一个简单的站内搜索引擎的实现
这学期的信息检索课程的实验要求做一个简单的站内搜索引擎,用来搜索山东大学新闻网(http://www.view.sdu.edu.cn/)的新闻内容。具体要求如下:

今天终于考完了这学期的最后一门计算机图形学的考试,现在有时间来将这个实验发表到博客了。
需求分析
该项目可以划分成几个部分:网页的爬取、网页信息的整理存储、索引的建立、搜索的实现以及结果排序和最后的Web实现。
网页的爬取要保证在山东大学新闻网站内进行爬取。将爬取的网页中需要提取的内容有新闻标题、新闻发布时间、新闻正文以及该网页的URL地址。每个新闻建立一个txt文本文件,并将以上四部分内容保存在该文件中。索引的建立与搜索的实验要围绕这四个方面进行。在最后的结果排序中要体现时效性,并且最好尽量向百度靠齐。最后的web界面要做到简洁、美观、大方。
实验环境
1、开发语言
Python
Java
HTML
JSP
2、开发软件与服务器
eclipse
Tomcat
3、操作系统
Windows10 专业版
4、测试浏览器
Google Chrome
功能实现
系统的整体结构如下图所示。爬虫爬取的网页使用正则表达式进行内容提取生成文本文件之后,用分词器处理建立索引,构成索引库。而用户输入的查询语句使用与构建索引时相同的分词器进行分词之后,搜索模块从索引库中进行搜索并返回结果。
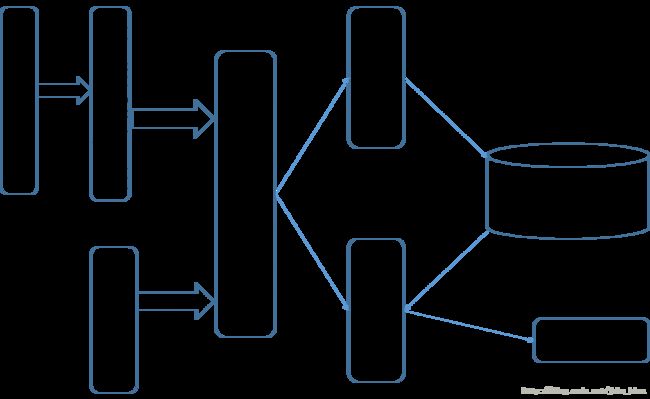
网页的爬取与网页信息的提取
对山东大学新闻网的网页爬取用Python语言实现。山东大学新闻网主页截图如下图所示,首先要对山东大学新闻网进行分析,然后为其量身定做一个Spider,对其新闻网页进行爬取。

爬取得到的网页文件截图如下图所示
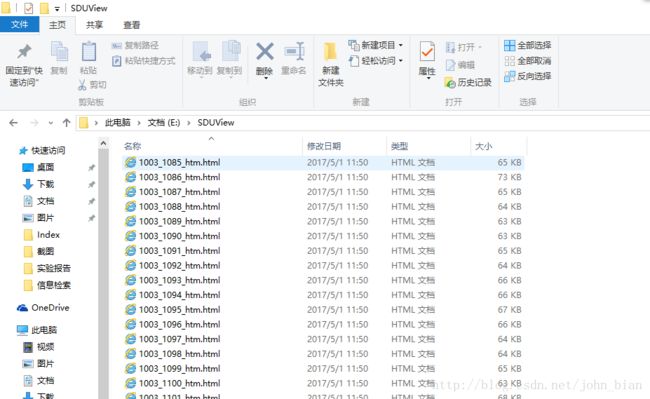
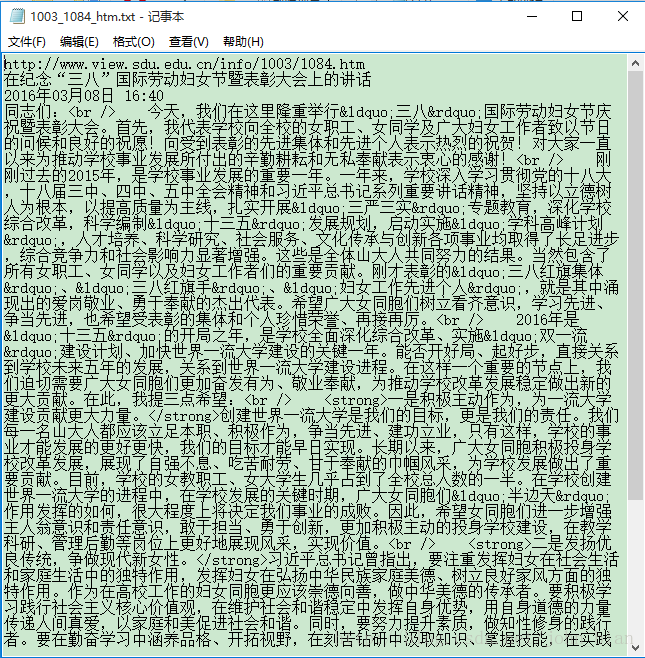
爬取网页并保存到本地之后还无法直接使用这些网页文件建立索引,因为这些网页源码中包含大量的HTML标记以及JavaScript脚本代码之类的东西,并且这些数据量远远大于我们所需要的对建立索引来讲有价值的的新闻信息。所以,接下来我们需要分析网页源码,并利用正则表达式对其内容进行提取。提取结果如下面二图所示。与之前图的对比中我们可以看出进行提取后的文本文件普遍比原HTML源码文件小了一个数量级。
索引的建立
索引的建立使用了Lucene提供的jar包。Document是Lucene建立索引的过程中的一个十分重要的类。Document的意义为文档,在Lucene中,它代表一种逻辑文件。Lucene本身无法对物理文件建立索引,而只能识别并处理Document类型的文件。在某些时候可以将一个Document与一个物理文件进行对应,用一个Document来代替一个物理文件,然而更多的时候,Document和物理的文件没有关系,它作为一种数据源的集合,向Lucene提供原始的要索引的文本内容。Lucene会从Document取出相关的数据源内容,并根据属性配置进行相应的处理。其中的索引的Document结构代码如下所示。各个域的作用如在代码注释中所示。
public class NewsDocument {
private static final String NEWS_ID = "newsId"; //该新闻的ID
private static final String NEWS_URL = "newsUrl"; //新闻的网址
private static final String NEWS_TITLE = "newsTitle"; //新闻标题
private static final String NEWS_DATE = "newsDate"; //新闻发布的时间
private static final String NEWS_BODY = "newsBody"; //新闻正文
private static final String INDEX_TIME = "indexTime"; //新闻被建立索引的时间
private static final String NEWS_DATE2 = "newsDate2"; //新闻发布的时间,用于排序
public static Document buildNewsDocument(News news, Long id){
Document doc = new Document();
Field identifier = new Field(NEWS_ID,id+"",Field.Store.YES,Field.Index.UN_TOKENIZED);
Field newsurl = new Field(NEWS_URL,news.getUrl(),Field.Store.YES,Field.Index.UN_TOKENIZED);
Field newstitle = new Field(NEWS_TITLE,news.getTitle(),Field.Store.YES,Field.Index.TOKENIZED);
Field newsdate = new Field(NEWS_DATE,news.getDate(),Field.Store.YES,Field.Index.TOKENIZED);
Field newsbody = new Field(NEWS_BODY,news.getBody(),Field.Store.YES,Field.Index.TOKENIZED);
long mills = System.currentTimeMillis();
Field indextime = new Field(INDEX_TIME,mills+"",Field.Store.YES,Field.Index.UN_TOKENIZED);
Field newsdate2 = new Field(NEWS_DATE2,news.getDate().substring(0, 4)+news.getDate().substring(5, 7),Field.Store.YES,Field.Index.TOKENIZED);
doc.add(identifier);
doc.add(indextime);
doc.add(newsbody);
doc.add(newsdate);
doc.add(newstitle);
doc.add(newsurl);
doc.add(newsdate2);
return doc;
}
}
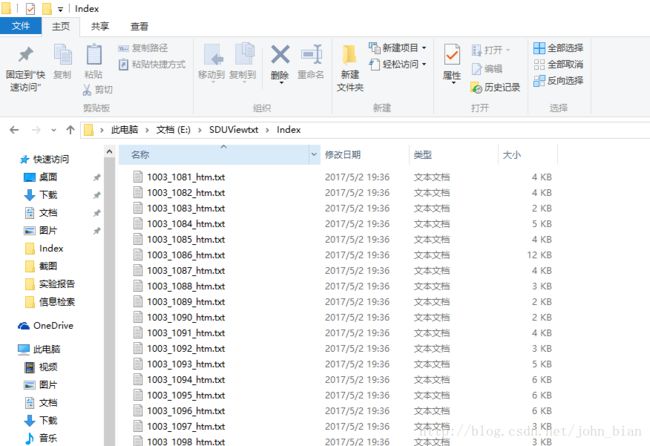
索引建立完成后存储目录的截图如下图所示。
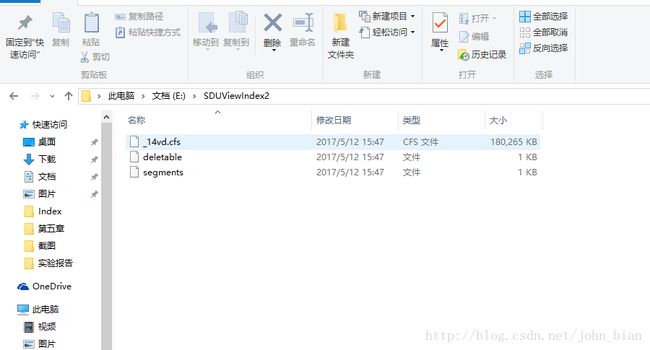
segment代表Lucene的一个完整索引段。通常,在一个索引中,会包含有多个segment。每个segment都有统一的前缀,这个签字追的确定是根据当前索引的Document的数量确立的。前缀名等于Document数量转化成36进制后,在前面加上下划线而组成。通常,在一个完整的索引中,即索引成功地建立完成后,有且只有一个“segment”文件,这个文件没有后缀,它记录了当前索引中所有segment的信息。
类似于Windows操作系统中的回收站,在Lucene的索引中,所有的文档被删除后并不是立刻从索引中取出,而是留待下一次合并索引或是对索引进行优化时才真正删除。而deletable文件就是用于实现这种功能的。
搜索的实现
用户输入一条语句,系统用与构建索引时相同的分词器对该语句进行分词,系统中我们用的是正向最大匹配方法来分词的。比如用户输入的语句为“习近平总书记重要讲话精神”,该分词器将会把该语句切分为“习近平”、“总书记”、“重要讲话”、“精神”这几个词。我们将分词所得的结果保存到一个ArrayList中,然后运用布尔搜索搜索含有这些词的文档。根据词频进行排序之后,取前500个文档进行时间月份的排序后返回结果,以保证搜索结果的时效性。这部分的关键代码如下所示。
public class NewsSearcher {
private final String INDEX_STORE_PATH = "E:\\SDUViewIndex2\\";
/**
* 获取分词结果
* @param analyzer
* @param s
* @return
* @throws Exception
*/
public ArrayList getAnalyzerResult(Analyzer analyzer, String s) throws Exception {
ArrayList result = new ArrayList<>();
StringReader reader=new StringReader(s);
TokenStream ts=analyzer.tokenStream(s, reader);
Token t=ts.next();
while (t != null) {
//System.out.print(t.termText()+" ");
result.add(t.termText());
t=ts.next();
}
return result;
}
/**
* 获取查询结果
* @param keys
* @return
* @throws Exception
*/
public Document[] getQueryResult(ArrayList keys) throws Exception{
IndexSearcher searcher = new IndexSearcher(INDEX_STORE_PATH);
BooleanQuery query = new BooleanQuery();
if(keys==null)
return null;
int key_length = keys.size();
TermQuery[] term = new TermQuery[key_length];
for(int i = 0;i web框架搭建
由于我们主要的索引构建以及搜索查询是用Java来实现的,因而在选择web开发环境的时候选择了JSP。eclipse下的工程目录结构如下图所示。
一个名为HomePageAction的servlet用来实现请求管理器,其处理GET和POST请求的方法代码如下所示。
//处理GET请求方法
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException
{
try {
//跳转到主界面
String input = request.getParameter("inputMessage");
if(input==null||input.trim().length()==0) {
response.sendRedirect("index.jsp");
}else{
Date begintime = new Date();
NewsSearcher searcher = new NewsSearcher();
ArrayList str = searcher.getAnalyzerResult(new MMAnalyzer(), input);
Document[] results = searcher.getQueryResult(str);
if(results.length==0){
request.setAttribute("noResult","没有找到相关内容");
RequestDispatcher dispatcher = request.getRequestDispatcher("noresult.jsp");
dispatcher.forward(request, response);
}else{
int totalnum = results.length;
request.setAttribute("newsNum",""+totalnum);
for(int i = 0;i 部署运行
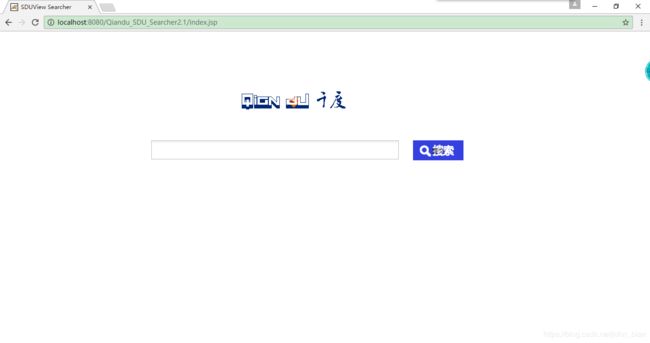
程序运行首页如下。
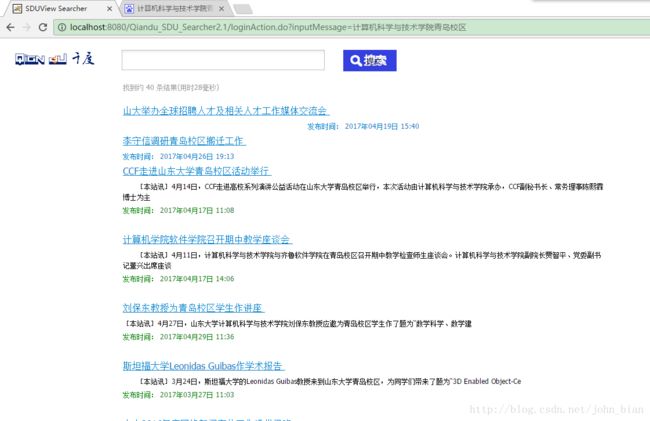
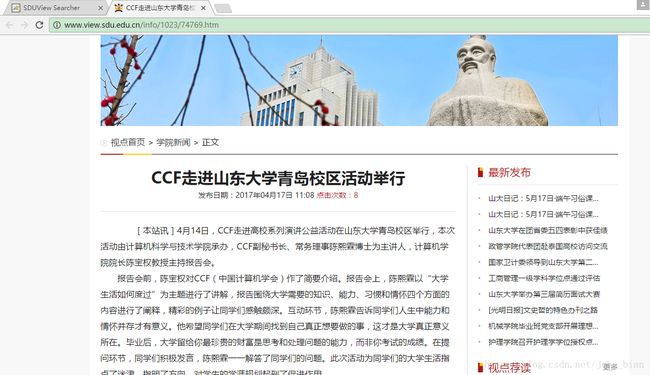
输入“计算机科学与技术学院青岛校区”进行查询,结果如下图所示。
点击CCF走进“山东大学青岛校区活动举行”链接打开新闻内容。
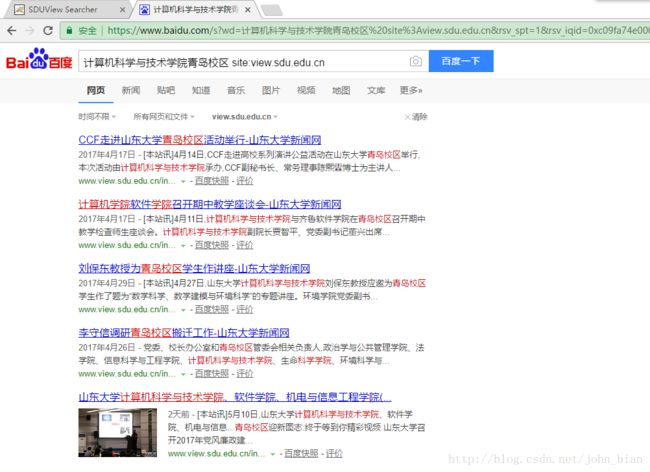
我们用百度限定在山东大学新闻网站内进行相同语句的搜索结果如图11所示。可以看出两者搜索结果的相似度还是可以的。
感想体会
当第一次听说这个实验题目的时候是感觉很难的,以前也从未想过去开发实现一个搜索引擎。好在Lucene这个开源工具十分强大,已经帮助我们做好了许多事情,我们只需要理解它的内部基本原理,然后进行简单的修改和加工整合就可以了。这次的搜索引擎开发的难度应该比以前的数据库课程设计难度要高,但是花费的时间精力却比以前少,实现的效果也比当初好了很多。这应该是上个寒假和本学期前一部分时间中从另一个角度全面对Java语言以及数据结构等的知识的再学习有关。通过这个项目的开发能够明显地感觉到了自己对编程的感觉变好了,这是真是一件令人兴奋的事情。
参考资料
【1】《开发自己的搜索引擎》第二版,邱哲、符滔滔、王学松编著,人民邮电出版社。
【2】《简单搜索引擎分析与开发》王华 武汉工业学院毕业设计(论文)。
【3】《Java Web 程序设计与开发》马月坤、赵全明编著,清华大学出版社。
如有不当之处,欢迎通过QQ进行深入交流,同时也欢迎通过微信打赏的方式对博主进行支持。