最浅显易懂的一篇:RCU机制
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。本文链接:https://blog.csdn.net/junguo/article/details/8244530
简介
RCU(Read-Copy Update)是数据同步的一种方式,在当前的Linux内核中发挥着重要的作用。RCU主要针对的数据对象是链表,目的是提高遍历读取数据的效率,为了达到目的使用RCU机制读取数据的时候不对链表进行耗时的加锁操作。这样在同一时间可以有多个线程同时读取该链表,并且允许一个线程对链表进行修改(修改的时候,需要加锁)。RCU适用于需要频繁的读取数据,而相应修改数据并不多的情景,例如在文件系统中,经常需要查找定位目录,而对目录的修改相对来说并不多,这就是RCU发挥作用的最佳场景。宽限期
struct foo { int a; char b; long c; }; DEFINE_SPINLOCK(foo_mutex); struct foo *gbl_foo; void foo_read (void){ foo *fp = gbl_foo; if ( fp != NULL ) dosomething(fp->a, fp->b , fp->c );} void foo_update( foo* new_fp ){ spin_lock(&foo_mutex); foo *old_fp = gbl_foo; gbl_foo = new_fp; spin_unlock(&foo_mutex); kfee(old_fp);}
图中每行代表一个线程,最下面的一行是删除线程,当它执行完删除操作后,线程进入了宽限期。宽限期的意义是,在一个删除动作发生后,它必须等待所有在宽限期开始前已经开始的读线程结束,才可以进行销毁操作。这样做的原因是这些线程有可能读到了要删除的元素。图中的宽限期必须等待1和2结束;而读线程5在宽限期开始前已经结束,不需要考虑;而3,4,6也不需要考虑,因为在宽限期结束后开始后的线程不可能读到已删除的元素。为此RCU机制提供了相应的API来实现这个功能。 void foo_read(void){ rcu_read_lock(); foo *fp = gbl_foo; if ( fp != NULL ) dosomething(fp->a,fp->b,fp->c); rcu_read_unlock();} void foo_update( foo* new_fp ){ spin_lock(&foo_mutex); foo *old_fp = gbl_foo; gbl_foo = new_fp; spin_unlock(&foo_mutex); synchronize_rcu(); kfee(old_fp);}订阅——发布机制
void foo_update( foo* new_fp ){ spin_lock(&foo_mutex); foo *old_fp = gbl_foo; new_fp->a = 1; new_fp->b = ‘b’; new_fp->c = 100; gbl_foo = new_fp; spin_unlock(&foo_mutex); synchronize_rcu(); kfee(old_fp);} 这段代码中,我们期望的是6,7,8行的代码在第10行代码之前执行。但优化后的代码并不对执行顺序做出保证。在这种情形下,一个读线程很可能读到new_fp,但new_fp的成员赋值还没执行完成。当读线程执行dosomething(fp->a, fp->b , fp->c ) 的 时候,就有不确定的参数传入到dosomething,极有可能造成不期望的结果,甚至程序崩溃。可以通过优化屏障来解决该问题,RCU机制对优化屏障做了包装,提供了专用的API来解决该问题。这时候,第十行不再是直接的指针赋值,而应该改为 : rcu_assign_pointer(gbl_foo,new_fp);
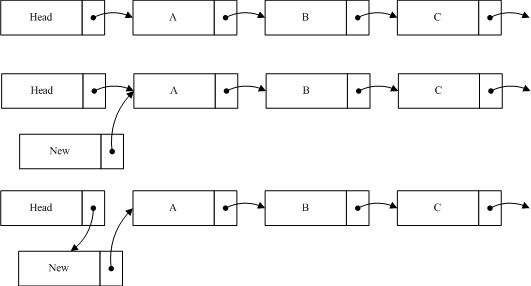 如图我们在原list中加入一个节点new到A之前,所要做的第一步是将new的指针指向A节点,第二步才是将Head的指针指向new。这样做的目的是当插入操作完成第一步的时候,对于链表的读取并不产生影响,而执行完第二步的时候,读线程如果读到new节点,也可以继续遍历链表。如果把这个过程反过来,第一步head指向new,而这时一个线程读到new,由于new的指针指向的是Null,这样将导致读线程无法读取到A,B等后续节点。从以上过程中,可以看出RCU并不保证读线程读取到new节点。如果该节点对程序产生影响,那么就需要外部调用做相应的调整。如在文件系统中,通过RCU定位后,如果查找不到相应节点,就会进行其它形式的查找,相关内容等分析到文件系统的时候再进行叙述。
如图我们在原list中加入一个节点new到A之前,所要做的第一步是将new的指针指向A节点,第二步才是将Head的指针指向new。这样做的目的是当插入操作完成第一步的时候,对于链表的读取并不产生影响,而执行完第二步的时候,读线程如果读到new节点,也可以继续遍历链表。如果把这个过程反过来,第一步head指向new,而这时一个线程读到new,由于new的指针指向的是Null,这样将导致读线程无法读取到A,B等后续节点。从以上过程中,可以看出RCU并不保证读线程读取到new节点。如果该节点对程序产生影响,那么就需要外部调用做相应的调整。如在文件系统中,通过RCU定位后,如果查找不到相应节点,就会进行其它形式的查找,相关内容等分析到文件系统的时候再进行叙述。 小结
小结