hue集成Oozie工作流调度之Spark2 Workflow
一、环境准备
CDH5.15.0,spark2.3.0,hue3.9.0
注意:由于使用的是CDH集群,默认的spark版本为1.6.0,又通过parcel包的方式安装了spark2.3.0,此时集群存在两个spark版本。而hue集成的是spark1.6,需要将spark2的jar包和oozie-sharelib-spark*.jar上传到hue的share lib中,目录 为:/user/oozie/share/lib/lib_20181015151907/spark2
1.上传jar包
[root@sdw2 jars]# pwd
/opt/cloudera/parcels/SPARK2/lib/spark2/jars
[root@sdw2 jars]# sudo -uhdfs hdfs dfs -put * /user/oozie/share/lib/lib_20181015151907/spark2
[root@sdw2 jars]# cd /opt/cloudera/parcels/CDH/lib/oozie/oozie-sharelib-yarn/lib/spark/
[root@sdw2 spark]# pwd
/opt/cloudera/parcels/CDH/lib/oozie/oozie-sharelib-yarn/lib/spark
[root@sdw2 spark]# sudo -uhdfs hdfs dfs -put oozie-sharelib-spark*.jar /user/oozie/share/lib/lib_20181015151907/spark22.修改属主和权限
[root@sdw2 spark]# sudo -uhdfs hdfs dfs -chown -R oozie:oozie /user/oozie/share/lib/lib_20181015151907/spark2
[root@sdw2 spark]# sudo -uhdfs hdfs dfs -chmod -R 775 /user/oozie/share/lib/lib_20181015151907/spark23.更新sharelib
[root@sdw1 init.d]# oozie admin --oozie http://dw-greenplum-2:11000/oozie/ --sharelibupdate
[ShareLib update status]
sharelibDirOld = hdfs://dw-greenplum-2:8020/user/oozie/share/lib/lib_20181015151907
host = http://dw-greenplum-2:11000/oozie
sharelibDirNew = hdfs://dw-greenplum-2:8020/user/oozie/share/lib/lib_20181015151907
status = Successful
[root@sdw1 init.d]# oozie admin --oozie http://dw-greenplum-2:11000/oozie/ --shareliblist
[Available ShareLib]
hive
spark2
distcp
mapreduce-streaming
spark
oozie
hcatalog
hive2
sqoop
pig
二、问题描述
描述:在HDFS上有订单数据order.txt文件,文件字段的分割符号",",样本数据如下:
| Order_00001,Pdt_01,222.8 Order_00001,Pdt_05,25.8 Order_00002,Pdt_03,522.8 Order_00002,Pdt_04,122.4 Order_00002,Pdt_05,722.4 Order_00003,Pdt_01,222.8 |
其中字段依次表示订单id,商品id,交易额
问题:使用sparkcore,求每个订单中成交额最大的商品id,并将求得的结果保存到hive表中
三、代码
package com.company.sparkcore
import org.apache.spark.sql.Row
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.{SparkConf, SparkContext}
object TopOrderItemCluster {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("top n order and item")
val sc = new SparkContext(conf)
val hctx = new HiveContext(sc)
//数据在HDFS上的目录为:/user/hdfs/spark_data/data.txt
val orderData = sc.textFile("spark_data/data.txt")
val splitOrderData = orderData.map(_.split(","))
val mapOrderData = splitOrderData.map { arrValue =>
val orderID = arrValue(0)
val itemID = arrValue(1)
val total = arrValue(2).toDouble
(orderID, (itemID, total))
}
val groupOrderData = mapOrderData.groupByKey()
//groupOrderData.foreach(x => println(x))
// (Order_00003,CompactBuffer((Pdt_01,222.8)))
// (Order_00002,CompactBuffer((Pdt_03,522.8), (Pdt_04,122.4), (Pdt_05,722.4)))
// (Order_00001,CompactBuffer((Pdt_01,222.8), (Pdt_05,25.8)))
val topOrderData = groupOrderData.map(tupleData => {
val orderid = tupleData._1
val maxTotal = tupleData._2.toArray.sortWith(_._2 > _._2).take(1)
(orderid, maxTotal)
}
)
topOrderData.foreach(value =>
println("最大成交额的订单ID为:" + value._1 + " ,对应的商品ID为:" + value._2(0)._1)
// 最大成交额的订单ID为:Order_00003 ,对应的商品ID为:Pdt_01
// 最大成交额的订单ID为:Order_00002 ,对应的商品ID为:Pdt_05
// 最大成交额的订单ID为:Order_00001 ,对应的商品ID为:Pdt_01
)
//构造出元数据为Row的RDD
val RowOrderData = topOrderData.map(value => Row(value._1, value._2(0)._1))
//构建元数据
val structType = StructType(Array(
StructField("orderid", StringType, false),
StructField("itemid", StringType, false))
)
//转换成DataFrame
val orderDataDF = hctx.createDataFrame(RowOrderData, structType)
orderDataDF.registerTempTable("tmptable")
hctx.sql("CREATE TABLE IF NOT EXISTS orderid_itemid(orderid STRING,itemid STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'")
hctx.sql("insert into orderid_itemid select * from tmptable")
}
}
四、在集群上运行
将打好的jar包放在集群上,测试提交spark作业
##提交脚本为submit1.sh
spark2-submit \
--class com.yeexun.sparkcore.TopOrderItemCluster \
--master yarn \
--deploy-mode cluster \
/opt/software/myspark-1.0-SNAPSHOT.jar
五、通过hue创建spark的workflow
1.创建workflow
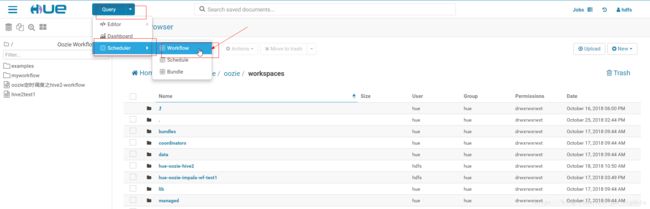
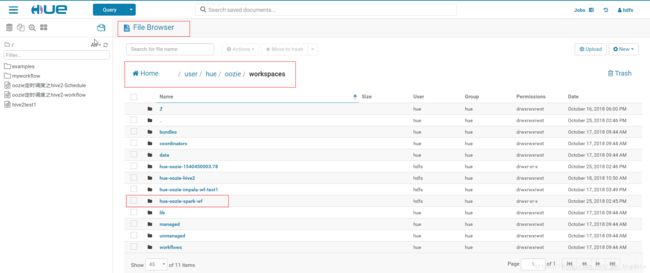
2.点击workflow之后,会在/user/hue/oozie/workspaces文件夹下自动创建一个名字为hue-oozie-*********.**文件夹,该文件夹下存在一个lib文件夹,修改该文件夹名字为hue-oozie-spark-wf(可以自行修改,也可以不修改)
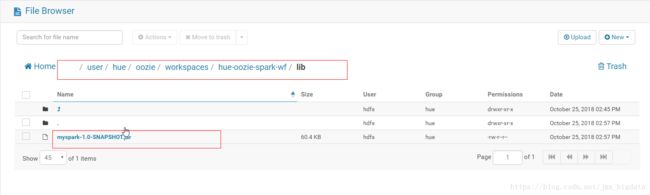
3.将打包好的jar包上传到/user/hue/oozie/workspaces/hue-oozie-spark-wf/lib文件夹下
4.创建spark的workflow

5.点击![]() 编辑workflow的配置,添加属性oozie.action.sharelib.for.spark=spark2
编辑workflow的配置,添加属性oozie.action.sharelib.for.spark=spark2

6.点击![]() 保存,点击右上角的
保存,点击右上角的![]() 运行workflow
运行workflow
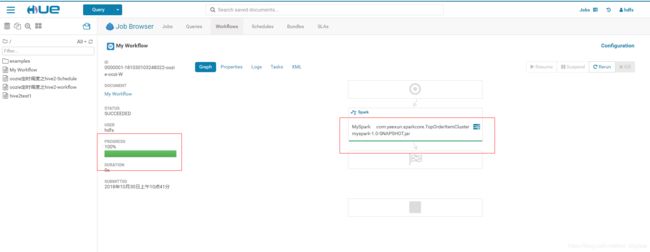
六、报错问题
如果点击运行之后报错:
.
.
org.apache.spark.SparkException: Exception when registering SparkListener
.
.
.
.
Caused by:java.lang.ClassNotFoundException:com.cloudera.spark.lineage.ClouderaNavigatorListener
.
.
解决办法:
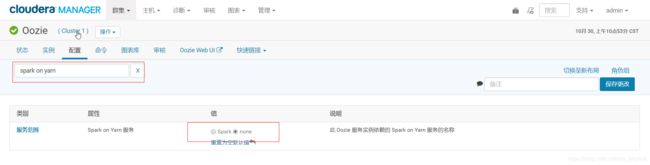
通过cloudera manager修改oozie的配置Spark on Yarn,将其值修改为none,保存配置。