(CVPR2019)图像语义分割(19) 使用知识蒸馏的语义分割方法
论文地址: Structured Knowledge Distillation for Semantic Segmentation
1. 介绍
该论文使用知识蒸馏策略,通过大型的教师网络指导小型语义分割网络的训练。论文从最简单的逐像素点蒸馏策略开始,考虑语义分割中结构化知识的学习又尝试了成对像素点知识蒸馏和全局蒸馏策略。前者受到马尔科夫随机场的启发,后者训练过程中使用了对抗训练策略。论文在轻量级语义分割模型的研究中另辟蹊径,目前代码还未开源,有时间尝试复现~
2. 相关工作
语义分割
关于高精度语义分割的研究已经有许多卓有成效的重量级模型,如PSPNet(本文使用的教师网络),DeepLabV3+等,但是实际应用中对于高效模型的诉求更加迫切,实时语义分割目前也有很大进展,如旷视的BiSeNet,DFANet等。
知识蒸馏
该策略旨在将重量级模型学习到的知识转移给轻量级模型从而提升其精度。除了在图像分类,目标检测和行人重识别方面,在语义分割中知识蒸馏也有应用,即逐像素点的学习策略[论文的工作基于语义分割任务中像素点互相联系的特点设计了两种不同的学习策略]
对抗学习
对抗生成网络是进来的研究热点,文中提到之前也有人用GAN来做语义分割,目标也是生成器的结果和ground truth没法被判别器区分出来。不过存在一个问题:生成器的输出是连续的(如0-1之间的某个值),而ground truth中的值是独立的(如0或1),因此判别器性能受限。而本文中的方法却没有这个问题,因为ground truth采用的是复杂网络的logits,也是连续的,和生成器的输出可以平等地比较,这是本文一个比较巧妙的点。论文使用对抗学习方法来尽量消除教师网络和学生网络的差异。
3.方法
图像语义分割的任务在于从 C C C个类别中预测每一个像素点的类别。模型接收大小为 W × H × 3 W \times H \times 3 W×H×3的RGB图像 I I I为输入,输出一个 W ′ × H ′ × N W' \times H' \times N W′×H′×N的特征图 F , 其 中 N F,其中N F,其中N是通道数量,最终从 F F F中计算得到 W ′ × H ′ × C W' \times H' \times C W′×H′×C的掩码图 Q Q Q,然后上采样,使得尺寸恢复至 W × H W \times H W×H。
3.1 结构化知识蒸馏
方法流程如下图所示,论文该节主要介绍三种不同的蒸馏策略:

Pixel-wise蒸馏策略
将语义分割任务看作互相独立的像素点分类问题,逐像素点的进行“类别对齐”,具体地,使用教师网路中的类别概率作为学生网络训练的目标,损失函数可以定义为:
l p i ( S ) = 1 W ′ × H ′ ∑ i ∈ R K L ( q i s ∣ ∣ q i t ) l_{pi}(S)=\frac{1}{W' \times H'}\sum_{i \in R}KL(q_i^s||q_i^t) lpi(S)=W′×H′1i∈R∑KL(qis∣∣qit)
其中 q i s q_i^s qis是学生网络S中第i个像素点的类别概率, q i t q_i^t qit是教师网络T中相应的类别概率, K L ( ⋅ ) KL(\cdot) KL(⋅)是两个概率的离散度,R={0,1,2,…, W ′ × H ′ W'\times H' W′×H′}表示所有像素点。
Pair-wise蒸馏策略
受马尔科夫随机场方法来提高预测结果的连续性,论文提出使用成对的像素点之间的相关性而不是单一的来进行知识蒸馏。
令 a i j t a_{ij}^t aijt表示教师网络产生的结果中第i个像素点和第j个像素点的相关性, a i j s a^s_{ij} aijs则表示学生网络中相应的相关性,论文使用下面的公式用作相似性间差异的损失函数:
l p a ( S ) = 1 ( W ′ × H ′ ) 2 ∑ i ∈ R ∑ j ∈ R ( a i j s − a i j t ) 2 l_pa(S)=\frac {1}{(W' \times H')^2}\sum_{i \in R}\sum_{j \in R}(a_{ij}^s-a_{ij}^t)^2 lpa(S)=(W′×H′)21i∈R∑j∈R∑(aijs−aijt)2
Holistic蒸馏策略
基于更为高级的教师网络和学生网络产生的掩码图整体之间的关系,以进行"对齐"。
处于这个目的,论文提出使用条件对抗生成学习方法来描述全局蒸馏策略。小型网络视为生成器,输入为RGB图像 I I I,输出为掩码图 Q s Q^s Qs被视为假样本,训练的目标是使这个假样本和教师网络的真样本 Q t Q^t Qt尽可能相似,真分布和假分布之间的距离通过Wasserstein距离进行衡量:
l h o ( S , D ) = E Q s − p s ( Q s ) [ D ( Q s ∣ I ) ] − E Q t − p t ( Q t ) [ D ( Q t ∣ I ) ] l_{ho}(S,D)=E_{Q^s -p_s(Q^s)}[D(Q^s|I)]\\ -E_{Q^t-p_t(Q^t)}[D(Q^t|I)] lho(S,D)=EQs−ps(Qs)[D(Qs∣I)]−EQt−pt(Qt)[D(Qt∣I)]
其中 E [ ⋅ ] E[\cdot] E[⋅]是预期运算符; D [ ⋅ ] D[\cdot] D[⋅]是判别器,由五层卷积神经网络组成,两层自注意力模块和后面三层卷积异同捕获信息,这样的判别器能够产生一个描述输入图像和掩码图匹配程度的表征。
3.2 优化
损失函数是传统的多类交叉熵损失 l m c ( S ) l_{mc}(S) lmc(S),不同在于增加了逐像素和结构化蒸馏参数,如下:
l ( S , D ) = l m c ( S ) + λ 1 ( l p i ( S ) + l p a ( S ) ) − λ 2 l h o ( S , D ) l(S,D)=l_{mc}(S)+\lambda_1(l_{pi}(S)+l_{pa}(S))-\lambda_2l_{ho}(S,D) l(S,D)=lmc(S)+λ1(lpi(S)+lpa(S))−λ2lho(S,D)
其中 λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2分别设为10和0.1,平衡三者对最终结果的影响程度,训练过程中学习小型学生网络的参数以最小化这个目标函数的过程的同时最大化判别器的出错概率,训练分为两步:
-
训练判别器:训练判别器就是最小化 l h o ( S , D ) l_{ho}(S,D) lho(S,D),D的目标是给教师网络的输出高分,给学生网络的输出低分
-
训练学生网络:给定判别网络,该过程的目标是最小化多类交叉熵损失和蒸馏损失:
l m c ( S ) + λ 1 ( l p i ( S ) + l p a ( S ) ) − λ 2 l h o 2 ( S ) 其 中 , l h o ( S ) = E Q s − p s ( Q s ) [ D ( Q s ∣ I ) ] l_{mc}(S)+\lambda_1(l_{pi}(S)+l_{pa}(S))-\lambda_2l_{ho}^2(S)\\ 其中,\\ l_{ho}(S)= E_{Q^s -p_s(Q^s)}[D(Q^s|I)] lmc(S)+λ1(lpi(S)+lpa(S))−λ2lho2(S)其中,lho(S)=EQs−ps(Qs)[D(Qs∣I)]
4. 实现细节
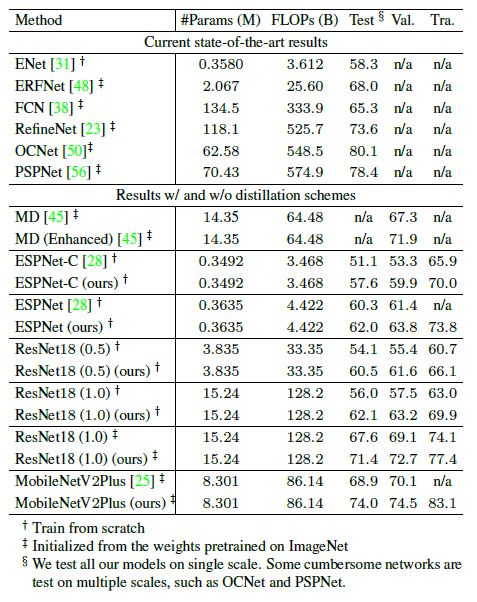
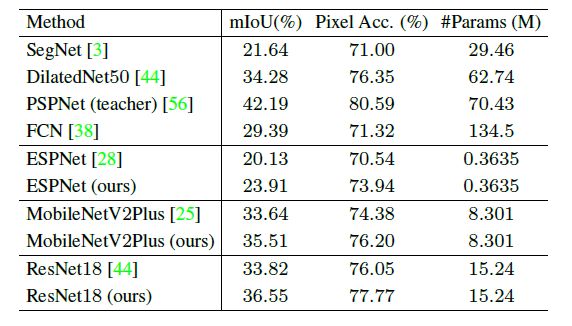
教师网络PSPNet(ResNet101),试验了许多轻量级模型,训练参数通用设置,在三个通用数据集上结果如下:
1.Cityscapes
2.ADE20K
3.CamVid

欢迎扫描二维码关注微信公众号 深度学习与数学 [每天获取免费的大数据、AI等相关的学习资源、经典和最新的深度学习相关的论文研读,算法和其他互联网技能的学习,概率论、线性代数等高等数学知识的回顾]
