R语言爬虫实战:知乎live课程数据爬取实战

本文是一篇R语言爬虫实战练习篇,同样使用httr包来完成,结合cookies登录、表单提交、json数据包来完成整个数据爬取过程,无需书写复杂的xpath、css路径甚至繁琐的正则表达式(尽管这三个技能对于数据爬取而言意义非凡)。
之前已经演练过如何使用httr来完成网易云课堂的课程爬取,其中用到POST方法和表单提交。
今天爬取对象是知乎live课程信息,用到的GET方法,结合cookies登录和参数提交来完成,这一篇会给大家稍微涉猎一些细节技巧。
library("httr")
library("dplyr")
library("jsonlite")
library("curl")
library("magrittr")
library("plyr")
library("rlist")第一步:仍然是确定对象网页所用到的技术框架:
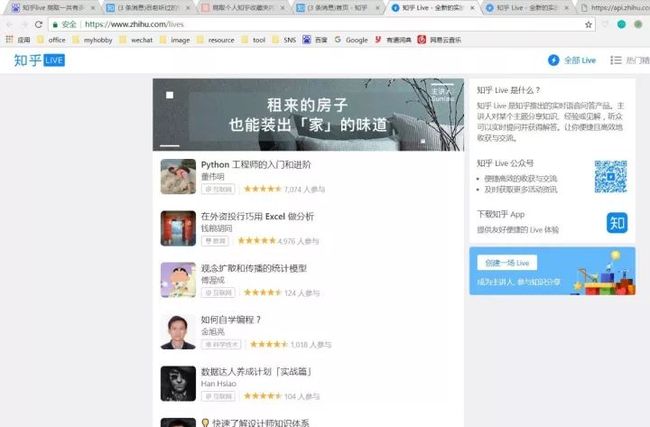
看到页面初始化的时候大概只有10条课程信息的展示量,然后继续往下滑动鼠标会自动刷新,妥了,这个典型的异步加载网页。
使用Chrome浏览器F12键打开后台,你可以在all菜单里面找到一个homefeed?limit=10&offset=10&includes=live的异步加载链接(XHR),通常情况下异步加载链接都是在XHR菜单里面的,但是也有例外,这时候你需要在all菜单里面寻找(可能有很多其他媒体类型请求,需要你耐心寻找,如果找不到就狂按F5刷新,看哪个请求是新蹦出来的)。

这个链接一看就很像课程链接的样子,limit是限制网页记录展示数量的参数(刚好10条),offset是偏移量参数(刚好默认也是10,就是说鼠标往下滑动之后会刷新出来10条新课程记录,也就是offset偏移量会以10的整数倍增加,每下拉一次,异步加载请求会增加10条记录信息),includes是模块性质,这里是live。
到底是不是这样呢, 让我们点进去这个xhr请求,到右下侧的网页预览里面详细一看便知,果不其然,刚好是我们要的信息,全部都是以json数据包的形式封存在网址为https://api.zhihu.com/lives/homefeed?limit=10&offset=10&includes=live的网页里面。

然后我们接下来需要做的工作就是详细分析其请求方式、报头参数设置、cookies设置、需要提交的参数等信息。
第二步:构造报头信息、参数表信息、cookies信息
开发者工具定位到右侧下的Headers菜单下:你会看到以下四个模块的信息:
General:Request URL:https://api.zhihu.com/lives/homefeed?limit=10&offset=10&includes=live
Request Method:GET
Status Code:200 OK
Remote Address:47.95.51.100:443
Referrer Policy:no-referrer-when-downgradeResponse Headers:Access-Control-Allow-Credentials:true
Access-Control-Allow-Headers:Authorization,Content-Type,X-API-Version
Access-Control-Allow-Methods:GET,PATCH,PUT,POST,DELETE,OPTIONS
Access-Control-Allow-Origin:https://www.zhihu.com
Connection:keep-alive
Content-Encoding:gzip
Content-Type:application/json; charset=utf-8
Date:Wed, 11 Oct 2017 13:24:38 GMT
Etag:W/"0b0bb047bb0eaf6962481a517b4276e48a774d54"
Server:ZWS
Transfer-Encoding:chunked
Vary:Accept-Encoding
X-Backend-Server:zhihu-live.liveweb.761d7228---10.4.165.2:31030[10.4.165.2:31030]
X-Req-ID:10B3371859DE1B96
X-Req-SSL:proto=TLSv1.2,sni=,cipher=ECDHE-RSA-AES256-GCM-SHA384
X-Tracing-Servicename:liveweb
X-Tracing-Spanname:LiveHomeFeedHandler_getRequest Headers:
accept:application/json, text/plain, */*
Accept-Encoding:gzip, deflate, br
Accept-Language:zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4
Authorization:oauth 8274ffb553d511e6a7fdacbc328e205d
Connection:keep-alive
Cookie:_zap="请键入个人知乎cookies"
Host:api.zhihu.com
If-None-Match:W/"ba0517e8bddf8a410ffcda75a507295dc4024786"
Origin:https://www.zhihu.com
Referer:https://www.zhihu.com/lives/
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36
X-Api-Version:3.0.63Query String Parameters:limit:10
offset:10
includes:live

备注:(请求参数里我匿了我的登录cookies哈哈,毕竟如今知乎有六七千关注量,虽然不算大号,但是对我挺重要的,不能随便登录信息泄露哒~)
OK,完美,那么确定本次使用到的浏览器请求方式是GET请求,网址对象是
https://api.zhihu.com/lives/homefeed?limit=10&offset=10&includes=live注意体会其与你浏览器中的原始网址有何异同,在浏览器中直接打开live栏目,你的网址栏里面显示的是如下网址:https://www.zhihu.com/lives,想要不断展示所有的课程记录是需要你使用鼠标滚轮不断的向下滚动的。
但是他在后台所发起的异步加载请求调用的网址实际上是通过参数提交之后的如下网址,这个网址因为是get请求,在网页浏览器也是可以直接打开的,不过因为是json页面,打开之后是没有任何渲染的纯文本文件。网址如下
https://api.zhihu.com/lives/homefeed?limit=10&offset=10&includes=live#构造cookies:
Cookie='请键入个人知乎cookies'#构造浏览器报头信息:(这些信息均来自于request模块)
headers <- c(
'Accept'='application/json',
'Content-Type'='application/json; charset=utf-8',
'User-Agent'='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36',
'Referer'='https://www.zhihu.com/lives/',
'Connection'='keep-alive',
'Cookie'=Cookie
)以上报头信息中,Accept告知知乎服务器我想要获取什么格式的文件信息;Content-Type是服务器返回的信息编码格式;User-Agent是本地浏览器的规格信息(很重要);Cookie是登录信息。
报头信息参数在不同的网页中可能会差异很大,很多时候需要我们自己尝试那些是有用的那些是无用的, 但是常用的几个需要重点关注。
#构造表单提交参数:
payload<-list(
'limit'=10,
'offset'=10,
'includes'='live'
)GET方法的参数本来是可以写在url里面的,但是对于需要多页遍历的网页,如果单独将参数写在参数表里面将会在构造循环或者遍历网页时更加方便。参数表只能接受list格式提交,本案例只涉及三个参数,且都是必要参数。查询参数在httr的GET方法里面对应query参数(还记得POST方法里面定位网页的时,用到的表单体是对应什么参数吗)。
第三步:单步尝试查看输出内容结构:
baseurl<-"https://api.zhihu.com/lives/homefeed"
r <- GET(baseurl,add_headers(.headers =headers),query =payload, encode="json",verbose())
myresult<-r %>% content()
完美,网页响应没有任何问题,接下来查看输出内容结构:
myresult<-r %>% content() %>% `[[`(2)
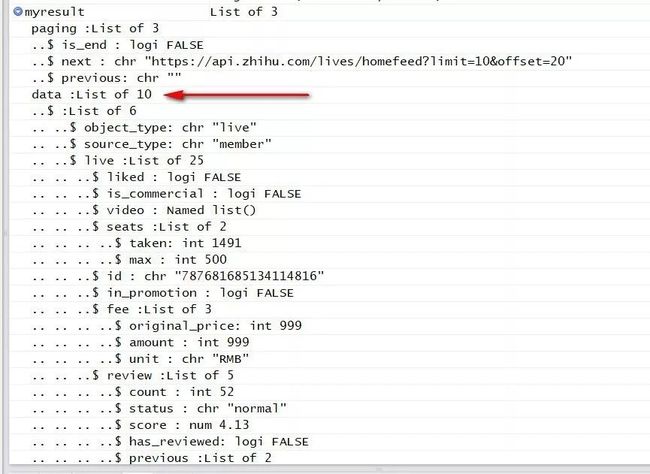
我们需要的课程信息位于输出内容的第二个list内,因而使用以上语句便可提取所有的课程信息内容,刚好10条。
对于本篇案例遇到最大的困难是,我们无法判断一共有多少条课程记录,后台所有参数中均没有给出,所以……我有个大胆的想法。
既然Query String Parameters:模块给出的是默认的单次记录展示数据量以及课程记录偏移量,那么我是否可以人为设置一个limit和offset呢,比如我设置limit为100,offset为0,100,200这样,或许多试几次基本就可以确定了。
当我设置limit=200,offset=150时,已经没有课程信息了,也就是说150之后已经没有数据了,那么课程条目数量应该在150以内,网页返回信息如下:
https://api.zhihu.com/lives/homefeed?limit=200&offset=150&includes=live
{"paging": {"is_end": true, "next": "https://api.zhihu.com/lives/homefeed?limit=200&offset=350", "previous": ""}, "data": [], "attached_info": "MiBlODVkMzE1NDYyNGQ0MDY5YTA4OTVhM2FhMGIxZWVhNw=="}当我设置limit=200,offset=100时,内容显示是正常的,也就是说课程总数目应该在100~150之间,于是就想,如果limit设为500,offset为0,让请求单次返回记录数显示为500,不产生任何偏移量,这样岂不是所有内容都会在同一页上。
从下拉进度条看起来,似乎是可行的,然后你可以ctrl+S将网页保存为json格式,之后我们可以进行验证。
以下过程我们直接在构造payload参数时,将limit和offset分别设置为200,0,这样正常情况下我们请求一次即可拿到所有课程数据啦:
payload<-list('limit'=200,'offset'=0,'includes'='live')baseurl<-"https://api.zhihu.com/lives/homefeed"
r <- GET(baseurl,add_headers(.headers =headers),query =payload, encode="json",verbose())
myresult<-r %>% content() %>% `[[`(2)
length(myresult)
[1] 144OK,长度刚好为144,处于我们之前估测的100~150之间。
接下来我们使用jsonlite包的fromJSON导入刚才保存的json文件,验证下手动保存的json文件数据量与刚才代码请求的网页数据是否保持一致。
homefeed<-fromJSON("C:/Users/RAINDU/Desktop/homefeed.json",simplifyVector=FALSE)
length(homefeed$data)
length(homefeed$data)
[1] 144看来我的猜测是对的,这个limit确实只是一个默认的请求限制参数,并非不可更改,这里我们更改的limit之后,直接避免了手动书写并提交表单参数的过程,何乐而不为呢。
接下来将以上json文件保存,至于内容的分析与可视化嘛,当然下期继续分享啦哈哈~

你可以直接在浏览器中将网页保存为json,也可以将刚才输出的内容单独保存为本地json文件,使用rlist包的list.save函数。
list.save(homefeed,"C:/Users/RAINDU/Desktop/zhihulive.json")如果你已经等不及的话,想要自己做这份数据分析与可视化,可以按照以上步骤抓取并提取内容,我也会把这份未清洗的数据上传到GitHub,可以自行下载。
在线课程请点击文末原文链接:
往期案例数据请移步本人GitHub:
https://github.com/ljtyduyu/DataWarehouse/tree/master/File
相关课程推荐
R语言爬虫实战案例分享:
网易云课堂、知乎live、今日头条、B站视频
分享内容:本次课程所有内容及案例均来自于本人平时学习练习过程中的心得和笔记总结,希望借此机会,将自己的爬虫学习历程与大家分享,并为R语言的爬虫生态改善以及工具的推广,贡献一份微薄之力,也是自己爬虫学习的阶段性总结。

☟☟☟ 猛戳阅读原文,即刻加入课程。