Spark学习之7:Job触发及Stage划分
1. Job提交触发
流程图:
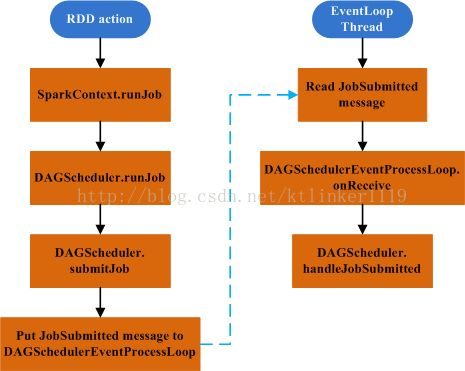
作业提交流程由RDD的action操作触发,继而调用SparkContext.runJob。
在RDD的action操作后可能会调用多个SparkContext.runJob的重载函数,但最终会调用的runJob见1.1。
1.1. SparkContext.runJob
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
allowLocal: Boolean,
resultHandler: (Int, U) => Unit) {
if (stopped) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, allowLocal,
resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
参数说明:
(1)func,将在每个分区上执行的函数;
(2)partitions,分区索引号,从0开始;
(3)resultHandler,结果聚合函数;
在job执行完成后,将调用RDD.doCheckPoint检查是否需要做checkpoint。
1.2. DAGScheduler.runJob
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
allowLocal: Boolean,
resultHandler: (Int, U) => Unit,
properties: Properties = null)
{
val start = System.nanoTime
val waiter = submitJob(rdd, func, partitions, callSite, allowLocal, resultHandler, properties)
waiter.awaitResult() match {
case JobSucceeded => {
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
}
case JobFailed(exception: Exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
throw exception
}
}
(1)调用submitJob函数,返回JobWaiter对象;
(2)由JobWaiter来等待Job的完成或失败。
1.3. DAGScheduler.submitJob
// Check to make sure we are not launching a task on a partition that does not exist.
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, allowLocal, callSite, waiter, properties))
waiter
(1)创建jobId;
(2)创建JobWaiter对象;
(3)将jobId,JobWriter等对象封入JobSubmitted消息并塞入DAGSchedulerEventProcessLoop的消息队列,DAGSchedulerEventProcessLoop对象包含一个消息队列及读取消息的线程。线程从消息队列中读取消息,根据消息的类型调用DAGScheduler的不同方法(具体见DAGSchedulerEventProcessLoop.onReceive)。
JobSubmitted消息将触发DAGScheduler.handleJobSubmitted方法的调用。
2. RDDs的Stage划分
2.1. DAGScheduler.handleJobSubmitted
var finalStage: Stage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = newStage(finalRDD, partitions.size, None, jobId, callSite)
} catch {
......
}
......
调用newStage方法创建RDD对应的finalStage,该RDD是调用action操作的RDD。
2.2. Stage划分流程
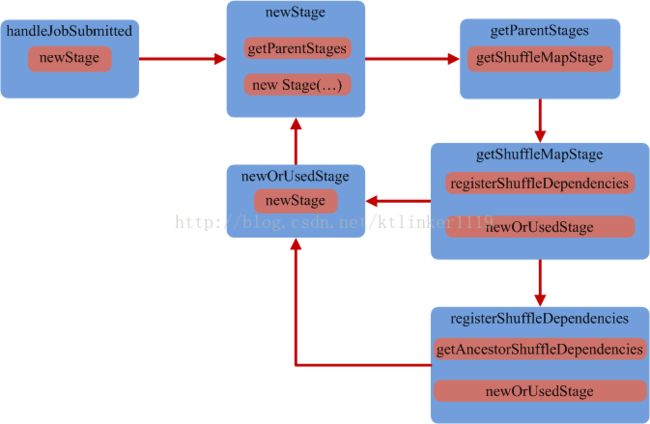
2.2.1. Stage
private[spark] class Stage(
val id: Int,
val rdd: RDD[_],
val numTasks: Int,
val shuffleDep: Option[ShuffleDependency[_, _, _]], // Output shuffle if stage is a map stage
val parents: List[Stage],
val jobId: Int,
val callSite: CallSite)
Stage有两种类型:
(1)shuffle map stage;
(2)result stage;
类结构说明:
(1)rdd,表示一个Stage中的最后一个RDD;
(2)numTasks,就是分区的数量;
(3)shuffleDep,如注释所说,如果该stage是shuffle map stage,则该字段表示输出shuffle,即有个RDD shuffle依赖该Stage的结果;
(4)parents,该Stage的父Stages。
2.2.2. DAGScheduler.newStage
private def newStage(
rdd: RDD[_],
numTasks: Int,
shuffleDep: Option[ShuffleDependency[_, _, _]],
jobId: Int,
callSite: CallSite)
: Stage =
{
val parentStages = getParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new Stage(id, rdd, numTasks, shuffleDep, parentStages, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
创建一个新的Stage。
从Stage的定义可以看出,创建Stage需要知道其父Stage信息。所以:
(1)先获取RDD(所在Stage)的父Stage;
(2)创建Stage id;
(3)创建Stage
从流程图知道,newStage可能会是一个递归的过程,在获取父Stage时,也需要获取其祖父Stage。
2.2.3. 举例
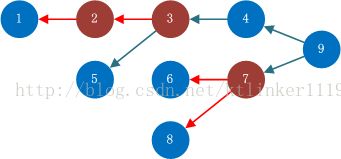
有这样一个RDD图,其中红色箭头表示RDD之间的Shuffle依赖(宽依赖),其他颜色箭头表示窄依赖。
在RDD9上执行了action操作。
我们要创建RDD9的stage。
Stage以ShuffleDependency为界进行划分。
2.2.3.1 DAGScheduler.getParentStages
获取RDD的parent stage。
private def getParentStages(rdd: RDD[_], jobId: Int): List[Stage] = {
val parents = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
// Kind of ugly: need to register RDDs with the cache here since
// we can't do it in its constructor because # of partitions is unknown
for (dep <- r.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
parents += getShuffleMapStage(shufDep, jobId)
case _ =>
waitingForVisit.push(dep.rdd)
}
}
}
}
waitingForVisit.push(rdd)
while (!waitingForVisit.isEmpty) {
visit(waitingForVisit.pop())
}
parents.toList
}
(1)将RDD9放入waitingForVisit栈中,并开始遍历该栈;
(2)从栈中取出一个RDD(即RDD9),它有两个依赖,都是窄依赖,所以将RDD4、RDD7压栈;
(3)取出RDD7,它有两个宽依赖,所以要获取宽依赖对应的shuffle map stage;
(4)取出RDD4,它只有一个窄依赖,所以将RDD3压栈;
(5)取出RDD3,它有一个宽依赖,有一个窄依赖,将RDD5压栈,计算RDD3对应宽依赖的shuffle map stage;
一个RDD的parent Stage要么为None,要么是一个shuffle map stage。
注:
在RDD间产生ShuffleDependency依赖的transform操作时,在创建ShuffledRDD过程中将deps初始化为Nil,并没有实际创建ShuffleDependency对象,但窄依赖是在transform操作时就创建好的。
RDD间的ShuffleDependency对象是通过调用RDD.dependencies创建的(如在该方法中调用r.dependencies)。
由于RDD的遍历是从大编号到小编号,因此先遍历的RDD(编号大)对应ShuffleDependency拥有较小的ShuffleId。
另,祖先Stage拥有较小的StageId。
2.2.3.2. DAGScheduler.getShuffleMapStage
private def getShuffleMapStage(shuffleDep: ShuffleDependency[_, _, _], jobId: Int): Stage = {
shuffleToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) => stage
case None =>
// We are going to register ancestor shuffle dependencies
registerShuffleDependencies(shuffleDep, jobId)
// Then register current shuffleDep
val stage =
newOrUsedStage(
shuffleDep.rdd, shuffleDep.rdd.partitions.size, shuffleDep, jobId,
shuffleDep.rdd.creationSite)
shuffleToMapStage(shuffleDep.shuffleId) = stage
stage
}
}
为了划分好Stage的复用,减少Stage划分支出,会将每个shuffle map stage保存起来。
(1)检查shuffle dependency对应的stage是否已经存在;
(2)若存在,直接返回对应的stage;
(3)若不存在,则先注册该
shuffle dependency所有祖先
shuffle dependency对应的stage,然后再创建当前
shuffle dependency对应的stage。
2.2.3.3. DAGScheduler.registerShuffleDependencies
private def registerShuffleDependencies(shuffleDep: ShuffleDependency[_, _, _], jobId: Int) = {
val parentsWithNoMapStage = getAncestorShuffleDependencies(shuffleDep.rdd)
while (!parentsWithNoMapStage.isEmpty) {
val currentShufDep = parentsWithNoMapStage.pop()
val stage =
newOrUsedStage(
currentShufDep.rdd, currentShufDep.rdd.partitions.size, currentShufDep, jobId,
currentShufDep.rdd.creationSite)
shuffleToMapStage(currentShufDep.shuffleId) = stage
}
}
(1)获取ShuffleDependency依赖RDD的所有祖先RDD中包含的
ShuffleDependency;
(2)getAncestorShuffleDependencies返回的是一个栈,由于RDD的遍历是从大编号往小编号方向,所以小编号的ShuffleDependency放在栈底,大编号的ShuffleDependency放在栈顶(如果在划分Stage之前就调用过RDD.dependencies,ShuffleDependency的编号就可能是乱序的)。
(3)从栈顶取出的ShuffleDependency的ShuffleId大。然后调用newOrUsedStage方法创建对应的Stage。从流程图中看出,在newOrUsedStage方法中将调用newStage方法。如果RDD位于RDD图的叶子端,对应的parent stage不存在,所以可以直接创建对应的Stage。
(4)保存新创建的Stage。
因此,祖先Stage拥有更小的StageId。
当祖先Stage都创建完成后,并且每个shuffle map stage都保存在以ShuffleId为key的HasMap中,我们可以从该结构获取父Stage。