YOLO V2解析
YOLO V2是YOLO系列的第二版,在YOLO V1的基础上加以改进,改善了YOLO V1定位不准的问题,又保证了检测的速度,可谓集准确性与速度于一身(YOLO V2获得了CVPR2017的最佳论文提名)。YOLO V2的原文提出了两个模型:YOLO V2和YOLO9000,本文主要着重YOLO V2,下面让我们一同走进YOLO V2的世界。
Outlines:
- YOLO V2 vs V1;
- YOLO V2的3个核心;
- YOLO V2的损失函数;
1. YOLO V2 vs V1
YOLO V2的mAP和FPS:
首先,我们明确一点,V2强于V1(速度和准确率),并且可与Faster RCNN,SSD媲美,确切来说在Pascal VOC上,V2准确率比V1高出10%,同时最慢的版本速度可以持平V1。那么我们下面看看YOLO V2在Pascal VOC上的精彩表现:

图1 YOLO V2在Pascal VOC2007上的mAP和FPS统计
我们发现,YOLO V2的准确率远高于V1(78.6 vs 63.4),同时速度更快,而且相比于SSD和Faster RCNN,准确率与速度都不逊色。

图2 YOLO V2在Pascal VOC2012上的mAP统计
可以发现YOLO V2在Pascal VOC2012上表现得也很强势;
下面我们看看在COCO上V2的表现如何呢?

图3 YOLO V2在COCO test-dev2015上的mAP统计
不难发现在COCO上,YOLO V2的mAP不敌SSD和Faster RCNN,这也说明在目标种类增多以及尺度变化增大的情况下,YOLO V2会稍显弱势。
YOLO V2相比于YOLO V1的改进:
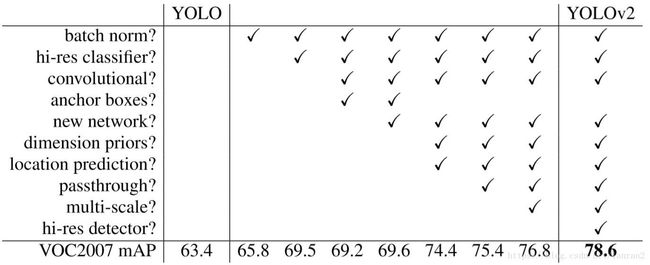
图4 YOLO V2 vs V1
上图诠释了YOLO V2相对于V1的各个方面的改进以及每种改进所带来的提高,下面我们一一分析。
1)增加Batch Normalization层 (+2%)
在V1的基础上增加了BN层,位置在Conv层的后面,同时去掉了Dropout,增加BN层后,给YOLO 的mAP带来了2%的提升,也说明了BN的重要作用。

图5 BN的位置
2)使用高分辨率的分类器 (+4%)
在训练物体检测任务时,会使用ImageNet上预训练的模型作为特征提取器,而其训练时,输入图像分辨率通常在224x224左右,而训练物体检测任务时,需要分辨率更大的图像(因为图像越大,越清晰,越容易检测上面的物体),,这样就会造成两者在输入图像分辨率上的不一致;比如YOLO V1,在224x224大小的输入图像上训练检测模型,然后将图像分辨率提升至448x448,在检测数据集上Finetune。为了更好的适应分辨率的差异,YOLO V2选择先在ImageNet上Finetune高分辨率(448x448)的模型(10 epochs),然后再训练检测模型,这样就“弱化”了分类模型和检测模型在输入图像分辨率上的“不一致”。使用高分辨率分类模型,给YOLO带来了4%的mAP提升。同时YOLO V2提出了新的网络结构DarkNet-19,顾名思义就是指19层卷积,具体的结构如下图所示:
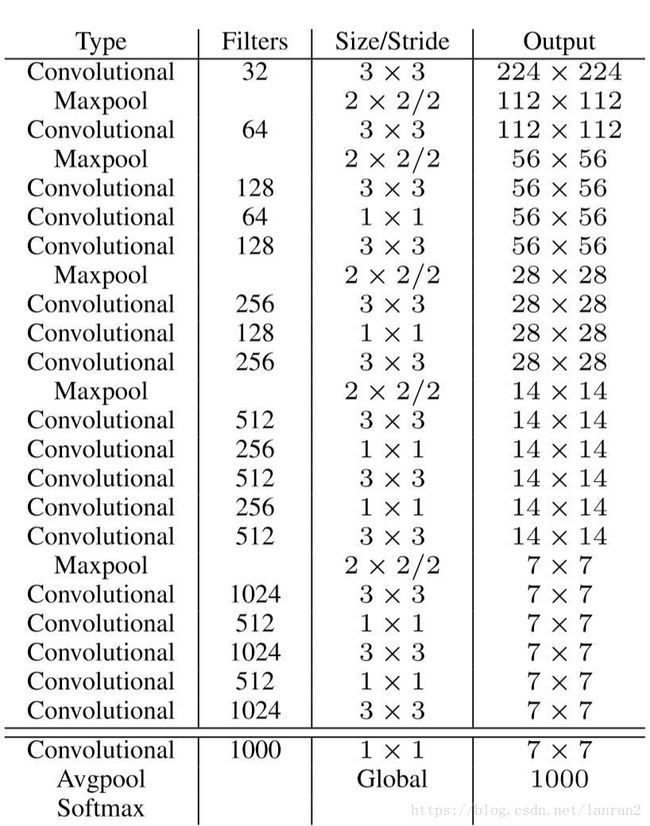
图6 DarkNet-19的结构图
DarkNet-19在ImageNet上Top1的准确率为72.9%,其中我们可以发现里面有很多1x1的Conv在Channel维度上压缩特征图。
3)使用Anchor的思想 (-0.3%)
YOLO V1没有Anchor的概念,而且候选框一共98个(7x7x2),所以可想而知,模型的Recall是个问题,所以YOLO V2为了增加Recall(如果连正确的框都没有检查出来,就更不用想着后续的优化了,所以需要增加Recall),使用了Anchor的概念,像Faster RCNN,一个Anchor会产生9个候选框,这样在YOLO V1的情况下,原本的98个框就变成了441(7x7x9)。
同时为了进一步增加候选框的数目,YOLO V2中最后用来预测的特征图尺寸是原图的1/32(YOLO V1是1/64),由于448 / 32 = 14,这样一来图像中心点是4个点(图7方便理解),这样就会导致在图像中心的物体的中心点落在4个Grid Cell中,不方便分配,所以作者把输入图像的尺寸改成了416(416/32=13),中心点只有一个。增加了Anchor的概念后,mAP由原来的69.5%降低到了69.2%,但是Recall从81%增加到88%,这也为后续的优化提供了可能性。
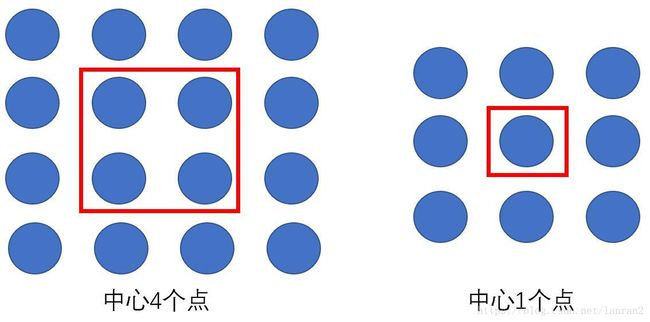
图7举例说明为何选择13x13而不是14x14
4)K-means聚类获取Anchor框 + 直接预测位置 (+5%)
像Faster RCNN,Anchor产生的9个候选框是“人为”选择的(“瞎编”出来的),YOLO V2为了选择更合理的候选框,使用了聚类(K-means)的策略,选出最具有代表性的5个尺寸作为Anchor候选框的尺寸。
同时YOLO V2虽然使用了Anchor的思想,而预测框的坐标时依然使用YOLO V1的策略,直接预测坐标相对于Grid Cell的位置,而不是Anchor Box与Ground Truth之间的Offset。(具体K-means和Anchor思想如何使用的,后文会详细介绍)
5)细粒度的特征 (+1%)
考虑到13x13的特征图,对于小物体不是特别奏效(很小的物体在下采样32倍的情况下就消失了),所以YOLO V2使用13x13的特征图的同时,又利用了26x26大小的特征图,将两个尺寸的特征图结合。具体过程如下图:
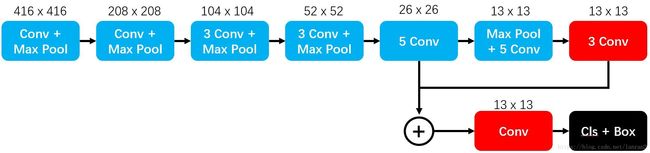
图8 YOLO V2整体结构图
图8展示了YOLO V2的具体流程,其中+代表Concatenate操作。
6)多尺度训练
为了适应不同尺寸的输入图片,YOLO V2采用了多尺度训练的策略,尺度的选择:从320到608,{320,352,…,608},每隔32选取一个尺度(其中320/32=10,与上文奇数尺寸相违背了,有些尴尬)。训练的时候,系统每隔10个batch,随机从这些候选尺度中选择一个进行训练。“多尺度”在目前的物体检测训练中,已经属于常见的操作了。
2. YOLO V2的3个核心
下面有针对性的看看YOLO V2中的3个比较重要的元素,1)如何通过K-means选取Anchor候选框尺寸;2)YOLO V2中如何利用Anchor思想;3)如何实现细粒度特征的;选择这三个元素,主要是因为本人在读论文时,深感这三点的美妙,其他诸如BN,大分辨率,多尺度训练等技巧在其他物体检测论文里也很常见。
1)如何通过K-means选取Anchor候选框尺寸?
K-means是聚类的方法,最后得到K个聚类中心以及每个样本属于哪个中心,其中K是聚类的个数,需要人为指定,其中使用“距离”来衡量每个样本与聚类中心的关系,通常使用欧式距离,但是对YOLO V2来说,需要选取框的尺寸,衡量的标准应该是“覆盖率”,所以YOLO V2利用IOU来计算,所以距离公式如下:
d(box, centroid) = 1 – IOU(box, centroid)。
论文里,人为设定K=5,这样就完成了K-means计算Anchor候选框尺寸的过程。。。

首先一个问题是,如何计算IOU?大家头脑里浮现的往往是:
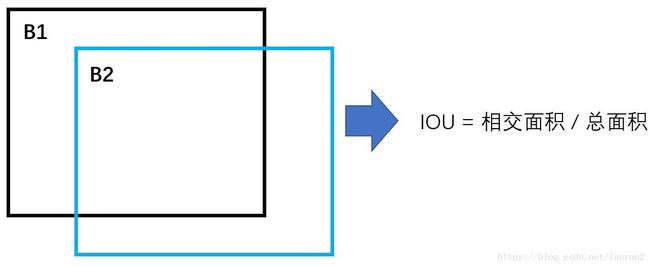
仔细想想,这是不可能的,为什么,因为我们聚类目标仅仅是W和H,并没有X,Y的概念,也就是说我们需要在IOU的计算中去掉X,Y,所以能想到的方法就是将两个框的“中心点对齐”,然后再计算IOU,计算的过程如下:

有了IOU的计算方式后,我们再来看看如何通过K-means的思想得到5个候选框尺寸。首先这里向大家抛出一个小问题,最后得到的5个尺寸一定会是样本集合中的某个值么?

上图就是K-means计算5个候选框尺寸的过程,也回答了上面的问题,因为是相加取平均的结果,所以往往不会是已知的样本尺寸。
2)YOLO V2中如何利用Anchor思想?
跟Faster RCNN相同的地方,YOLO V2使用了Anchor的概念,其中在处理W和H的部分基本一致,我们设置Anchor框的Wa和Ha,Ground Truth为W和H,那么最后回归的目标为:
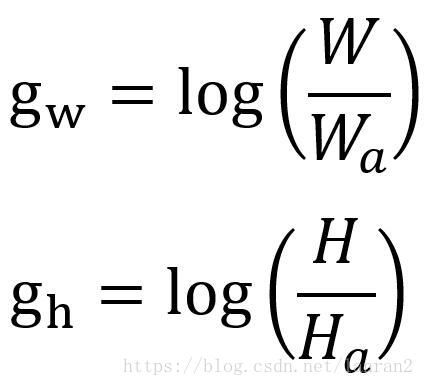
这样避免了YOLO V1中直接回归W和H的尴尬。
与Faster RCNN不同的是,YOLO V2回归的目标没有选择Offset,而是选择YOLO V1的策略,我们这里回忆一下Faster RCNN是如何做的,我们设置Anchor的坐标Xa和Ya,Ground Truth的坐标为X和Y:

YOLO V2指出这种做法是存在风险的,什么风险呢,假设我们最后的预测结果为tx, ty, tw, th,那么最后预测的框的坐标为:
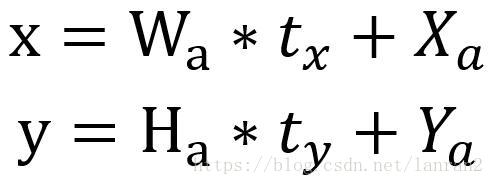
从上述公式发现,如果tx=1,那么最后的结果相对于Anchor向右偏移了1倍(同理,tx=-1,则是向左偏移了1倍),说明这种回归目标对取值范围“约束”很弱,这样最后得到的框会出现在图的任何位置,训练就很难稳定下来,为了解决这个问题,YOLO V2沿用了V1的策略,直接预测坐标相对于Grid Cell的位置,计算公式如下:
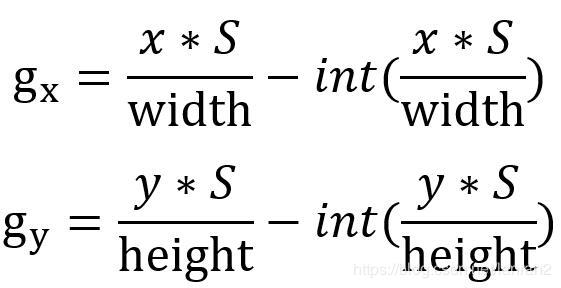
其中x,y为物体的中心点坐标,分成SxS个Grid Cell,针对YOLO V2,S=13,width和height为原图的宽和高。
同时也说明了YOLO V2分配训练样本的策略与V1相同,物体的中心点落在哪个Grid Cell中,其对应的Anchor候选框负责这个物体。
3)如何实现细粒度特征的?
有两种实现策略,原版和改进版。
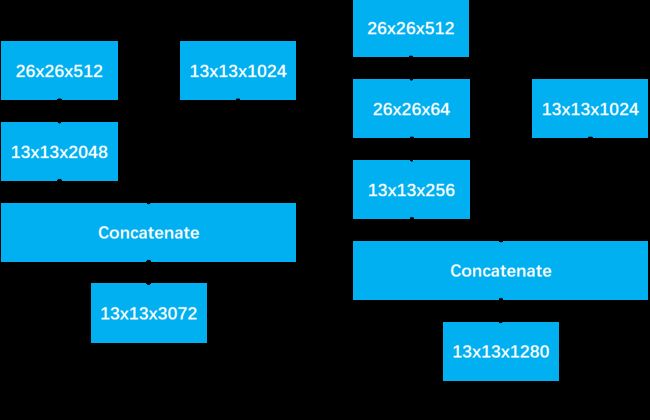
原版:首先需要两个特征图26x26x512和13x13x1024,分成两步,1)26x26x512的特征图重组成13x13x2048的特征图;2)将13x13x2048的特征图与13x13x1024的特征图Concatenate,得到13x13x3072的特征图。
这里有个细节,“重组”是如何做的?我这里简单的用下图描述一下:
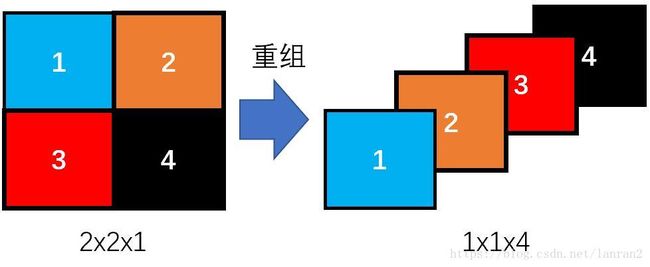
上图简单的描述了重组的过程,一个2x2x1的特征图变成了1x1x4的特征图,这个过程不涉及任何参数变量,所以重组后的特征图很好的保存了原特征图的信息。
对于Tensorflow有对应的API实现:tf.space_to_depth(x, blocksize=2),我们只要把特征图丢进这个API就能得到重组后的特征图了。
改进版:改进版在原版的基础上增加了一次卷积操作,先将26x26x512的特征图变为26x26x64的特征图,然后再执行后续的操作。原版和改进版的对比图如下:
3. YOLO V2的损失函数
最后聊聊YOLO V2的损失函数,YOLO V2的整篇文章并没有给出损失函数的公式。YOLO V2的损失函数依然以“回归”为主,里面没有Cross Entropy Loss,全部都是L2-Loss,整体的感觉和YOLO V1很像,我这里自行把Loss分解成三个部分:
Loss = confidence_loss + classification_loss + coordinates_loss
其中confidence_loss = no_obj_loss + obj_loss
下面我们一一分解:
首先我们先来看看confidence_loss,它代表是不是物体的概率,那么如何判断“是不是”物体呢?跟YOLO V1相似,首先判断哪个Grid Cell负责哪个物体,比如A Grid Cell负责B物体,然后每个Grid Cell中有5个预测框(根据网络的更新,候选框的位置会实时改变),然后计算预测框(5个框)与B的IOU(5个IOU),最大的IOU的Anchor框Label=1(或者=计算出的IOU),其余的IOU如果小于阈值(实际我们用的是0.6),则该Anchor的Label=0;
具体的公式如下:

其中W,H是特征图的大小,比如13,A是Anchor框的数量,比如5,然后bijk是预测的confidence,根据策略bijk会被当做背景与0做回归或者当作正例与IOU做回归。
然后分析classification_loss,这个Loss需要建立在bijk被当作正例的基础上,具体的公式如下:

其中我们需要注意,c是从1开始的,因为没有背景类,比如Pascal VOC有20类,那么C=20.
最后分析coordinates_loss,这个Loss也是建立在bijk被当作正例的基础上的,具体的公式如下:
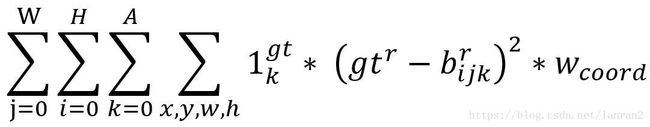
这里需要注意,YOLO V1对W和H进行了开根号的操作,YOLO V2并没有这个操作。
4. 小结
欣赏完YOLO V2,有4点值得我们学习,1)使用K-means产生候选框的策略;2)直接预测X,Y坐标的策略;3)使用IOU的分数作为回归Label值的策略;4)细粒度特征的方式。
最后请大家多多关注我的公共号:懒人学AI
