大数据项目性能优化实战
项目背景
领导:项目 X 二期接近交付,目前性能问题比较严重,解决一下;原因可能是 kafka 单线程效率不足。
客户:该模块每 2 分钟经清洗计算生成的处理结果量应该在 13 万,实际查询到的数量只有 7 万。
原研发:可能是 kafka 性能问题,因为硬件上不足以修改多进程,多线程版本应该可以。该模块数据流是读取 kafka--> 过滤 --> 写入 snappy。
Part 1: 头痛的海量代码,可以偷个懒不?
git 私服下载项目代码后,整个人都不好了。两个模块,32 个工程,文档没有,注释没有,天了噜~
面对如此境遇,还是选择了优先踩在前人的肩膀上来实现(偷懒还是需要付出代价的~)。找到 kafka 单线程数据流所涉及的模块,准备进行多线程改造。
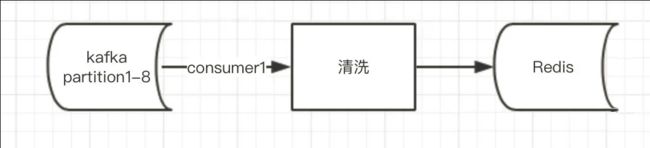
查看对应工程代码,数据流大致如图一:

众所周知,kafka partition 和消费者的关系是一个 partition 只能由一个消费者进行消费,而一个消费者可以消费多个 partition。鉴于目标是确认性能问题点,便将单线程版本改为 8 线程,每个线程处理一个固定 partition 的数据。然并卵,修改后的版本性能并没有提升,果然事情不会这么简单~转而询问研发得知由于项目周期紧,并未对 snappy 的性能进行过测试。好吧,测试走起。在测试环境中进行基准测试,按照原代码中 2000 条每次批量写入的方式,发现单线程写入每次的耗时约 150-200ms。所以保守估计可以支撑 8000/s。如此看来 snappy 也并未达到瓶颈。这一眼就能看穿的数据流,还能灵异事件了不成?
那么问题来了,这个性能问题是如何得出的?问题的本身是可靠的么?
再次询问客户,性能问题是怎么判断出现在模块 A?
场景还原:
图一为正常数据流;

为验证数据准确性,客户另开一条数据流,数据写入 redis,数据过期时间设置为 2 分钟:
现象:
从 snappy 中查询到最近两分钟的数据量约 7-8 万
从 redis 查询数据总量大约为 13 万。
新增测试方案:
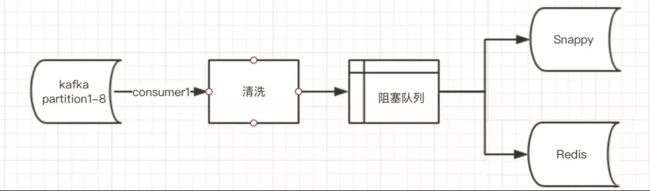
记录阻塞队列读出的数据量,实际为每 2 分钟为 8 万左右;与 snappy 的数据量大致相同,而 redis 的数据量此时仍为 13 万左右。
那么问题来了,这是为啥子?
看一下 redis 官网的数据过期清除机制:

如上图,redis 的过期数据并不会实时全部删除,而是按照采样删除策略进行的。看一下 redis 中文网的翻译吧:

真相大白:验证方式不可靠。只是因为 redis 过期策略被误以为是过期便删除而导致。(ps:有兴趣的小伙伴对应中英文翻译一下,有木有发现中文版最后的翻译有 bug?-_-)
问题到此并未终止。客户说,我们做这个测试的原因是 snappy 中的存在超时数据。我们的验证方式有问题,那你们出方案解决数据延时问题吧。故事由此正式开始。
Part 2: 老老实实读代码
不知各位小伙伴有木有读开源项目或者类似工程代码,工作中的不少小伙伴每遇及此都很头痛。其实不管是读优秀的开源项目还是一般的开发代码,都是一件有意思的事情。取其精华去其糟粕的过程是能力提升的良方。
讲个 demo 吧:
不知各位小伙伴有木有踩到过天天见的 if&else 的坑,是不是在写 if&else 的时候会不会关注只有 if 没有 else 可能导致的 bug。在此次代码阅读过程中发现一个 if&else 导致的困扰许久的问题。伪代码场景还原一下:
子进程与调度进行心跳,心跳的同时进行时间同步。
long currentTimestamp = 0;
public TaskJobInfo[] workerHeartbeat(){
ClientResponse response = client.heartbeat(currentTimestamp);
if(response.get("code").toString().equals("success")){
doTimestamp();
}//没有else,也没有把dotimestamp放在finally。
}
public void doTimestamp(){
ClientResponse response = doHeartbeat(currentTimestamp);
if (response.getStatus() == 200) {
return response.get();
}else{
return 0;
}
}
服务类:
//rest服务接口
@RequestMapping("/heartbeat")
public void doHeartbeat(){
if(currentTimestamp <1){
Model model = new Model();
model.setCode("error");
return model;
}else{
do();
}
}
//rest服务接口
@RequestMapping("/timestamp")
public void doHeartbeat(){
return System.currentTimeMillis();
}
上述代码会出现怎样的问题?
当时间同步服务出现故障,哪怕是一次网络抖动导致的 500 错误,currentTimestamp 会被置为 0. 而当以 currentTimestamp==0 为参数进行 heartbeart 请求时,将不再返回 success,之后的心跳过程将进入永远 error 的死循环直到调度认为进程死掉。读到这样的代码,必然会引起自己对类似处理的警惕性,迫使自己加强代码规范性。
言归正传,对于项目代码阅读,个人习惯的处理方式如下:
第一步:抓大放小,不执着于细节;从工程的入口开始,只关注数据流向和线程处理模型,粗略的在纸上画出数据流图。一般需要两个小时的时间,可以尽快的对整个工程的实现框架有基本的了解。PS:在代码跟踪过程中,涉及 web 服务调用和动态类加载调用会较为费劲一些,没啥好办法就只能全局检索了。
第二步:从数据流图中分析可能的性能问题点,逐一分析。
大致数据流:

ps:map 中存储的是 etl 中的数据,数据缓存期为 30s,超过 30s 的数据进一步处理输出。
Part 3: 性能分析与优化
请参看上图,有哪些点是可能存在性能问题的呢?
1.kafka topic 的使用。想象一下,来自 topic1 的 6 万 /s 的原数据经过 etl 处理之后生成 8000/s 的结果数据再次写回 topic1. 这样后续处理结果数据的模块将以性能损耗 8 倍为代价进行消费和过滤,同时消费原数据的模块也将增加数据消费和过滤的损耗。明显是性能问题的凶手之一。
一个字,拆。将 kafka topic 一分为二。(不要纠结于原设计的初衷哦,原设计有历史原因请忽略)
2.partition,也就是说只有 8 个 consumer(8 个线程进行数据拉取处理)8 个 consumer 能否消费该数据量的数据呢?测试:将 topic 的数据拉取之后做时间判断打 log 后丢弃,不进行后续处理,发现数据仍有超时。显然,效率不足。 扩展:将 partition 数量由 8 扩展为 24,同时对应的 consumer 提升为 24.
3.多线程处理。项目中充满了线程池,每个线程池的使用是否合理?讲真,项目中的多线程和缓存队列的使用还是可圈可点的。除了配置不当外基本合理。在类似项目中使用 ThreadPoolExecutor 时建议使用有界队列 ArrayBlockingQueue 进行合理优化配置,减少无界队列的使用。避免资源耗尽。
4.map 处理。上文提到,map 是用来缓存 30s 的数据,原实现中,每次 kafka 拉取数据 etl 处理写入 map 之后同时遍历 map 一次以便可以消费掉超过 30s 的数据。想象一下,30s 的数据可能达到 150 万条,同一线程中占用 etl 处理时间可能产生的性能影响。原实现考虑的是多线程难以保证 map 的同步。建议不要因为 concurrenceHashmap 性能会比原生 map 要差些就采用这样的方式处理。使用 concurrenceHashmap 同时提出一个线程专门进行 map 的定时遍历消费效果要好得多。
5.阻塞队列。LinkedBlockingQueue 在此类项目中建议使用 put 而非 offer。即便将 queue 的 size 设置较大,也难以避免在性能问题出现时 queue 爆满而导致的数据丢失。
6.日志:在问题排查过程中,发现关键节点基本没有日志可查。建议在日常编码中数据关键节点保留 debug 日志。如上图,在 kafka 拉取,各 queue 的当前 size,map 轮询后的剩余 size 等关键节点保留 debug 日志,在性能问题出现时将为问题排查提供极大的遍历。
7.在上述问题处理之后,性能由原来的 2.6/s 提升为 4.5 万 /s,再次到达瓶颈。那么问题会出在哪儿呢?不知大家有木有遇到过多线程性能瓶颈切换多进程得以解决的情况。在上述问题处理之后,我们选择进行进程拆分。将单进程拆分为 3 个进程,每个进程处理 8 个 partition 的数据。性能成功的达到 6 万 /s 的需求。进程拆分会减少单一 jvm 和线程锁竞争的性能问题。就像 kafka 的生产者和消费者最好是分为两进程避免在数据量暴增之后生产消费直接资源争抢导致的数据堆积;另一方面进行多进程拆分也是为了数据继续增长时可以从容的进行集群化。