Hadoop Yarn初探
前言
经过多年的发展形成了Hadoop1.X生态系统,其结构如下图所示:

其mapReduce的结构如下:

从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路:
1. 用户程序 (JobClient) 提交了一个 job,job 的信息会发送到 Job Tracker 中,Job Tracker 是 Map-reduce 框架的中心,他需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作。
2. TaskTracker 是 Map-reduce 集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。
3. TaskTracker 同时监视当前机器的 tasks 运行状况。TaskTracker 需要把这些信息通过 heartbeat 发送给 JobTracker,JobTracker 会搜集这些信息以给新提交的 job 分配运行在哪些机器上。上图虚线箭头就是表示消息的发送 - 接收的过程。
如果上图看不清,可以看下面这个:

但是这种架构带来了很多局限性,表现在如下方面:
1. 扩展性差。JobTracker同时兼备了资源管理和作业控制两个功能,这成为系统的一个最大瓶颈,严重制约了Hadoop集群扩展性。
2. 可靠性差。MRv1采用了master/slave结构,其中,master存在单点故障问题,一旦它出现故障将导致整个集群不可用。
3. 资源利用率低。MRv1采用了基于槽位的资源分配模型,槽位是一种粗粒度的资源划分单位,通常一个任务不会用完槽位对应的资源,且其他任务也无法使用这些空闲资源。此外,Hadoop将槽位分为Map Slot和Reduce Slot两种,且不允许它们之间共享,常常会导致一种槽位资源紧张而另外一种闲置(比如一个作业刚刚提交时,只会运行Map Task,此时Reduce Slot闲置)。
4. 无法支持多种计算框架。随着互联网高速发展,MapReduce这种基于磁盘的离线计算框架已经不能满足应用要求,从而出现了一些新的计算框架,包括内存计算框架、流式计算框架和迭代式计算框架等,而MRv1不能支持多种计算框架并存。
为了克服以上缺点,Apache开始尝试对Hadoop进行升级改造,进而诞生了更加先进的下一代MapReduce计算框架MRv2。正是由于MRv2将资源管理功能抽象成了一个独立的通用系统YARN,直接导致下一代MapReduce的核心从单一的计算框架MapReduce转移为通用的资源管理系统YARN。
yarn在整个hadoop 2.x中的位置:
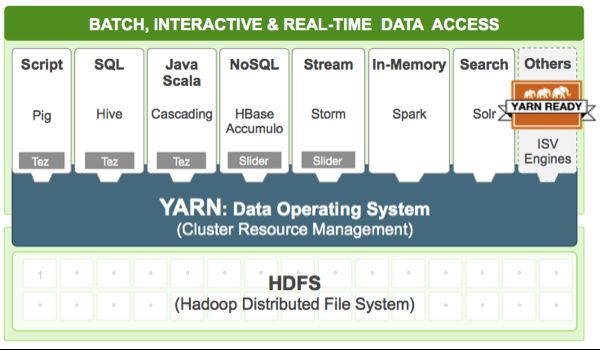
Yarn简介
Yarn是Hadoop集群的资源管理系统,当然也可以称之为弹性计算平台,之所以被称为平台,是因为它的目标已经不再局限于支持MapReduce一种计算框架,而是朝着对多种框架进行统一管理的方向发展。
这样做的好处是明显的:资源利用率高,运维成本低,数据共享等等。。。

Yarn基本架构
YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResourceManager负责对各个NodeManager上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会相互影响。
ResourceManager(RM)
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
调度器
ResourceManager 是基于应用程序对资源的需求进行调度的 ; 每一个应用程序需要不同类型的资源因此就需要不同的容器。资源包括:内存,CPU,磁盘,网络等等。可以看出,这同现 Mapreduce 固定类型的资源使用模型有显著区别,它给集群的使用带来负面的影响。资源管理器提供一个调度策略的插件,它负责将集群资源分配给多个队列和应用程序。YARN提供了多种直接可用的调度器,比如FairScheduler和Capacity Scheduler等。
应用程序管理器
应用程序管理器(ApplicationManager)负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
ApplicationMaster(AM)
用户提交的每个应用程序均包含一个AM,主要功能包括:
1. 与RM调度器协商以获取资源(用Container表示);
2. 将得到的任务进一步分配给内部的任务;
3. 与NM通信以启动/停止任务;
4. 监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
在1.0版本里,hadoop只支持mapreduce结构的job,这不是一种通用的框架。Yarn的出现解决了这个问题,关于Job或应用的管理都是由ApplicationMaster进程负责的,Yarn允许我们自己开发ApplicationMaster,我们可以为自己的应用开发自己的ApplicationMaster。这样每一个类型的应用都会对应一个ApplicationMaster,一个ApplicationMaster其实就是一个类库。
这里要区分ApplicationMaster*类库和ApplicationMaster实例*,一个ApplicationMaster类库何以对应多个实例,就行java语言中的类和类的实例关系一样。总结来说就是,每种类型的应用都会对应着一个ApplicationMaster,每个类型的应用都可以启动多个ApplicationMaster实例。所以,在yarn中,是每个job都会对应一个ApplicationMaster而不是每类。NodeManager(NM)
NM是集群中每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。需要注意的是,Container不同于MRv1中的slot,它是一个动态资源划分单位,是根据应用程序的需求动态生成的。
通信协议
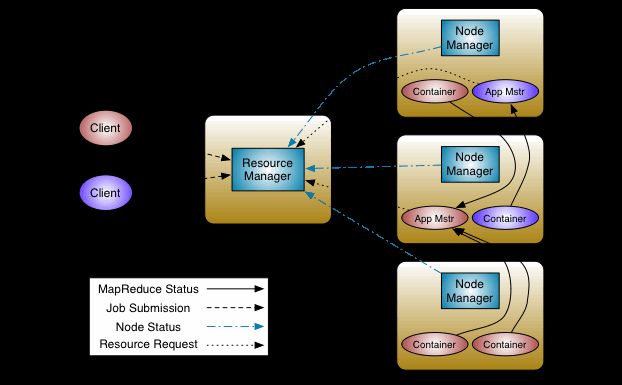
在YARN中,任何两个需相互通信的组件之间仅有一个RPC(远程过程调用)协议,而对于任何一个RPC协议,通信双方有一端是Client,另一端为Server,且Client总是主动连接Server的,因此,YARN实际上采用的是拉式(pull-based)通信模型。

箭头指向的组件是RPC Server,而箭头尾部的组件是RPC Client,箭头上标明的是协议名称,读者有兴趣可以自行了解。
Yarn工作流程

步骤1 用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
步骤2 ResourceManager为该应用程序分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
步骤3 ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
步骤4 ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
步骤5 一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
步骤6 NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
步骤7 各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态。
步骤8 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
对YARN的理解
当我看到调度器的时候我的第一反应就是,这个操作系统不是一样的吗,其实Yarn和HDFS可以看作组成了一个分布式操作系统,storm,spark,mapred之类的就像在OS上运行的程序。每个应用程序对于的ApplicationMaster就相当于主线程,然后再由ApplicationMaster负责数据切分、任务分配、启动和监控等工作,而由ApplicationMaster启动的各个Task(相当于子线程)仅负责自己的计算任务。当所有任务计算完成后,ApplicationMaster认为应用程序运行完成,然后退出。
参考文章
https://www.shiyanlou.com/courses/237/labs/764/document
https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/
http://blog.csdn.net/suifeng3051/article/details/49486927
《Hadoop技术内幕——深入理解YARN架构设计与实现原理》