爬虫:js分析,css 反扒
听说这个爬虫面试题很难?看完你就知道怎么做了
 locoz 关注
locoz 关注
2019.03.13 15:16* 字数 3626 阅读 235评论 0喜欢 2
最近有一个爬虫面试题(http://shaoq.com:7777/exam)在圈内看起来挺火的,经常在各个爬虫群里看到它被提到,而几乎所有提到这个面试题的人在题目限制的条件下就不知道该怎么办了,但这题目其实真的并不难,甚至可以说应该只是为了在招人时再过滤一遍只会写解析,拿着Selenium和代理池硬怼的人罢了(之前招人的时候见过很多,甚至有很多2-3年经验还处于这个水平)。
造成爬虫圈子现在这个情况的原因我觉得可能是因为各种爬虫书籍/培训班/网课都没有讲到过关于逆向方面的知识,他们的教学更倾向于Python语法、正则表达式、XPath这些非常基础的东西和常见爬虫框架/工具的简单用法,而读者/学员学完之后的水平充其量也就只能爬爬豆瓣之类的简单网站,面对有点简单反爬的就一脸懵逼,只能拿着Selenium和代理池硬怼。那么为了提升一下爬虫圈内的平均水平,写点别人没讲或者不想讲的东西并分享出来就很有必要了,这个专栏也是因此而生的。
扯远了,开始讲这个面试题吧,请站稳扶好,老司机要开始飙车了。首先做好以下准备,等会儿会用上,括号内是文中所使用的工具名或版本号:
- 浏览器(Chrome)
- Fiddler/Charles之类的抓包工具(Fiddler)
- Python和JavaScript的IDE或编辑器(Pycharm + WebStorm)
- Python3.x和NodeJS(Python3.6.5 + NodeJS10.15.1)
- Python库:pyexecjs、aiohttp、aiohttp_requests、lxml(最新版本)
- NodeJS库:jsdom(最新版本)
准备好了之后就可以开始了,先抓个包看看题目是啥样的。
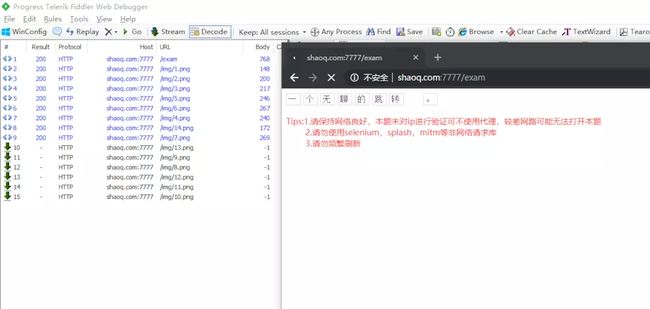
image
先是一个跳转页

image
然后会跳转到内容页,已经可以看到需要的文字了
看起来好像只需要拿到跳转后的HTML就行了?实际并不是,这里可以看到上面这一行字里除了“python”和“题”以外,其他的标签在HTML中都是没有文本内容的,对应的内容全都显示在了右边的CSS样式中。
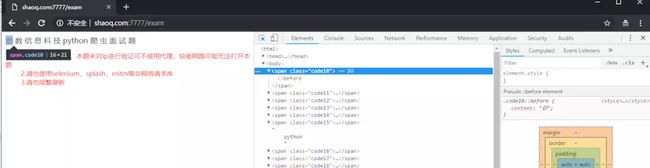
image
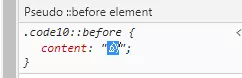
image
但是抓包的时候也没看到CSS,是不是把CSS嵌在了HTML中呢?打开这个HTML的代码看看,一大坨加密的JS一眼可见,也并没有看到style标签,显然这个CSS是通过JS生成后加进去的。
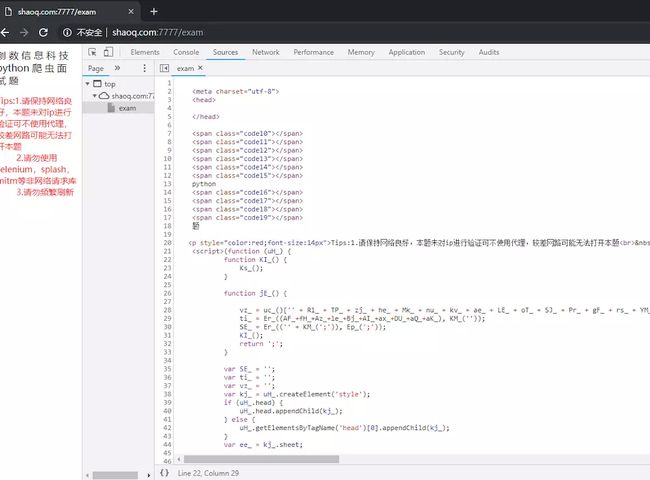
image
很多人对JS逆向毫无了解,看到这里已经懵逼了,碰到这种情况还不让用Selenium之类的工具,又要爬到内容,似乎完全没办法了啊。那应该怎么办呢?其实很简单,看完这篇文章你就知道应该怎么做了,下面我将用代码对这个面试题的考点逐个击破(完整代码将在文章结尾处放出)。
先请求一下这个URL看看会返回什么结果。
提示:aiohttp_requests库能让你在用aiohttp进行请求时能使用类似于requests库的语法,并且能正常使用session功能,而不需要写一层接一层的async with xxxxxxx。
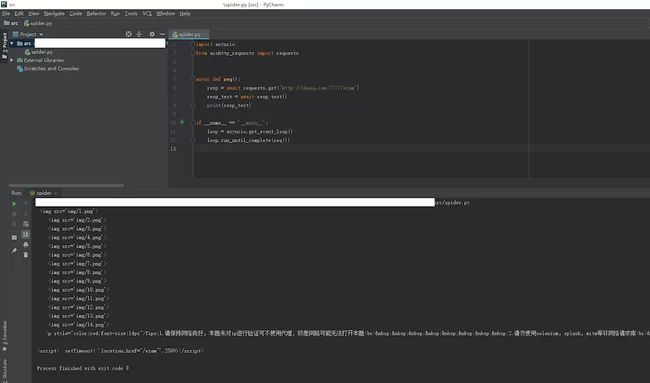
image
请求返回的结果是最开始的跳转页,距离真正的内容页还差一点距离
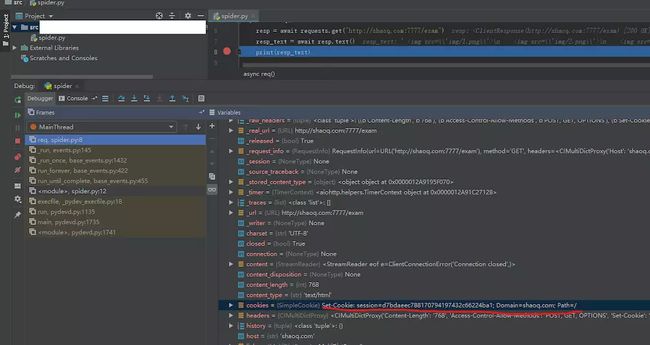
image
断点断下来看看resp,已经可以看到一个名为session的Cookie被set了,之前抓包的时候也是有看到服务器返回这个Cookie的。那么直接带着这个Cookie再次请求是不是就可以拿到那个内容页了呢?我们将代码改一下,对这个URL再次请求:
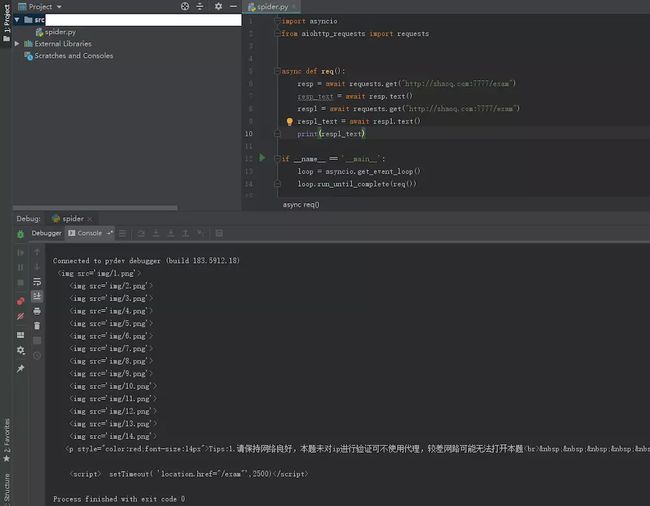
image
![]()
image
咦?有了这个Cookie之后的请求怎么还是返回这个跳转页呢?
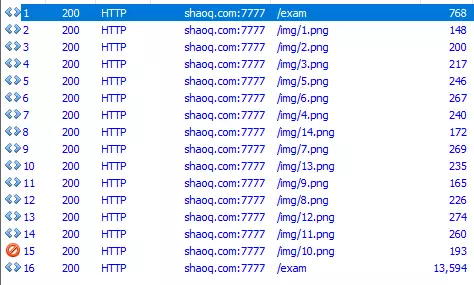
image
现在再回到抓包工具中仔细看看,是不是发现抓到的浏览器请求里这两个请求之间是有一堆图片的,且第二次请求时,请求头里的东西也没有啥变化?
是这样的,其实它的服务端对客户端是否加载了图片进行了判断,如果客户端没有加载图片就直接开始取内容,那除了网速慢和刻意关闭了图片的人以外,基本就可以确定是爬虫了,所以这是一个简单粗暴的反爬措施。
知道了这个考点之后就很简单了,取出图片的URL并和浏览器一样进行请求就好了。再次修改代码:
提示:因为这里重用host部分的次数很多,我把host部分写成了一个常量。
提示:f"{HOST}{image.get('src')}"是format string,python3的一个语法糖,最开始有这个语法糖的版本已经记不清了,如果你发现这段代码在你的环境里无法运行,可以把这里改成"{}{}".format(HOST, image.get("src"))。
提示:asyncio.gather是asyncio库的并发执行任务函数,传入的是一个协程函数列表,所以里面的requests.get不需要加await。
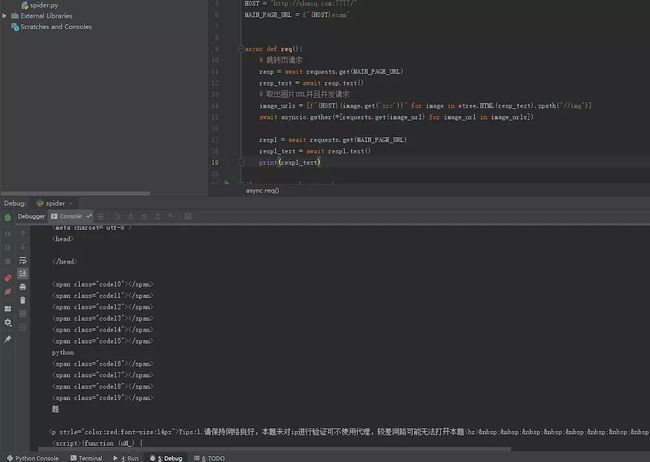
image
可以看到已经取到了内容页的HTML,第一个考点我们已经跨过去了,接下来要想想怎么拿到那个CSS的部分了。
那么这个JS要怎么处理呢?其实我们可以使用Python调用JS的方式去执行它页面中的那段代码,从而生成出标签中对应文字部分的CSS。这里推荐使用pyexecjs库 + NodeJS来执行JS代码,pyexecjs库可以说是目前最好的Python执行JS代码的库了,另外一个比较常见的库——PyV8,存在严重的内存泄漏BUG,不建议使用。
但是直接执行这段JS代码是不可能有用的,我们还需要分析一下它的内容并按我们的使用方式修改一下。先把那段JS复制出来,打开JavaScript IDE/编辑器,并把它丢进去进行分析。
image
此处省略几百行变量
image
可以看到script标签里是一个匿名函数,传入了一个document参数(函数内的uH),而实际这个匿名函数的主要流程代码非常地少,只有两个部分。
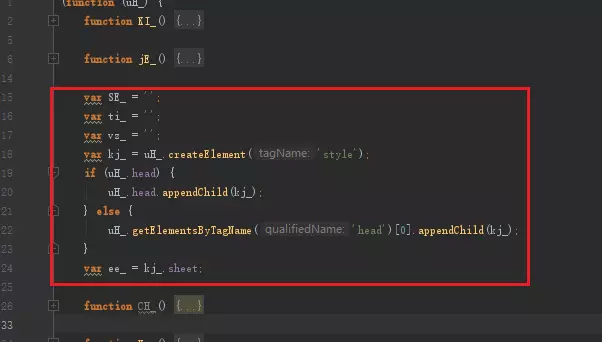
image
一个是开头的这里
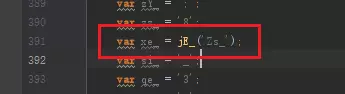
image
一个是靠近结尾位置的这里
第一部分没有做什么操作,只是创建了一个element,那么核心部分应该就是第二部分,跳到它调用的jE_函数看看。
提示:WebStorm中可以用鼠标中键或Ctrl+鼠标左键点击jE_,跳转到对应的函数位置

image
这个jE_是这么一坨看不懂的东西,看不懂就没法搞了,怎么办呢?仔细看看上面那些用到的变量,是不是都是那一坨给变量赋值的地方出来的?那么我们只需要把那一串加起来的东西写成一个新的变量,打个断点在下面然后运行一下,就能直接看出它是啥了。(更高级的加密JS在还原时需要用到AST解析库和相关知识写工具处理而非手动处理,这里暂时还不需要用)
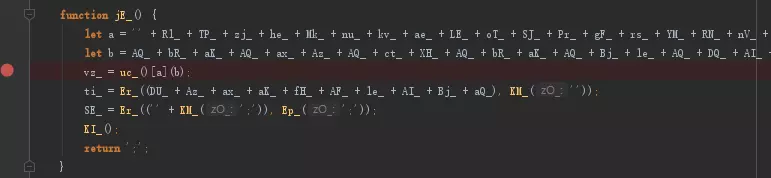
image
等一等,现在你还不能运行这段代码,因为你没有document,document是浏览器中特有的一个全局变量,而NodeJS中是不存在document这东西的,是不是觉得事情有点麻烦了起来?没关系,问题不大,既然NodeJS中没有,那我们就自己造一个,这里使用jsdom库来模拟浏览器中的dom部分,从而做到在NodeJS中使用document的操作。当然你如果想要自己造也是可以的,只需要按着报错提示一个一个地实现这段JS代码中调用的document.xxx即可。
这个jsdom库的使用方式很简单,只需要按照文档上的说明导入jsdom,再new一个dom实例就可以了。
Basic usage
const jsdom = require("jsdom"); const { JSDOM } = jsdom;To use jsdom, you will primarily use the
JSDOMconstructor, which is a named export of the jsdom main module. Pass the constructor a string. You will get back aJSDOMobject, which has a number of useful properties, notablywindow:const dom = new JSDOM(`Hello world
`); console.log(dom.window.document.querySelector("p").textContent); // "Hello world"
注意了,这里的dom变量还并不是我们要的document变量,真正的document变量是dom.window.document,所以我们的代码可以这样写:
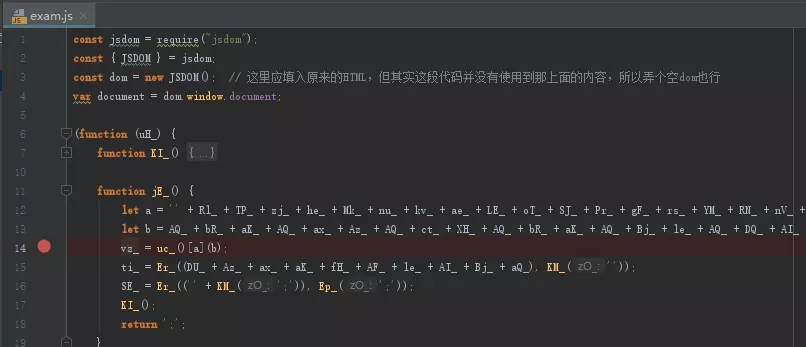
image
执行一下看看效果
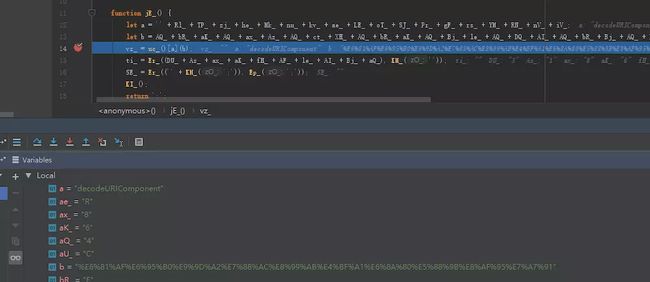
image
原来上面的两个参数分别是decodeURIComponent和%E6%81%AF%E6%95%B0%E9%9D%A2%E7%88%AC%E8%99%AB%E4%BF%A1%E6%8A%80%E5%88%9B%E8%AF%95%E7%A7%91,我们把后面那段一眼就能看出是经过urlencode的字符串还原一下看看。
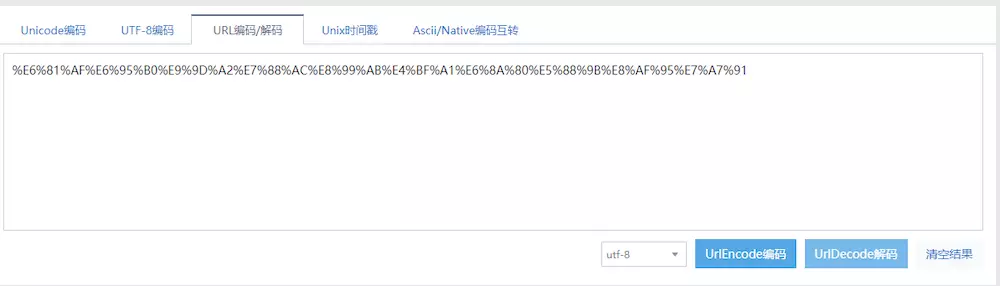
image
image
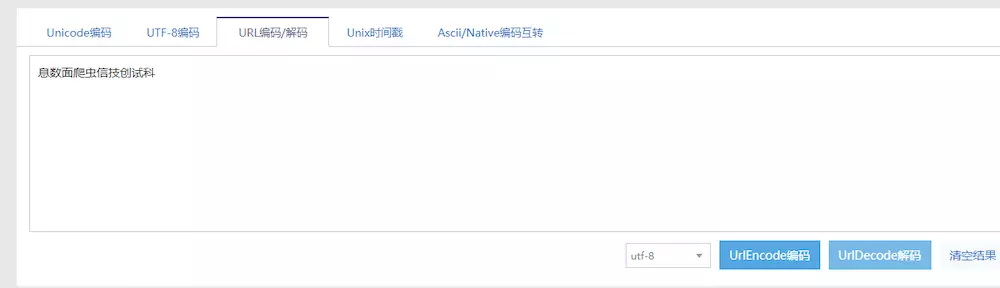
嗯...其实就是页面上的那句话了,只不过它是乱序的,我们接着往下执行看看它还做了什么操作。
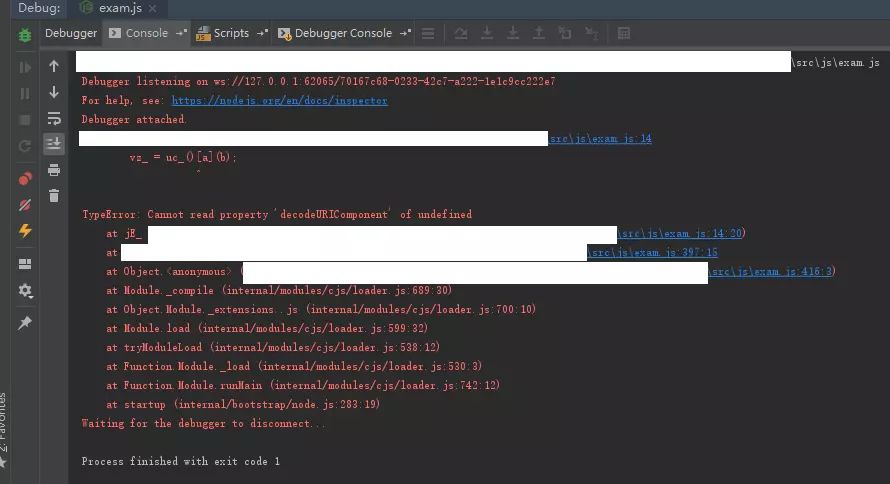
image
往下执行时报错了,看起来是缺少了decodeURIComponent这个函数,那decodeURIComponent前面的那个uc_又是什么呢?用同样的方式可以看到,其实是window。

image
也就是说这句代码还原成正常的样子其实就是this.window.decodeURIComponent("%E6%81%AF%E6%95%B0%E9%9D%A2%E7%88%AC%E8%99%AB%E4%BF%A1%E6%8A%80%E5%88%9B%E8%AF%95%E7%A7%91"),而NodeJS的decodeURIComponent并不在this.window中,所以我们还是需要通过最开始造document的操作,再给它弄一个this.window.decodeURIComponent,代码很简单,改成这样即可:
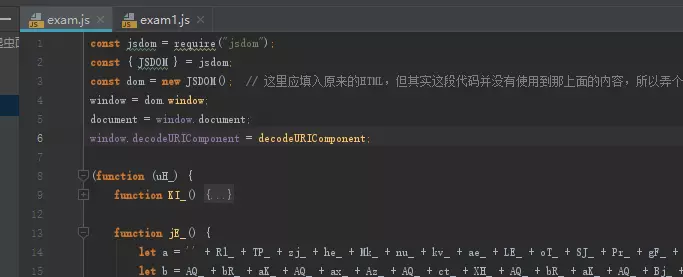
image
然后我们再执行一遍
image
这次就能正常运行完毕了,但是我们要的东西去哪儿了呢?我们继续往下打断点看,vz_是乱序的文字,ti_是一个里面只有数字的数组,SE_则只有两个空字符串,KI_函数没有进行赋值,而最后的return其实是没有任何作用的,因为jE_在主流程中是最后一个被执行的函数,它返回的值赋给了xe_后并不会被使用。所以这里似乎只有SE_和KI_比较可疑了,断点进入给SE_赋值的Er_函数看看。

image
看来这个Er_函数并不会做什么,那么我们要的核心部分可以确定就是KI_这个函数了。接着追到下面的KI_函数。
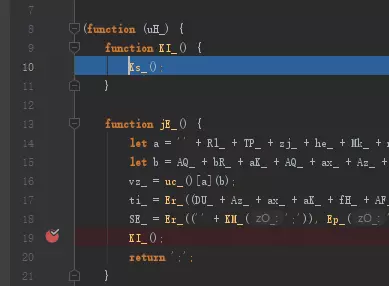
image
这里它又调用了一个叫Ks_的函数,跟着它继续往下跳。

image
又是熟悉的Er_,还记得刚刚看到的吗,它只是做了一个split操作而已,ti_是前面那个只有数字的数组,这里的NL_只不过是按顺序取了一个ti_里的元素罢了,下面没见过的BD_和Je_才是重点。

image
这里断下来看出BD_其实是一个取前面那串乱序字符串中其中一个文字的东西,继续往下执行可以看到最终出来的YO_是一个字。
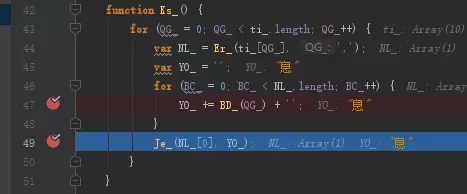
image
那么Je_呢?继续往下执行看看
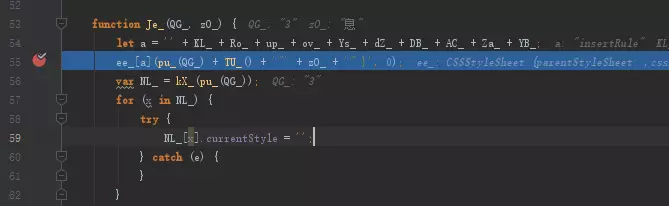
image
Je_里调用了ee_.insertRule,而ee_是前面被赋值的

image
![]()
image
所以实际上它是新建了一个element并往里面写了我们要的CSS。看到这里,其实这个考点已经被破掉了,我们只需要读出ee_返回给Python,就可以把那段文字给恢复出来了。
将JS代码再修改一下:
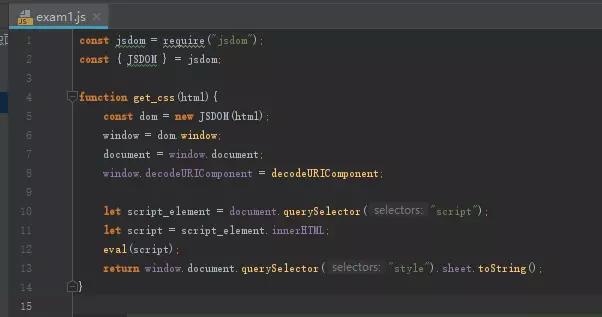
image
然后我们试一下能不能用,记得将这里的html字符串替换成你请求时返回的。(通常这种用到浏览器内特有的一些变量的JS都会埋下一些坑,建议读者养成完全模拟浏览器环境的习惯,当然如果不怕遇到坑的话只给JS中需要用到的东西也可以,而这个题目本身并没有这种坑,所以只弄一个空的dom并且魔改一下只传入字符串和数组部分也能用。)
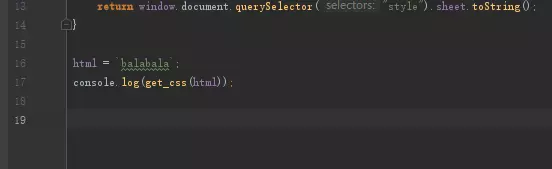
image

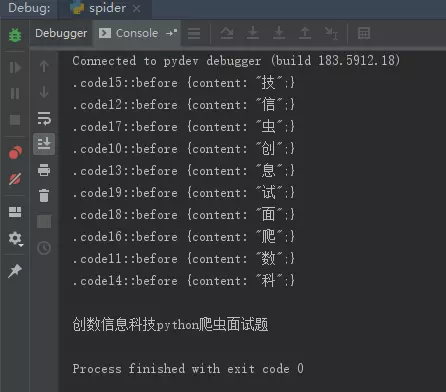
image
boom!CSS成功地被我们拿到手了,左边的codexx对应右边的content部分文字,与浏览器中的一模一样,JS部分算是搞好了,我们要继续写我们的Python代码,先把html=xxx开始的部分全部删除掉,只保留上面导入包的部分和get_css这个函数的部分。
回到Python代码部分,修改成调用JS得到CSS后处理一下CSS和HTML的对应关系,并取出所有文字内容再打印出来。
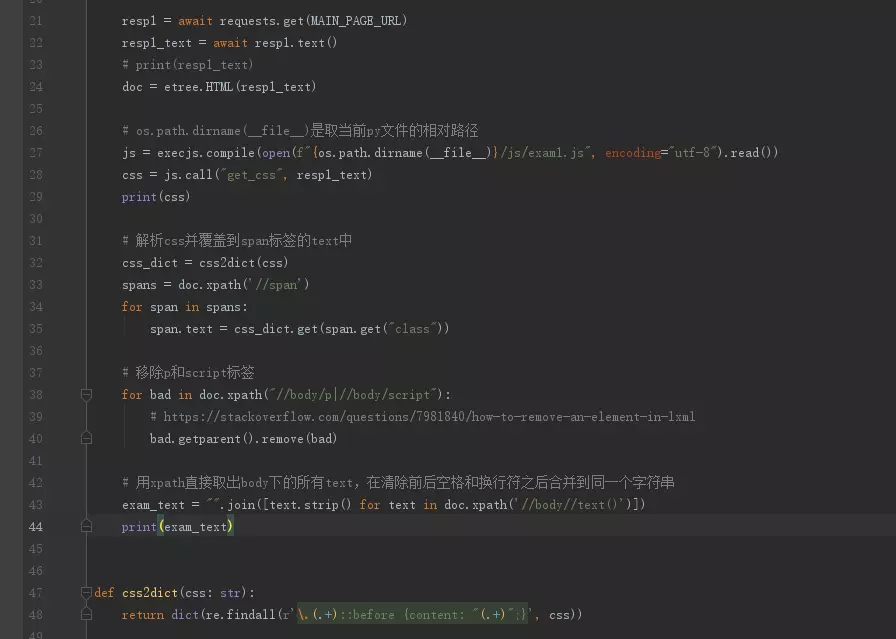
image
提示:这里的dict(list)是一个Python的语法糖,可以快速地将[[1,2],[3,4]]转成{1:2, 3:4}
提示:这里可能会出现一个问题,之前直接用NodeJS执行没问题的代码,经过PyExecJS调用之后却报错了,这个问题似乎只有在Windows系统上才会出现,主要原因应该是Windows的编码问题,碰到这种情况可以用Buffer.from(string).toString("base64");将返回的字符串编码为Base64,在Python中再进行解码。
image
执行一下看看,是不是已经拿到了需要的那行字了呢?
image
文中代码传送门
如果这篇文章有帮到你,请大力点赞,谢谢~~ 欢迎关注我的知乎账号loco_z和我的知乎专栏《手把手教你写爬虫》,我会时不时地发一些爬虫相关的干货和黑科技,说不定能让你有所启发。