Tensorflow实战10:Tensorflow实现Word2Vec
介绍
\quad Word2Vec也称Word Emneddings,中文有很多叫法,比较普遍的是"词向量"或“词嵌入”。Word2Vec是一个可以将语言文字转化为向量形式表达(Vector Respresentations)的模型,我们先来看看为什么要把字词转为向量。图像,音频等数据天然可以编码并存储为稠密向量的形式,比如图片是像素点的稠密矩阵,音频可以转为声音信号的频谱数据。自然语言处理在Word2Vec出现之前,通常将字词转为离散的单独的符号,比如“中国”转为编号为5178的特征,将“北京”转为3978的特征。这即是One-Hot Encoder,一个词对应一个向量(向量中只有一个值为1,其他为0),通常需要将一篇文章中每一个词都转化为1个向量,而整篇文章则变为一个稀疏矩阵。对文本分类模型,我们使用Bag of Words模型,将文章对应的稀疏矩阵合并为一个向量,即把每一个词对应的向量加到一起,这样只统计每个词出现的次数,比如中国出现23次,那么第5178个特征为23,"北京"出现2次,那么第3987个特征为2。
\quad 使用One-Hot Encoder有一个问题,即我们队特征的编码往往是随机的,没有提供任何关联信息,没有考虑到字词间可能存在的关系。例如,我们队"中国"和"北京"的从属关系,地理位置关系等一无所知,我们从5178和3987这2个值看不出任何信息。同时,将字词存储为稀疏向量的话,我们通常需要很多的数据来训练,因为稀疏数据训练的效率比较低,计算也非常麻烦。使用向量表达则可以有效的解决这个问题。向量空间模型(Vector Space Module)可以将字词转为连续值(相对于One-Hot编码的离散值)的向量表达,并且其中意思相近的词将被映射到空间向量中相近的位置。向量空间模型在NLP中主要依赖的假设是Distributional Hypothesis,即在相同语境中出现的词其语义也相近。向量空间模型可以大致分为2类,一类是计数模型,比如Latent Semantic Analysis;另一类时预测模型(比如Neural Probablistic Language Models)。技术模型在语料库中,相邻出现的词的概率,再把这些技术统计结果转为小而稠密的矩阵;而预测模型则根据一个词周围相邻的词推测出这个词,以及它的空间向量。
\quad Word2Vec即是一种计算非常高效的,可以从原始语料中学习字词空间向量的预测模型。它主要分为CBOW(Continuos Bag of Words)和Skip-Gram两种模式,其中CBOW是从原始语句(比如:中国的首都是___)推测目标字词(比如:北京);而Skip-Gram则正好相反,它是从目标字词推侧原始语句,其中CBOW对小型数据比较适合,而Skip-Gram在大型语料中表现得更好。
\quad 使用Word2Vec训练语料库能得到一些非常有趣的结果,比如意思相近的词在向量空间中的位置会接近。从一份Google训练超大语料库得到的结果中看,诸如Beijing,London,New York等城市的名字会在向量空间中聚在一起,而Cat,Dog,Fish等动物词汇也会聚集在一起。同时,Word2Vec还会学习到一些高阶的语言概念,比如我们计算"man"到"woman"的向量(词汇都是向量空间的点,可计算2点间的向量),会发现它和"king"到"queue"的向量非常相似,即模型学到了男人与女人之间的关系;同时,"walking"到"walked"的向量和"swiming"到"swam"的向量非常相似,模型学到了进行时与过去式的关系。
\quad 预测模型Neural Probabilistic Models通常使用最大似然的方法,在给定前面的语句h的情况下,最大化目标词汇 w t w_t wt的概率,但它存在的一个比较严重的问题是计算量非常大,需要计算词汇表中所有单词出现的可能性。在Word2Vec的CBOW模型中,不需要计算完整的概率模型,只需要训练一个二元的分类模型,用来区分真实的目标词汇和编造的目标词汇这两类。
\quad 当模型预测真实的目标词汇为高概率,同时预测其他噪声词汇为低概率时,我们训练的学习目标就被最优化了。用编造的噪声词汇训练的方法被称为Negative Sampling。用这种方法计算loss function的效率非常高,我们只需要计算随机选择的k个词汇而非词表中的全部词汇,因此训练速度快。在实际中,我们使用Noise-Contrastive Estimation(NCE loss),同时在Tensorflow中也有tf.nn.nce_loss()直接实现了这个loss。
\quad 在本节中我们将主要使用Skip-Gram模式的Word2Vec,先来看一下它训练样本的构成,以"the quick brown fox jumped over the lazy dog"这句话为例。我们要构造一个语境与目标词汇的映射关系,其中语境包括一个单词左边和右边的词汇,假设我们的划窗尺寸为1,可以制造的映射关系包括[the,brown]->quick,[quick,fox]->brown
,[brown,jumped]->fox等。因为Skim-Gram模型是从目标词汇预测语境,所以训练样本不是[the,brown]->quick,而是quick->the和quick->brown。我们的数据集就变为了(quick,the),(quick,brown),(brown,quick),(brown,fox)等。我们训练时希望模型能从目标词汇quick预测出语境the,同时也需要制造随机的词汇作为负样本(噪声),我们希望预测的概率分布在正样本the尽可能大,而在随机产生的负样本尽可能小。这里的损失函数尽可能小。这样,每个单词的Embedded Vector就会随着训练过程不断调整,直到处于一个最合适语料的空间位置。这样,我们的损失函数最小,最符合语料,同时预测出正确单词的概率也最高。
- 导入库
#coding=utf-8
#Word2Vec.py
import collections
import math
import os
import random
import zipfile
import numpy as np
import urllib
import tensorflow as tf
- 我们先定义下载文本数据的函数,这里使用urlib.request.urlretrieve下载数据的压缩文件并核对文件尺寸,如果已经下载了文件则跳过。如果网络问题,导致不能下载,可以预先在这个url:'http://mattmahoney.net/dc/text8.zip’下载下来加载即可。
#定义下载文本数据的函数,使用urllib.request.urlretrieve
url = 'http://mattmahoney.net/dc/'
def maybe_download(filename, expected_bytes):
if not os.path.exists(filename):
filename, _ = urllib.request.urlretrieve(url + filename, filename)
statinfo = os.stat(filename)
if statinfo.st_size == expected_bytes:
print('Found and verified', filename)
else:
print(statinfo.st_size)
raise Exception('Failed to verify' + filename + '. Can you get to it with a browser?')
return filename
filename = maybe_download('text8.zip', 31344016)
- 接下来解压下载的压缩文件,并使用tf.compat.as_str将数据转成单词的列表。通过程序输出,可以知道数据最后被转成了一个包含17005207单词的列表。
#解压下载的压缩文件,并使用tf.compat.as_str将数据转化为单词的列表
def read_data(filename):
with zipfile.ZipFile(filename) as f:
data = tf.compat.as_str(f.read(f.namelist()[0])).split()
return data
words = read_data(filename)
print('Data size', len(words))
- 接下来创建vocabulary词汇表,我们使用collections.Counter统计单词列表中单词的频数,然后使用most_common方法获取top 50000频数的单词作为vocabulary。再创建一个dict,将top 50000词汇的放入dictionary中,如果是则转为其编号(以频数排序的编号),top 50000词汇之外的单词,我们认定其为Unknown(未知),将其编号为0,并统计这类词汇的数量。下面便利单词列表,对其中每一个单词先判断是否出现在dictionnary中,如果是则转为其编号,如果不是则转化为0(Unknown)。最后返回转换后的编码(dta),每个单词的频数统计(count),词汇表(dictionary)及其翻转的形式(reverse_dictionary)。
#创建vocabulary词汇表
vocabulary_size = 50000
def build_dataset(words):
count = [['UNK', -1]]
count.extend(collections.Counter(words).most_common(vocabulary_size - 1))
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary) #获取一个唯一的编号,相当于stl的map
data = list()
unk_count = 0
for word in words:
if word in dictionary:
index = dictionary[word]
else:
index = 0
unk_count += 1
data.append(index)
count[0][1] = unk_count
reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reverse_dictionary
- 然后我们删除原始单词列表,可以节约内存。再打印vocabulary中最高频出现的词汇及其数量(包括Unknown词汇),可以看到"UNK"这类一共有418391个,最常出现的词汇“the”you 1061396个,排名第二的"of"有593677个。我们的data中前10个单词为[‘anarchism’,‘as’,‘a’,‘term’,‘of’,‘abuse’,‘first’,‘used’,‘against’]对应的编号为[5235,3084,12,6,195,2,3137,46,59,156]
#删除原始单词列表,再打印vocabulary中最高频出现的词汇和数量
del words
print('Most common words (+UNK)', count[:5])
print('Sample data', data[:10], [reverse_dictionary[i] for i in data[:10]])
- 下面生成Word2Vec的训练样本,我们根据前面提到的Skip-Gram模式(从目标单词反推语境),将原始数据"the quick brown fox jumped over the lazy dog"转为(quick,the),(quick,brown),(brown,quick),(brown,fox)等样本。我们定义函数generate_batch用来生成训练用的batch数据,参数中batch_size为batch的大小;skip_window指单词最远可以联系的距离,设为1代表只能跟紧邻的2个单词生成样本,比如quick只能和前后的单词生成两个样本(quick,the)和(quick,brown);num_skips为对每个单词生成多少个样本,它不能大于skip_windows的2倍,并且batch_size必须是它的整数倍(确保每个batch包含了一个词汇对应的所有样本)。我们定义单词序号data_index为global变量,因为我们会反复调用generate_batch,所以我们要确保data_index可以在函数generate_batch中被修改。我们也使用assert确保num_skips和batch_size满足前面提到的2个条件。然后用np.ndarray将batch和labels初始化为数组。这里定义span为对某个单词创建相关样本时会用到的单词数量,包括目标单词本身和它前后的单词,因此span=2*skip_windows+1。并创建一个最大容量为span的deque,即双向队列,在对deque使用append方法添加变量时,只会保留最后插入的span个变量。
#生成Word2Vec的样本
data_index = 0
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1
buffer = collections.deque(maxlen=span)
- 接下来从序号data_index开始,把span个单词顺序读入buffer作为初始值。因为buffer是容量为span的deque,所以此时buffer已填充满,后续数据将替换掉前面的数据。然后我们进入第一层循环(次数为batch_size//num_skips),每次循环内对一个目标单词生成样本。现在buffer中是目标单词和所有相关单词,我们定义target=skip_window,即buffer中第skip_window个变量为目标单词。然后定义生成样本时需要避免的单词列表targets_to_avoid,这个列表一开始包括第skip_window个单词(即目标单词),因为我们要预测的是语境单词,不包括目标单词本身。接下来进入第二层循环(次数为num_skips),每次循环中对一个语境单词生成样本,先产生随机数,直到随机数不在targets_to_avoid中,代表可以使用的语境单词,然后产生一个样本,feature即目标词汇buffer[skip_window],label则是buffer[target]。同时,因为这个语境单词被使用了,所以再把它添加到targets_to_avoid中过滤。在对一个目标单词生成完所有样本后(num_skips个样本),我们再读入下一个单词(同时会抛掉buffer中第一个单词),即把划窗向后移动一位,这样我们的目标单词也向后移动了一个,语境单词也整体后移了,便可以生成下一个目标单词的训练样本。两层循环完成后,我们已经获得了batch_size个样本,将batch和labels作为函数结果返回。
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1
buffer = collections.deque(maxlen=span)
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
for i in range(batch_size // num_skips):
target = skip_window
target_to_avoid = [skip_window]
for j in range(num_skips):
while target in target_to_avoid:
target = random.randint(0, span - 1)
target_to_avoid.append(target)
batch[i * num_skips + j] = buffer[skip_window]
labels[i * num_skips + j, 0] = buffer[target]
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
return batch, labels
- 这里调用generate _batch函数简单测试一下其功能。参数中将batch_size设为8,num_skips设为2,skip_window设为1,然后执行generate_batch并获得batch和labels。再打印batch和labels的数据,可以看到我们生成的样本时"3084 originated->5235 anarchism",“3084 originated ->12 as”,"12 as -> 3084 originated"等。以第一个样本为例,3084是目标单词originated的编号,这个单词对应的语境单词是anarchism,其编号为5235.
#调用generate_batch函数简单测试一下功能
batch, labels = generate_batch(batch_size=8, num_skips=2, skip_window=1)
for i in range(8):
print(batch[i], reverse_dictionary[batch[i]], '->', labels[i, 0], reverse_dictionary[labels[i, 0]])
9.我们定义训练时的batch_size为128;embedding_size为128,embedding_size即将单词转换为稠密向量的维度,一般是50-1000这个范围内的值,这里使用128作为词向量的维度;skip_window即前面提到的最远可以联系的距离,设为1;num_sckips即对每个目标单词提取的样本数,设为2.然后我们再生成验证数据valid_examples,这里随机抽取一些频数最高的单词,看向量空间上跟它们最近的单词是否相关性较高。valid_size=16指用来抽取的验证单词数,valid_window=100是指验证单词只从频数最高的100个单词中抽取,我们使用np.random.choice函数进行随机抽取。而num_sampled是训练时用来做负样本的噪声单词的数量。
batch_size = 128
embedding_size = 128
skip_window = 1
num_skips = 2
valid_size = 16
valid_window = 100
valid_examples = np.random.choice(valid_window, valid_size, replace=False)
num_sampled = 64
- 下面就开始定义Skip-Gram Word2Vec模型的网络结构。我们先创建一个tf.Graph并设置为默认的graph。然后创建训练数据中inputs和labels的placeholder,同时将前面随机参生的valid_examples转为Tensorflow中的constant。接下来,先使用with tf.device(’/cpu:0’)限定所有的计算在CPU上执行,因为接下去的一些计算操作在GPU上可能还没有实现,然后使用tf.random_uniform随机生成所有单词的词向量embeddings单词表大小为50000,向量维度为128,再使用tf.nn.embedding_lookup查找输入train_inputs对应的向量embed。下面使用之前提到的NCE loss作为训练的优化目标,我们使用tf.truncated_normal初始化NCE loss中的权重参数nce_weights,并将其nce_biases初始化为0。最后使用tf.nn.nce_loss计算学习出的词向量embedding在训练数据上的Loss,并使用tf.reduce_mean进行汇总。
graph = tf.Graph()
with graph.as_default():
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
with tf.device('/cpu:0'):
embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
nce_weights = tf.Variable(tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0/math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights, biases=nce_biases, labels=train_labels, inputs=embed,
num_sampled=num_sampled, num_classes=vocabulary_size))
- 我们定义优化器为SGD,且学习速率为1.0.然后计算词向量embeddings的L2范数norm,再将embeddings除以其L2范数得到标准化后的normalized_embeddings。再使用tf.nn.embeddings_lookup查询验证单词的嵌入向量与词汇表中所有单词的相似性。最后,我们使用tf.global_variables_initializer初始化所有模型的参数。
#定义优化器
optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)
similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)
init = tf.global_variables_initializer()
- 我们定义最大的迭代次数为10万次,然后创建并设置默认的session,并执行参数初始化。在每一步训练迭代中,先使用generate_batch生成一个batch的inputs和labels数据。并用他们创建feed_dict。然后使用session.run()执行一次优化器运算(即一次参数更新)和损失计算,并将这一步训练的loss累积到average_loss。之后每2000次循环,计算一下平均loss并显示出来。每10000次循环,计算一次验证单词与全部单词的相似度,并将与每个验证单词最终相似的8个单词展示出来。
num_steps = 100001
with tf.Session(graph=graph) as session:
init.run()
print('Initalized')
average_loss = 0
for step in range(num_steps):
batch_inputs, batch_labels = generate_batch(batch_size, num_skips, skip_window)
feed_dict = {train_inputs : batch_inputs, train_labels : batch_labels}
_, loss_val = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += loss_val
if(step % 2000 == 0):
if step > 0:
average_loss /= 2000
print("Average loss at step ", step, ": ", average_loss)
average_loss = 0
if(step % 10000 == 0):
sim = similarity.eval()
for i in range(valid_size):
valid_word = reverse_dictionary[valid_examples[i]]
top_k = 8
nearest = (-sim[i, :]).argsort()[1: top_k+1]
log_str = "Nearest to %s:" % valid_word
for k in range(top_k):
close_word = reverse_dictionary[nearest[k]]
log_str = "%s %s, " % (log_str, close_word)
print(log_str)
final_embeddings = normalized_embeddings.eval()
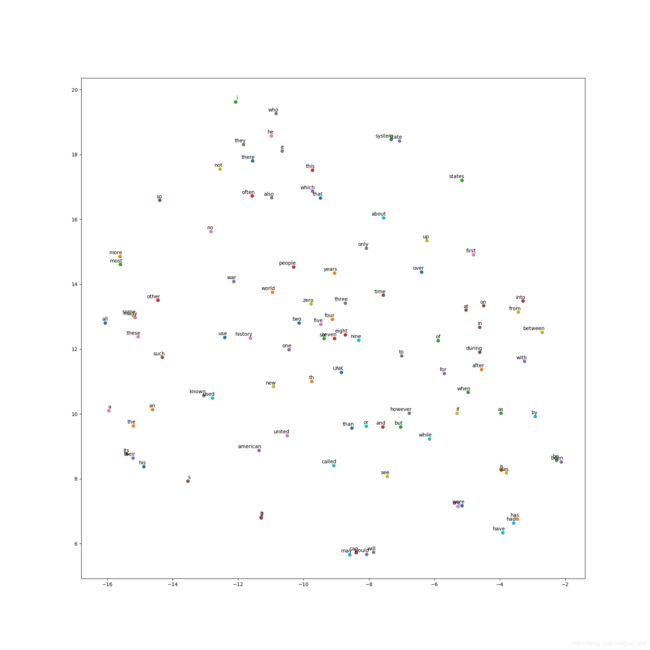
- 最后定义一个用来可视化Word2Vec效果的函数。这里low_dim_embs是降维到2维的单词的空间向量,我们将在图表中展示每个单词的位置。我们使用plt.scatter显示散点图,并用plt.annotate展示单词本身。同时,使用plt.savefig保存图片到本地文件。这里只展示词频最高的100个单词的可视化结果。
def plot_with_labels(low_dim_embs, labels, filename='tsne.png'):
assert low_dim_embs.shape[0] >= len(labels), "More labels than embeddings"
plt.figure(figsize=(18, 18))
for i, label in enumerate(labels):
x, y = low_dim_embs[i, :]
plt.scatter(x, y)
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.savefig(filename)
from sklearn.manifold import TSNE
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_only = 100
low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only, :])
labels = [reverse_dictionary[i] for i in range(plot_only)]
plot_with_labels(low_dim_embs, labels)
可视化得到的结果为:
算法的完整代码
#coding=utf-8
#Word2Vec.py
import collections
import math
import os
import random
import zipfile
import numpy as np
import urllib
import tensorflow as tf
import matplotlib.pyplot as plt
#定义下载文本数据的函数,使用urllib.request.urlretrieve
# url = 'http://mattmahoney.net/dc/'
#
# def maybe_download(filename, expected_bytes):
# if not os.path.exists(filename):
# filename, _ = urllib.request.urlretrieve(url + filename, filename)
# statinfo = os.stat(filename)
# if statinfo.st_size == expected_bytes:
# print('Found and verified', filename)
# else:
# print(statinfo.st_size)
# raise Exception('Failed to verify' + filename + '. Can you get to it with a browser?')
# return filename
#filename = maybe_download('text8.zip', 31344016)
filename = "C:\\Users\\xiaoyu\\PycharmProjects\\DeepLearning\\text8.zip"
#解压下载的压缩文件,并使用tf.compat.as_str将数据转化为单词的列表
def read_data(filename):
with zipfile.ZipFile(filename) as f:
data = tf.compat.as_str(f.read(f.namelist()[0])).split()
return data
words = read_data(filename)
print('Data size', len(words))
#创建vocabulary词汇表
vocabulary_size = 50000
def build_dataset(words):
count = [['UNK', -1]]
count.extend(collections.Counter(words).most_common(vocabulary_size - 1))
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary) #获取一个唯一的编号,相当于stl的map
data = list()
unk_count = 0
for word in words:
if word in dictionary:
index = dictionary[word]
else:
index = 0
unk_count += 1
data.append(index)
count[0][1] = unk_count
reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reverse_dictionary
data, count, dictionary, reverse_dictionary = build_dataset(words)
#删除原始单词列表,再打印vocabulary中最高频出现的词汇和数量
del words
print('Most common words (+UNK)', count[:5])
print('Sample data', data[:10], [reverse_dictionary[i] for i in data[:10]])
#生成Word2Vec的样本
data_index = 0
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1
buffer = collections.deque(maxlen=span)
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
for i in range(batch_size // num_skips):
target = skip_window
target_to_avoid = [skip_window]
for j in range(num_skips):
while target in target_to_avoid:
target = random.randint(0, span - 1)
target_to_avoid.append(target)
batch[i * num_skips + j] = buffer[skip_window]
labels[i * num_skips + j, 0] = buffer[target]
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
return batch, labels
#调用generate_batch函数简单测试一下功能
batch, labels = generate_batch(batch_size=8, num_skips=2, skip_window=1)
for i in range(8):
print(batch[i], reverse_dictionary[batch[i]], '->', labels[i, 0], reverse_dictionary[labels[i, 0]])
#
batch_size = 128
embedding_size = 128
skip_window = 1
num_skips = 2
valid_size = 16
valid_window = 100
valid_examples = np.random.choice(valid_window, valid_size, replace=False)
num_sampled = 64
#定义Skip-Gram Word2Vec模型的网络结构
graph = tf.Graph()
with graph.as_default():
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
with tf.device('/cpu:0'):
embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
nce_weights = tf.Variable(tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0/math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights, biases=nce_biases, labels=train_labels, inputs=embed,
num_sampled=num_sampled, num_classes=vocabulary_size))
#定义优化器
optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)
similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)
init = tf.global_variables_initializer()
num_steps = 100001
with tf.Session(graph=graph) as session:
init.run()
print('Initalized')
average_loss = 0
for step in range(num_steps):
batch_inputs, batch_labels = generate_batch(batch_size, num_skips, skip_window)
feed_dict = {train_inputs : batch_inputs, train_labels : batch_labels}
_, loss_val = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += loss_val
if(step % 2000 == 0):
if step > 0:
average_loss /= 2000
print("Average loss at step ", step, ": ", average_loss)
average_loss = 0
if(step % 10000 == 0):
sim = similarity.eval()
for i in range(valid_size):
valid_word = reverse_dictionary[valid_examples[i]]
top_k = 8
nearest = (-sim[i, :]).argsort()[1: top_k+1]
log_str = "Nearest to %s:" % valid_word
for k in range(top_k):
close_word = reverse_dictionary[nearest[k]]
log_str = "%s %s, " % (log_str, close_word)
print(log_str)
final_embeddings = normalized_embeddings.eval()
def plot_with_labels(low_dim_embs, labels, filename='tsne.png'):
assert low_dim_embs.shape[0] >= len(labels), "More labels than embeddings"
plt.figure(figsize=(18, 18))
for i, label in enumerate(labels):
x, y = low_dim_embs[i, :]
plt.scatter(x, y)
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.savefig(filename)
from sklearn.manifold import TSNE
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_only = 100
low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only, :])
labels = [reverse_dictionary[i] for i in range(plot_only)]
plot_with_labels(low_dim_embs, labels)