论文阅读(3)--SPDA-CNN: Unifying Semantic Part Detection and Abstraction for Fine-grained Recognition
这篇文章是来自罗格斯大学的Han Zhang等人的工作。由题目可知与上一篇文章一样,本文的作者也关注到了富有语义的局部(利用Part,Part,Part,重要事情强调三遍),作者不满足于CUB-2011数据库提供的head和body的定位结果,提出了small semantic parts 生成的方法。
论文中使用的网络分为两个子网络,一个用于检测,一个用于分类。检测子网络采用一个新的自顶向下的方法生成用于检测的细小的语义局部候选(small semantic part candidates),而分类子网络采用一个新的part layers,该层主要是从由检测子网络检测得到的局部提取特征,然后用于分类。最后将两个子网络都整合到成一个端到端的网络,可以提供检测,定位多个语句局部以及对整个物体的识别功能。整个网络系统如下图所示
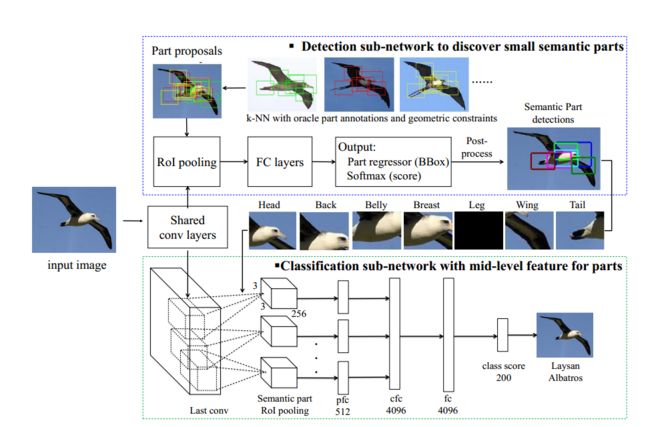
下面具体介绍这两个子网络的细节实现。
1. 检测子网络
1.1 Geometrically-constrained Top-down Region Proposals for Small Semantic Parts
首先是需要检测出细小的语义局部,论文是提出一种几何限制的自顶向下的区域建议方法。这种方法类似于K-最近邻方法。
这个方法首先是计算在一个矩形框内的物体的HOG特征,并用HOG来表示该物体的大致全局形状,然后基于这个特征,对于给定的图片,从训练集中跳出K个最近的邻居(也就是K张图片),对这些图片的特定的局部区域会根据给定的测试图片来调整尺寸大小。这里论文还提出可以根据两种形式的先验信息来得到最终的part region proposals,第一种比较强的是考虑到部件(part)的类标签以及其几何形状限制,这样最后得到的部件总数是N=km,而每个部件的proposals则是k个,k就是KNN方法找出来的K张图片数量,而m则是表示每张图片的部件(part)数量;第二种则是相对弱的信息,不考虑类标签,这种情况下,单个部件的proposals数量就等于部件的总数,也就是N=km。
最终得到的数量会比传统的生成region proposals的要少一个数量级。
1.2 Fast RCNN based Part Detection
得到上一步的part region proposals后,就使用[1]的方法来回归每一个part region proposal,并且分配一个部件的标签。对于每个物体,有m个部件,则将会有(m+1)个输出,包括m个部件的标签以及表示背景标签的0值。每一个输出都包括一个回归的bounding box–b,一个自信度得分 s∈[0,1] 。并且如[1]所介绍的,会训练部件分类器和part regressor。这里需要好好看看[1]这篇论文才能更好了解。
对所有的part region proposals的分类都是并行的,并且对于分类结果的判定,作者认为每个部件在一个测试图片中应该最多只有一次检测,应该每个部件应该选择拥有最高自信度得分的bounding box,同时会剔除得分低于阈值的,也就是对应的部件是实际不存在的,论文中对鸟类的检测中,腿部这个部件就是这种情况。
2. 分类子网络
分类子网络对传统的CNN网络结构中增加了3个新的网络层,分别是semantic part RoI pooling layer、part-based fully connected layer(pfc)、concatenation fully connected layer(cfc)。
semantic part RoI pooling layer:这一层的作用是从检测子网络中检测得到的语义部件提取特征,并根据一个预定义好的顺序重新组织这些特征。
part-based fully connected layer(pfc):这一层主要是将属于同一部件的连接在一起,以便获得mid-level part-specific features,也就是中层的特定部件特征。
concatenation fully connected layer(cfc):这一层则是将pfc层的结果连接在一起,也就是连接所有的部件,从而得到一个完整的网络,可以同时训练所有的部件。
2.1 Semantic Part RoI Pooling Layer
传统的pooling层主要是用于增加平移不变性以及减少网络的空间大小,即可以降低内存的使用。但是不是所有特征图中的特征都有用于分类的。
论文提出的新的pooling层是可以将pooling运算只使用在物体的有语义的部件上的。
首先,每个部件区域会分成 H×W (论文中给出的也就是3*3,文章开头给出的图中有标明大小)大小的子窗口,然后在这些子窗口上执行max-pooling运算,对于没有出现在语义部件的特征则抛弃。
然后,不同部件的经过pooling操作的特征会根据一个预定好的顺序排列(论文中给出鸟类部件的顺序)。
2.2 Part-based Fully Connected Layer
这一个新的全连接层中每个节点只会连接同一种部件中的特征,目的是得到一个中级的部件信息,可以连接低级的图像特征和高级的全局信息,同时也比传统的全连接层的参数更少。
2.3 Concatenation Fully Connected Layer
之前很多基于部件的CNN方法都是为每个部件训练单独的网络,然后再使用SVM来对联合起来的特征向量进行分类。而论文则提出这个新的全连接层来建立一个完整的网络来处理不同的部件。这样做的好处是可以将分类的误差传播回所有的部件,从而在训练的时候可以更新部件的权重。
3 Unifying Two Sub-networks
这里介绍如何将两个子网络联合在一起形成一个统一的网络。
作者是参考了[2]的做法——使用交替优化的方法,分为3个步骤。
第一步,分别使用ImageNet的预训练模型分别微调两个子网络,在这一步中,分类子网络中使用的是oracle的部件标注,而不是部件检测的结果,同时,这一步,两个子网络有着不同的卷积层。
第二步,使用分类子网络的前n个卷积层代替检测子网络中的对应卷积层,然后微调检测子网络中其他独立的网络层,这里n是一个超参数,需要根据最终统一网络的性能和效率来进行调试。
最后一步,则使用来自检测子网络的检测结果对分类子网络进行微调,除了共享的卷积层外,即第二步选择的前n个卷积层不用进行微调。因此,两个子网络将拥有相同的卷积层,并最终变成一个统一的网络。
4 小结
总的来说,文章作者基于鸟的形状特性,在Proposal生成阶段构造了几何限制条件,并基于此提出了一种Part Detection的方法。而Parts在鸟类Fine-Grained分类问题上对结果的提高有明显帮助。作者将Part Detection和Classification结合成一个End-to-End的结构,同时进行训练与测试,取得了优异的结果。
这篇论文也是将重点放到特定部件上,不过其用的数据库中是有提供bounding box的标注的,相比上一篇看的论文的自动检测部件方法,这里的检测网络和分类网络,如果对于没有任何bounding box的标注的数据库的话,可能就会需要人工标注了,工作量就相对比较大了。不过,这也说明了使用部件来进行精细图像分类是目前比较热门的一个方向,确实可以好好往这方面想想,还有什么可以改进的。
其他参考论文:
[1] Fast RCNN
[2] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks