4,
}
field_name_list = ['出价(单位分)', '时段设置', '人群定向',]
for field_name in field_name_list:
df = ad_create_operation_df[ad_create_operation_df['修改字段']==field_name_value_dict[field_name]]
ad_create_operation_feature_df = pd.merge(ad_create_operation_feature_df,
df.loc[:, ['广告 id', '操作后的字段值']].rename(columns={'操作后的字段值': field_name}),
on='广告 id', how='left')
# 从广告静态数据中获取创建时间
ad_create_operation_feature_df = pd.merge(
ad_create_operation_feature_df, ad_static_feature_df.loc[:, ['广告 id', '创建时间']]
.rename(columns={'创建时间': '创建/修改时间'}), on='广告 id', how='left')
print('shape={}'.format(ad_create_operation_feature_df.shape))
print('info={}'.format(ad_create_operation_feature_df.info()))
display(ad_create_operation_feature_df.head(5))
修改广告配置的特征
def create_ad_operation_feature_df(modify_ad_operation_df, ad_create_operation_feature_df,
update_attr_value_list, update_attr_name_list):
"""
@ update_attr_value_list:修改字段取值
@ update_attr_name_list:修改字段名字
update_attr_value_list和update_attr_name_list一一对应
"""
print('modify_ad_operation_df shape={}'.format(modify_ad_operation_df.shape))
create_operation_df = ad_create_operation_feature_df.drop('创建/修改时间', axis=1)
feature_df_list = []
for value, name in zip(update_attr_value_list, update_attr_name_list):
df = modify_ad_operation_df[modify_ad_operation_df['修改字段']==value]
df = df.loc[
:, ['广告 id', '创建/修改时间', '创建/修改日期', '操作后的字段值', '修改字段']]
print('{}("修改字段"=={})shape={}'.format(name, value, df.shape))
feature_df = pd.merge(df, create_operation_df, on='广告 id', how='left')
feature_df[name] = feature_df['操作后的字段值']
feature_df_list.append(feature_df)
feature_df.drop(['操作后的字段值'], axis=1, inplace=True)
print('修改操作“{}”shape={}'.format(name, feature_df.shape))
combine_feature_df = pd.concat(feature_df_list)
print('shape={}'.format(combine_feature_df.shape))
print('info={}'.format(combine_feature_df.info()))
display(combine_feature_df.head())
return combine_feature_df
ad_modify_operation_df = ad_operation_df[(ad_operation_df['操作类型'] == 1)]
ad_modify_operation_df = ad_modify_operation_df[
ad_modify_operation_df['广告 id'].isin(create_ad_id_list)]
ad_modify_operation_feature_df = create_ad_operation_feature_df(
ad_modify_operation_df, ad_create_operation_feature_df,
[1, 2, 3, 4], ['广告状态', '出价(单位分)', '人群定向', '时段设置'])
使用拉链表的思想获取每个广告每天对应的广告配置特征
广告配置本次修改的配置为开始时间,同一广告下次修改的时间为配置结束时间,如果没有下次修改,则结束时间设置为一个很大的值。每个广告每天曝光值对应的广告配置为离当天0点最近并且修改时间小于当天0点的一次广告配置创建/修改。
合并所有广告配置,并计算广告开始&结束生效时间
ad_operation_feature_list = [
'广告 id', '创建/修改时间', '广告状态', '出价(单位分)', '时段设置', '人群定向'
]
ad_operation_feature_df = pd.concat([
ad_create_operation_feature_df.loc[:, ad_operation_feature_list],
ad_modify_operation_feature_df.loc[:, ad_operation_feature_list]])
print('shape={}'.format(ad_operation_feature_df.shape))
ad_operation_feature_df = ad_operation_feature_df[~ad_operation_feature_df['创建/修改时间'].isnull()]
print('排除没有创建日期后shape={}'.format(ad_operation_feature_df.shape))
ad_operation_feature_df['创建/修改日期'] = ad_operation_feature_df['创建/修改时间'].apply(
lambda x: x if x is None else x.strftime('%Y%m%d'))
ad_operation_feature_df = ad_operation_feature_df.sort_values(
by=['广告 id', '创建/修改时间']).reset_index(drop=True)
ad_operation_feature_group_df = ad_operation_feature_df.loc[
:, ['广告 id', '创建/修改时间', ]].groupby(['广告 id'])
display(ad_operation_feature_df.head())
# 计算结束时间
shift_df = ad_operation_feature_group_df.shift(-1, axis=0)
shift_df = shift_df.loc[:, ['创建/修改时间']].rename(columns={'创建/修改时间': '结束时间'})
ad_operation_feature_df = pd.concat([ad_operation_feature_df, shift_df], axis=1)
DEFAULT_END_TIME = pd.Timestamp('2019-04-27 00:00:00')
ad_operation_feature_df['结束时间'].fillna(DEFAULT_END_TIME, inplace=True)
ad_operation_feature_df['结束日期'] = ad_operation_feature_df['结束时间'].apply(
lambda x: x.strftime('%Y%m%d'))
计算每个广告在每天广告配置数据
exposure_feature_df = pd.merge(exposure_group_df, ad_operation_feature_df,
on='广告 id', how='left')
exposure_feature_df = exposure_feature_df[~exposure_feature_df['创建/修改时间'].isnull()]
exposure_feature_df = exposure_feature_df[(
(exposure_feature_df['广告请求日期'] >= exposure_feature_df['创建/修改时间'])
& (exposure_feature_df['广告请求日期'] < exposure_feature_df['结束时间']))]
exposure_feature_df['广告状态'] = exposure_feature_df['广告状态'].astype(int)
exposure_feature_df = exposure_feature_df[exposure_feature_df['广告状态'] == 1]
3.5 测试数据
1)读取数据
test_feature_df = pd.read_csv('testA/test_sample.dat', header=None, sep='\t')
test_feature_df.columns = [
'样本 id',
'广告 id',
'创建时间',
'素材尺寸',
'广告行业 id',
'商品类型',
'商品 id',
'广告账户 id',
'时段设置',
'人群定向',
'出价(单位分)',
]
2)时间格式转换
test_feature_df['创建时间'] = test_feature_df['创建时间'] + 28800
test_feature_df['创建时间'] = pd.to_datetime(test_feature_df['创建时间'], unit='s')
test_feature_df['创建日期'] = test_feature_df['创建时间'].apply(lambda x: x.strftime('%Y%m%d'))
3)测试集探索
- A轮测试集中共20290条记录需要预测。
- 1954个广告的不同配置,其中1360个是老广告,594个是新广告。
- 同一个广告只有出价不一样,其他配置完全相同。
4.评估方式理解
4.1 准确性指标
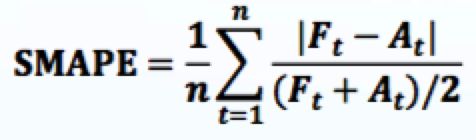
Ft为预估的广告曝光值,At为真实的曝光值,SMAPE越小越好。
实际使用时建议使用最小化SMAPE作为评估函数,如XGBoost自定义评估函数:
def smape(y_true, y_pred):
return np.mean(np.abs(y_pred - y_true) / ((y_pred + y_true)/2))
def xgb_eval_metric_smape(preds, dtrain):
return 'smape', smape(dtrain.get_label(), preds)
4.2 出价单调相关性指标
由于竞价机制的特性,在广告其他特征不变的前提下,随着出价的提升,预估曝光值也
单调提升才符合业务直觉。
从上面的测试集的数据探索中,我们可知道测试集中同一个广告只有出价特征不一样,其他配置都一样。所以在竞价时,只有符合单调性时,广告投放者才有可能愿意出更高的价格投放广告。
单个广告相关性指标:
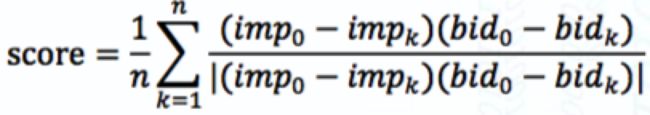
所有预估广告的单调性得分:

imp为曝光量,bid为出价值。bid0不是最低出价,而是同一个广告中所有小于bidk的出价;imp0不是最低出价对应的曝光量,而是同一个广告中所有小于bidk的出价所对应的曝光量。
单调性实验:
1)实验一:以广告id为分组,按出价进行排序,以这里的排序得到的序号作为曝光量,线上成绩是77分。
2)实验二:以广告id为分组,按出价进行排序,最低出价对应的曝光量为1,广告的其余出价曝光量为2,线上成绩是52.8分。
单调性评分函数:
def get_mono_score(result_df, print_log=False):
res_ad_id_group_df = result_df.groupby(['广告 id'])
result_df['出价排序'] = res_ad_id_group_df['出价(单位分)'].rank(ascending=True, method='dense')
result_df['出价排序'] = result_df['出价排序'].astype(int)
max_rank = result_df['出价排序'].max()
df_list = []
for i in range(1, max_rank):
standard_df = result_df[result_df['出价排序']==i]
standard_df = standard_df.loc[:, ['广告 id', '样本 id', '出价(单位分)', '曝光量']]\
.rename(columns={'样本 id': '基准样本 id', '出价(单位分)':'基准出价(单位分)', '曝光量': '基准曝光量'})
df = result_df[result_df['出价排序']>i]
df = pd.merge(df, standard_df, left_on='广告 id', right_on='广告 id', how='left')
df_list.append(df)
combine_df = pd.concat(df_list)
if print_log is True:
print('combine_df shape={}'.format(combine_df.shape))
display(combine_df.head())
combine_df['score'] = combine_df.apply(
lambda x: (
((x['基准曝光量']-x['曝光量'])* (x['基准出价(单位分)']-x['出价(单位分)']))/
abs((x['基准曝光量']-x['曝光量'])* (x['基准出价(单位分)']-x['出价(单位分)']))
), axis=1
)
monoscore = combine_df.groupby(by='广告 id')['score'].mean().mean()
if print_log is True:
print("经过相关性计算成绩为:"+str(monoscore))
print("预估相关性部分成绩为:"+ str(60*(monoscore+1)/2))
4.3 最终得分
上述两个指标值域和趋势都不同,为了比赛评分简便,会将上述两个指标各自归一化后 再加权求和得到一个最终得分。
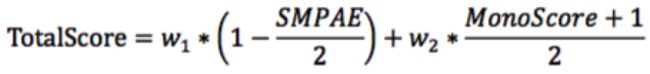
此处w1=40,w2=60,单调性大于准确性。
单调性调整方法:
1)imp + r * w
imp为预测的曝光量,r为同一个广告按出价排序得到的序号,w为权重值,有人建议w=0.001,实际使用时,这种方式调整会严重影响准确性,效果不好。
2)以广告id为分组,使用出价进行排序,从低到高遍历每个出价对应的曝光值,当曝光值小于前一个出价对应的曝光值时,把当前曝光量设置为上一出价的曝光量+0.01。
实际使用时发现对准确性影响最小,单调性的60分稳拿。
def adjust_mono(res_df, w=0.01):
df = res_df.sort_values(by=['广告 id', '出价(单位分)'])
df['曝光量'] = df['score']
need_adjust_count = 1
while True:
group_df = df.groupby(['广告 id'])
shift_df = group_df.shift(1, axis=0).loc[:, ['曝光量']].rename(
columns={'曝光量': '上一曝光量'})
df = pd.concat([df, shift_df], axis=1)
need_adjust_count = df[df['曝光量'] < df['上一曝光量']].shape[0]
log.info(TAG, '需要调整的数量={}'.format(need_adjust_count))
if need_adjust_count == 0:
break
df.loc[df['上一曝光量'] > df['曝光量'], '曝光量'] = df.loc[df['上一曝光量'] > df['曝光量'], '上一曝光量'] + w
df.drop(['上一曝光量'], axis=1, inplace=True)
df = df.sort_values(by=['样本 id',])
display(df.head())
return df
3)以广告id为分组,使用出价进行排序,从低到高遍历每个出价对应的曝光值,当曝光值大于下一个出价对应的曝光值时,把当前曝光量设置为下一出价的曝光量-0.01。
实际使用时发现对准确性影响比较小,影响略高于上一种方法,单调性的60分稳拿。
def adjust_mono(res_df, test_df, w=0.01):
df = res_df.sort_values(by=['广告 id', '出价(单位分)'])
df['曝光量'] = df['score']
need_adjust_count = 1
while True:
group_df = df.groupby(['广告 id'])
shift_df = group_df.shift(-1, axis=0).loc[:, ['曝光量']].rename(
columns={'曝光量': '下一曝光量'})
df = pd.concat([df, shift_df], axis=1)
need_adjust_count = df[df['曝光量'] > df['下一曝光量']].shape[0]
log.info(TAG, '需要调整的数量={}'.format(need_adjust_count))
if need_adjust_count == 0:
break
df.loc[df['曝光量'] > df['下一曝光量'], '曝光量'] = df.loc[df['曝光量'] > df['下一曝光量'], '下一曝光量'] - w
df.drop(['下一曝光量'], axis=1, inplace=True)
df = df.sort_values(by=['样本 id',])
return df