windows下虚拟机配置spark集群最强攻略!
全文共4356个字,58张图,预计阅读时间20分钟。
 虚拟机安装
虚拟机安装
首先需要在windows上安装vmware和ubuntu虚拟机,这里就不多说了。
vmware下载地址:直接百度搜索,使用百度提供的链接下载,这里附上一个破解码
5A02H-AU243-TZJ49-GTC7K-3C61N
ubuntu下载地址:http://cdimage.ubuntu.com/daily-live/current/
一路安装下去,我一共装了4台虚拟机,三台用于构建集群,一台用于爬虫,如图所示:
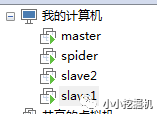
虚拟机网络配置
这里,我们以slave2为例来说明一下虚拟机的网络配置:
首先,将虚拟机的网络设置设置为自定义,选择VMnet8:
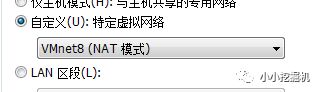
随后,我们点击VMWARE上的编辑-虚拟网络编辑-右下角的更改设置,应该有三个连接方式,这里我们把其他两个移除,只剩下VMnet8:

随后,点击NAT设置,我们可以发现网关是192.168.75.2
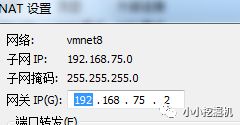
接下来,我们要设置虚拟机的ip:点击右上角的edit connectinos,设置Ipv4,如下图所示:

随后修改两个文件:
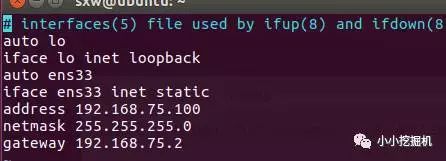
修改interfaces文件
命令:sudo vim /etc/network/interfaces ( 如果没有vim命令,使用sudo apt-get install vim进行安装):
修改resolv.conf文件
命令:sudo vim /etc/resolv.conf:
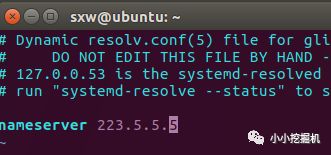
接下来重启我们的网络就可以啦:
命令:sudo /etc/init.d/networking restart(如果启动失败,重启虚拟机即可)
![]()
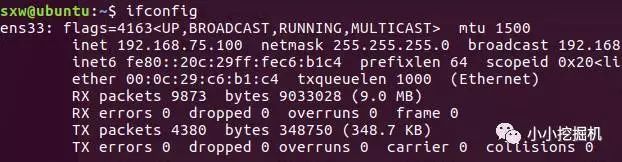
查看我们的ip,使用ifconfig命令,如果没有安装(使用sudo apt install net-tools 进行安装):
使用xshelll连接本地虚拟机(非必须)
下载xshell,百度搜索xshell,使用百度提供的下载地址即可。
要想使用xshell的ssh方式访问虚拟机,首先要在虚拟机上安装ssh服务
使用命令:sudo apt-get install openssh-server
随后启动ssh服务:sudo /etc/init.d ssh start
再次点击VMWARE上的编辑-虚拟网络编辑-右下角的更改设置,设置端口转发:
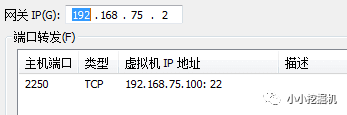
随后打开xshell,新建连接:
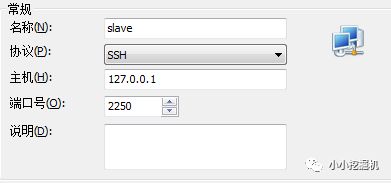
设置用户名和密码:
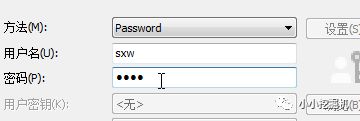
随后点击连接即可,发现连接成功!
![]()
修改虚拟机主机名以及hosts文件
这里以修改主节点主机名称为例,其他节点类似。
使用命令 : sudo vim /etc/hostname 查看当前主机名,并修改为master:
![]()
重启之后生效:

两个从节点的主机依次修改为slave1,slave2
接下来,将主节点和两个从节点的ip和主机名添加到hosts文件中,使用命令
sudo vim /etc/hosts
修改的结果为:
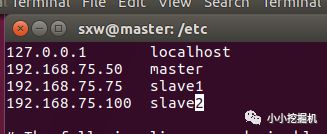
两个从节点的hosts文件修改为同样的结果,此时发现各虚拟机之间可以ping通。

配置SSH免验证登录
接下来,需要让主节点可以免验证的登录到从节点,从而在进行任务调度时可以畅通无阻。
首先要在各个节点上生成公钥和私钥文件,这里以slave1节点进行讲解,其他节点操作方式完全相同。
我们首先要开启ssh服务,使用命令:sudo /etc/init.d/ssh start
![]()
随后使用如下命令生成公钥和私钥文件:
ssh-keygen -t rsa -P ""
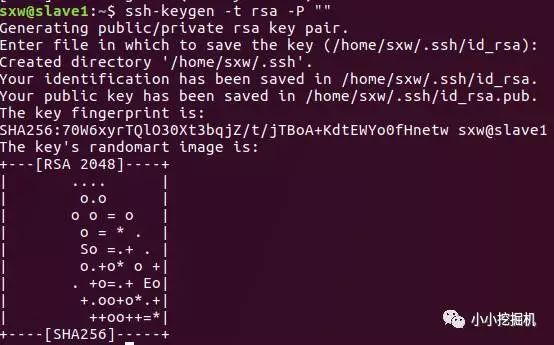
在所有节点上生成秘钥文件之后,我们需要将从节点的公钥传输给主节点,使用命令:
cd ~/.ssh
scp id_rsa.pub sxw@master:~/.ssh/id_rsa.pub.slave1
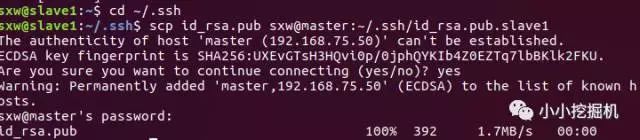
随后,在主节点下,将所有的公钥信息拷贝到authorized_keys文件下:
使用命令:
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
cat id_rsa.pub.slave1 >> authorized_keys
cat id_rsa.pub.slave2 >> authorized_keys
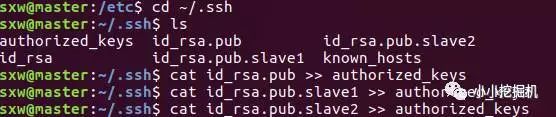
接下来将authorized_keys文件复制到slave1和slave2节点目录下:
scp authorized_keys sxw@slave1:~/.ssh/authorized_keys
scp authorized_keys sxw@slave2:~/.ssh/authorized_keys

接下来我们验证是否可以免密码登录:使用命令
ssh slave1
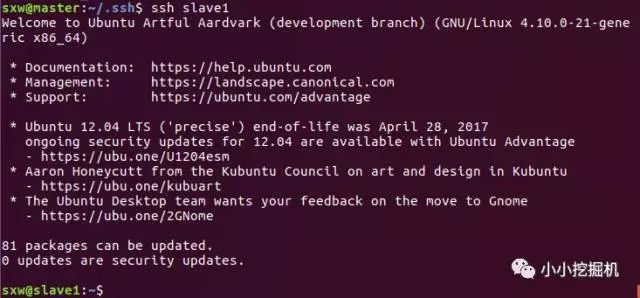
登陆成功,我们可以使用exit命令退出登录
安装Java环境
这里我们可以直接使用linux的命令下载jdk,当然也可以在本地下载之后传输到虚拟机中,这里我采用的是后者,因为我感觉在主机上下载会比较快一些。到java官网中下载最新的jdk文件即可。
使用由于刚才我们配置了端口转发,因此我们可以使用winscp进行文件传输:
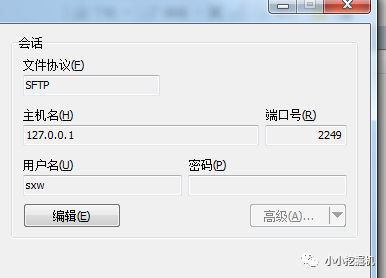
传输文件到/home/sxw/Documents路径下,直接将文件进行拖拽即可:
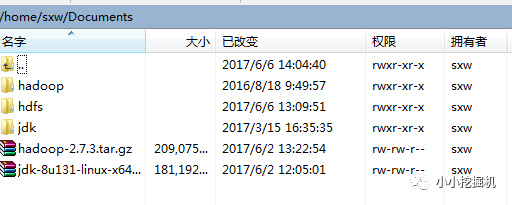
随后,在该路径下,使用如下命令进行解压:
tar -zxvf 文件名
![]()
重命名jdk文件夹为jdk
![]()
随后修改配置文件:
sudo vim /etc/profile
添加如下三行:
export JAVA_HOME=/home/sxw/Documents/jdk
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
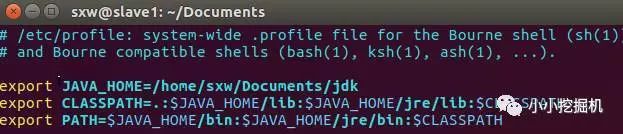
使用source命令使修改生效,同时查看是否安装成功

安装Scala环境
可以使用命令下载scala,不过我们仍然选择在本地下载scala:
下载地址:http://www.scala-lang.org/download/2.11.7.html
通过winscp传入各虚拟机里,并使用如下命令进行解压:
tar -zxvf 文件名
![]()
重命名文件:
![]()
修改配置文件,增加以下两行,并用source命令使修改生效:
![]()
检查是否安装成功:
![]()
可以看到scala已经安装成功了!
安装Hadoop配置环境
我们首先在主节点上配置好hadoop的文件,随后使用scp命令传输到从节点上即可。
同样,我们在hadoop官网下载hadoop文件,通过winscp传入主节点,使用tar命令进行解压,并修改文件夹名为hadoop,这些这里暂且略过。
修改环境变量(所有节点都需要修改)并使用source命令使其生效:

接下来修改hadoop的配置文件:
(1)$HADOOP_HOME/etc/hadoop/hadoop-env.sh
修改JAVA_HOME 如下:
export JAVA_HOME=/home/sxw/Documents/jdk
(2)$HADOOP_HOME/etc/hadoop/slaves
修改salves里添加两个从节点的名称
slave1
slave2
(3)$HADOOP_HOME/etc/hadoop/core-site.xml
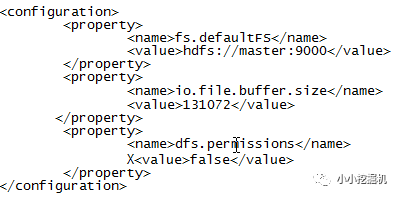
(4)$HADOOP_HOME/etc/hadoop/hdfs-site.xml
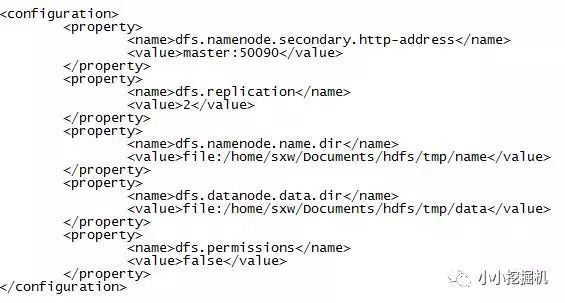
(5)$HADOOP_HOME/etc/hadoop/mapred-site.xml
首先使用如下命令生成mapred-site.xml文件:
cp mapred-site.xml.template mapred-site.xml
随后进行修改:
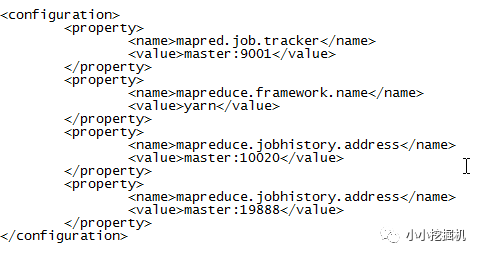
(6)$HADOOP_HOME/etc/hadoop/yarn-site.xml
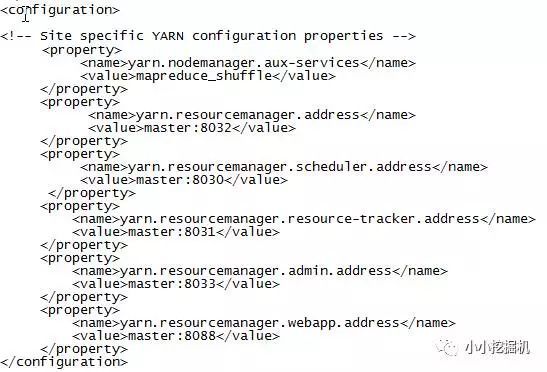
至此,hadoop的配置文件就修改完了,我们用scp命令将修改好的hadoop文件传入到子节点即可
安装spark环境
我们首先在主节点上配置好spark的文件,随后使用scp命令传输到从节点上即可。
同样在spark官网下载最新的spark文件,并使用winscp传入虚拟机,使用tar命令进行解压,并重命名文件夹为spark。
添加spark到环境变量并使其生效:
![]()
接下来修改spark的配置文件:
(1)$SPARK_HOME/conf/spark-env.sh
首先使用如下命令生成spark-env.sh文件:
cpspark-env.sh.template spark-env.sh
随后进行修改:

(2)$SPARK_HOME/conf/slaves
首先使用如下命令生成slaves文件:
cpslaves.template slaves
随后进行修改:
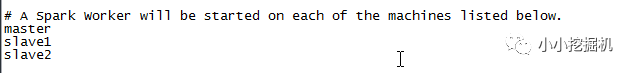
至此,spark的配置文件就修改完了,我们用scp命令将修改好的spark文件传入到子节点即可,不要忘记修改子节点的环境变量
集群启动和关闭
首先我们编写一个启动脚本:
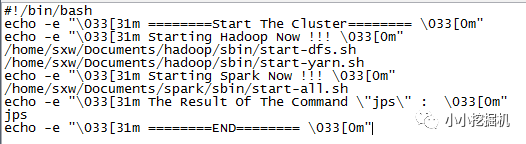
可以看到,hadoop的启动需要两个命令,分别启动dfs和yarn,传统的start-all.sh已经被弃用。而spark的启动只需要一个命令。
启动的结果如下图所示:
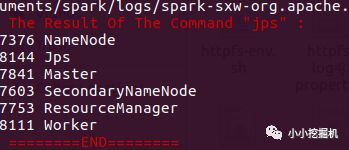
随后我们再编写一个关闭集群的脚本:
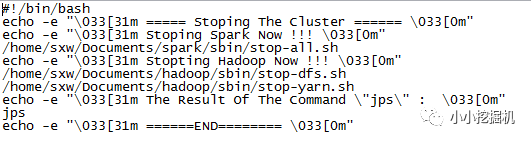
Hadoop测试
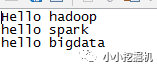
我们在/home/sxw/Documents下建立一个wordcount.txt文件
文件内容如下图:
到hadoop的bin路径下执行如下三条命令:
hadoop fs -mkdir-p /Hadoop/Input
hadoop fs-put wordcount.txt /Hadoop/Input
hadoop jar /home/sxw/Documents/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /Hadoop/Input /Hadoop/Output
可以看到我们的hadoop再进行运算了:

使用如下命令查看运算结果,发现我们的期望的结果正确输出:
hadoop fs -cat/Hadoop/Output/*

hadoop配置成功!
spark测试
我们直接利用spark-shell 进行测试,编写几条简单额scala语句:
到spark的bin路径下执行./spark-shell命令进入scala的交互模式,并输入如下几条scala语句:
valfile=sc.textFile("hdfs://master:9000/Hadoop/Input/wordcount.txt")
val rdd=file.flatMap(line => line.split("")).map(word => (word,1)).reduceByKey(_+_)
rdd.collect()
rdd.foreach(println)
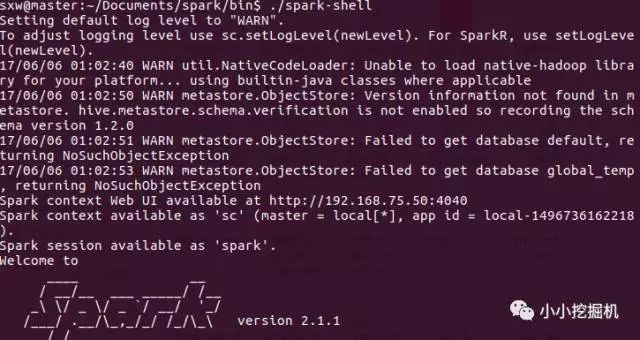

可以看到,我们的spark集群成功搭建!
原文链接:https://mp.weixin.qq.com/s?__biz=MzI1MzY0MzE4Mg==&mid=2247483714&idx=1&sn=03e2d332cd40aa266c1c50bc78e0c46a&chksm=e9d01183dea79895cfbabb281156f5f9e4acb7351632cc61dcbf0539b59d37a7afbee5f58827&scene=21#wechat_redirect
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看
LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python基础