常用概率分布函数及随机特征
常见分布的随机特征

离散随机变量分布
-
伯努利分布(二点分布)
伯努利分布亦称“零一分布”、“两点分布”。称随机变量X有伯努利分布, 参数为p(0
一个非常简单的试验是只有两个可能结果的试验,比如正面或反面,成功或失败,有缺陷或没有缺陷,病人康复或未康复。为方便起见,记这两个可能的结果为0和1,下面的定义就是建立在这类试验基础之上的。
如果 随机变量X只取0和1两个值,并且相应的概率为:
X 服从 (0-1)分布或两点分布.记为X~b(1,p)
则称随机变量X服从参数为p的伯努利分布,若令q=1一p,则X的概率函数可写
为:
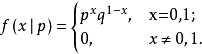
要证明该概率函数
 确实是公式所定义的伯努利分布,只要注意到
确实是公式所定义的伯努利分布,只要注意到
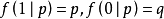 ,就很容易得证。
,就很容易得证。
如果X服从参数为p的伯努利分布,则:
进而,X的矩母函数为:
二项分布
二项分布就是重复n次独立的伯努利试验。在每次试验中只有两种可能的结果,而且两种结果发生与否互相对立,并且相互独立,与其它各次试验结果无关,事件发生与否的概率在每一次独立试验中都保持不变,则这一系列试验总称为n重伯努利实验,当试验次数为1时,二项分布服从0-1分布。
二项分布(Binomial Distribution),即重复n次的 伯努利试验(Bernoulli Experiment),用ξ表示 随机试验的结果。如果事件发生的 概率是P,则不发生的概率q=1-p,N次 独立重复试验中发生K次的概率是

那么就说这个属于二项分布。其中P称为成功概率。记作ξ~B(n,p)
数学期望和差:
数学期望:Eξ=np;
方差:Dξ=npq;
其中q=1-p
证明:
由二项式分布的定义知,随机变量X是n重伯努利实验中事件A发生的次数,且在每次试验中A发生的概率为p。因此,可以将二项式分布分解成n个相互独立且以p为参数的(0-1)分布随机变量之和.
设 随机变量X(k)(k=1,2,3...n)服从(0-1)分布,则X=X(1)+X(2)+X(3)....X(n).
因X(k)相互独立,所以期望:

方差:

1.在每次试验中只有两种可能的结果,而且是互相对立的;
2.每次实验是独立的,与其它各次试验结果无关;
3.结果事件发生的概率在整个系列试验中保持不变,则这一系列试验称为伯努利实验。
在这试验中,事件发生的次数为一随机事件,它服从二次分布。二项分布可
以用于可靠性试验。可靠性试验常常是投入n个相同的式样进行试验T小时,而只允许k个式样失败,应用二项分布可以得到通过试验的概率。
以用于可靠性试验。可靠性试验常常是投入n个相同的式样进行试验T小时,而只允许k个式样失败,应用二项分布可以得到通过试验的概率。
若某事件概率为p,现重复试验n次,该事件发生k次的概率为:P=C(n,k)×p^k×(1-p)^(n-k)。C(n,k)表示组合数,即从n个事物中拿出k个的方法数
。
性质
(一)二项分布是 离散
型分布,概率 直方图
是跃阶式的。因为x为不连续变量,用概率条图表示更合适,用 直方图
表示只是为了更形象些。
1.当p=q时图形是对称的
例如,
 ,p=q=1/2,各项的概率可写作:
,p=q=1/2,各项的概率可写作:
2.当p≠q时,直方图呈 偏态,pq的偏斜方向相反。如果n很大,即使p≠q,偏态逐渐降低,最终成正态分布,二项分布的极限分布为 正态分布。故当n很大时,二项分布的概率可用正态分布的概率作为近似值。何谓n很大呢?一般规定:当pq且nq≥5,这时的n就被认为很大,可以用正态分布的概率作为近似值了。
(二)二项分布的 平均数与 标准差
如果二项分布满足pq,np≥5)时,二项分布接近正态分布。这时,也仅仅在这时,二项分布的x变量(即成功的次数)具有如下性质:
即x变量具有μ =
n
p,的正态分布。
-
泊松分布
Poisson分布(法语:loi de Poisson,英语:Poisson distribution,译名有泊松分布、普阿松分布、卜瓦松分布、布瓦松分布、布阿松分布、波以松分布、卜氏分配等),是一种统计与概率学里常见到的离散 概率分布,由法国数学家西莫恩·德尼·泊松(Siméon-Denis Poisson)在1838年时发表。
泊松分布的概率函数为:
泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生率。 泊松分布适合于描述单位时间内随机事件发生的次数。
泊松分布数学期望和方差:
泊松分布的
数学期望和
方差均为
 特征函数为
特征函数为
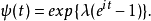
柏松分布应用示例
泊松分布适合于描述单位时间(或空间)内随机事件发生的次数。如某一服务设施在一定时间内到达的人数,电话交换机接到呼叫的次数,汽车站台的候客人数,机器出现的故障数,自然灾害发生的次数,一块产品上的缺陷数,显微镜下单位分区内的细菌分布数等等。
观察事物平均发生m次的条件下,实际发生x次的概率P(x)可用下式表示:
例如采用0.05J/㎡紫外线照射大肠杆菌时,每个基因组(~4×10
6 核苷酸对)平均产生3个嘧啶二体。实际上每个基因组二体的分布是服从泊松分布的,将取如下形式:
……
-
几何分布
几何分布(Geometric distribution)是离散型概率分布。其中一种定义为:在n次 伯努利试验中,试验k次才得到第一次成功的机率。详细地说,是:前k-1次皆失败,第k次成功的概率。几何分布是 帕斯卡分布当r=1时的特例。

定义
在伯努利试验中,记每次试验中事件A发生的概率为p,试验进行到事件A出现时停止,此时所进行的试验次数为X,其分布列为:
此分布列是几何数列的一般项,因此称X服从几何分布,记为X ~ GE(p) 。
实际中有不少随机变量服从几何分布,譬如,某产品的不合格率为0.05,则首次查到不合格品的检查次数X ~ GE(0.05) 。
几何分布的分类和特征
它分两种情况:
(1)为得到1次成功而进行n次伯努利试验,n的概率分布,取值范围为1,2,3,...;
这种情况的期望和方差如下:
(2)m = n-1次失败,第n次成功,m的概率分布,取值范围为0,1,2,3,...。
这种情况的期望和方差如下:
比如,假设不停地掷 骰子,直到得到
1。投掷次数是随机分布的,取值范围是无穷集合{ 1, 2, 3, ... },并且是一个
p= 1/6的几何分布。
参数p的几何分布
概率为p的事件A,以X记A首次发生所进行的试验次数,则X的分布列:
具有这种分布列的 随机变量X,称为服从参数p的几何分布,记为
X~
Geo(
p)。
几何分布的期望
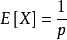 ,方差
,方差
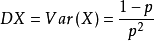 。
。
几何分布的推广
推广1
现进行如下试验,在伯努利试验中,记每次试验中事件A发生的概率为p,试验进行到事件A和
 都出现后停止,此时所进行的试验次数为X,则有:
都出现后停止,此时所进行的试验次数为X,则有:
因此,上式可以成为一个分布列,此分布列是两个几何数列一般项的和,在这里称X服从两事件下推广的几何分布,记为X ~ PGE(2;p) ,数学期望为:
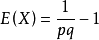 。当P =
。当P =
 时,E(X) 取最小值,此时E(X)= 3.
时,E(X) 取最小值,此时E(X)= 3.
由于
 ,因此可以得到:
,因此可以得到:
推广2
现进行独立重复试验,每次试验会有三个事件A、B、C中的其中一个发生,记每次试验中事件A、B、C发生的概率分别为
 ,
,
 且
且
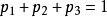 。试验进行到事件A、B、C都发生后停止,此时所进行的试验次数为X,则有:
。试验进行到事件A、B、C都发生后停止,此时所进行的试验次数为X,则有:
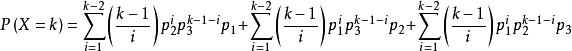
其中,k=3,4,...。因此上式也可以作为一个分布列,此分布列是六个几何数列一般项的和与差,称X服从三事件下推广的几何分布,记为X ~ PGE(3;
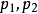 )。数学期望为:
)。数学期望为:

-
-
均匀分布
在 概率论和统计学中,均匀分布也叫矩形分布,它是对称概率分布,在相同长度间隔的分布概率是等可能的。 均匀分布由两个参数a和b定义,它们是数轴上的最小值和最大值,通常缩写为U(a,b)。

均匀分布概率密度函数
均匀分布的概率密度函数为:
在两个边界a和b处的f(x)的值通常是不重要的,因为它们不改变任何
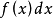 的积分值。 概率密度函数有时为0,有时为
的积分值。 概率密度函数有时为0,有时为
 。 在傅里叶分析的概念中,可以将f(a)或f(b)的值取为
。 在傅里叶分析的概念中,可以将f(a)或f(b)的值取为
 ,因为这种均匀函数的许多积分变换的逆变换都是函数本身。
,因为这种均匀函数的许多积分变换的逆变换都是函数本身。
对于平均值μ和方差
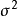 ,概率密度可以写为:
,概率密度可以写为:
均匀分布分布函数
它的逆是:
生成函数
力矩生成函数:
我们可以从中计算原始力矩
 :
:

对于特殊情况a =-b,那么,
力矩生成函数的简单形式:
对于该分布的随机变量,期望值为
 ,方差为
,方差为
 。
。
矩
一阶矩(均值/数学期望):
二阶中心矩(方差):
也可以用期望来求:
统计量
令
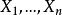 是服从于U(0,1)的样本。 令X(k)为该样本的第k次统计量。 那么X(k)的概率分布是参数为k和n-k+1的β分布。期望值是:
是服从于U(0,1)的样本。 令X(k)为该样本的第k次统计量。 那么X(k)的概率分布是参数为k和n-k+1的β分布。期望值是:
方差是:
均匀度
均匀分布的随机变量落在固定长度的任何间隔内的概率与区间本身的位置无关(但取决于间隔大小),只要间隔包含在分布的支持中即可。
为了看到这一点,如果X〜U(a,b)并且[x,x + d]是具有固定d> 0的[a,b]的子间隔,则
标准均匀分布
编辑
若a = 0并且b = 1,所得分布U(0,1)称为标准均匀分布。
标准均匀分布的一个有趣的属性是,如果u
1具有标准均匀分布,那么1-u
1也是如此。
[5]
相关分布
编辑
(1)如果X服从标准均匀分布,则通过逆变换方法,
 具有指数分布参数
具有指数分布参数
 。
。
(2)如果X服从标准均匀分布,则Y = X
n具有参数(1 / n,1)的β分布。
(3)如果X服从标准均匀分布,则Y = X也是具有参数(1,1)的β分布的特殊情况。
(4)两个独立的,均匀分布的总和产生对称的三角分布。
[4]
应用
编辑
统计学中,当使用p值作为简单零假设的检验统计量,并且检验统计量的分布是连续的,则如果零假设为真,则p值均匀分布在0和1之间。
从均匀分布抽样
运行仿真实验有很多应用。 许多编程语言能够生成根据标准均匀分布有效分布的伪随机数。
如果u是从标准均匀分布中采样的值,则如上所述,
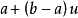 的值遵循由a和b参数化的均匀分布。
的值遵循由a和b参数化的均匀分布。
从任意分布抽样
均匀分布对于任意分布的采样是有用的。 一般的方法是使用目标随机变量的累积分布函数(CDF)的逆变换采样方法。 这种方法在理论工作中非常有用。 由于使用这种方法的模拟需要反转目标变量的CDF,所以已经设计了cdf未以封闭形式知道的情况的替代方法。 一种这样的方法是拒收抽样。
正态分布是逆变换方法效率不高的重要例子。 然而,有一个确切的方法,Box-Muller变换,它使用逆变换将两个独立的均匀随机变量转换成两个独立的正态分布随机变量。
量化误差
在模数转换中,发生量化误差。 该错误是由于四舍五入或截断。 当原始信号比一个最低有效位(LSB)大得多时,量化误差与信号不显着相关,并具有大致均匀的分布。 因此,RMS误差遵循该分布的方差。
-
指数分布
在概率理论和统计学中,指数分布(也称为负指数分布)是描述泊松过程中的事件之间的时间的概率分布,即事件以恒定平均速率连续且独立地发生的过程。 这是 伽马分布的一个特殊情况。 它是几何分布的连续模拟,它具有无记忆的关键性质。 除了用于分析泊松过程外,还可以在其他各种环境中找到。
指数分布与分布指数族的分类不同,后者是包含指数分布作为其成员之一的大类概率分布,也包括正态分布,二项分布,伽马分布,泊松分布等等。
指数函数的一个重要特征是无记忆性(Memoryless Property,又称遗失记忆性)。这表示如果一个随机变量呈指数 分布,当s,t>0时有P(T>t+s|T>t)=P(T>s)。即,如果T是某一元件的寿命,已知元件使用了t小时,它总共使用至少s+t小时的条件概率,与从开始使用时算起它使用至少s小时的概率相等。
指数分布概率密度函数

其中λ > 0是分布的一个参数,常被称为率参数(rate parameter)。即每单位时间内发生某事件的次数。指数分布的区间是[0,∞)。 如果一个随机变量X呈指数分布,则可以写作:X~ E(λ)。
在不同的教材有不同的写法,θ=1/λ,因此概率密度函数,分布函数和期望方差有两种写法。
其中θ>0为常数,则称X服从参数θ的指数分布。
指数分布函数
指数分布的分布函数由下式给出:
有:
比方说:如果你平均每个小时接到2次电话,那么你预期等待每一次电话的时间是半个小时。
指数分布方差
若随机变量x服从参数为λ的指数分布,则记为
 。
。
指数分布特性
无记忆性
指数函数的一个重要特征是无记忆性(
Memoryless Property,又称遗失记忆性)。这表示如果一个随机变量呈指数分布
当
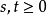 时有
时有
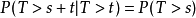
即,如果T是某一元件的寿命,已知元件使用了t小时,它总共使用至少
 小时的条件概率,与从开始使用时算起它使用至少s小时的概率相等。
小时的条件概率,与从开始使用时算起它使用至少s小时的概率相等。
分位数
参数λ的四分位数函数(Quartile function)是:
中位数:

第三四分位数:

分布
在 概率论和统计学中,指数分布(Exponential distribution)是一种 连续概率分布。指数分布可以用来表示独立 随机事件发生的时间间隔,比如旅客进机场的时间间隔、 中文维基百科新条目出现的时间间隔等等。
许多电子产品的寿命分布一般服从指数分布。有的系统的寿命分布也可用指数分布来近似。它在可靠性研究中是最常用的一种分布形式。指数分布是 伽玛分布和 威布尔分布的特殊情况,产品的失效是偶然失效时,其寿命服从指数分布。
指数分布可以看作当威布尔分布中的形状系数等于1的特殊分布,指数分布的失效率是与时间t无关的常数,所以分布函数简单。
应用
在电子元器件的可靠性研究中,通常用于描述对发生的缺陷数或系统故障数的测量结果。这种分布表现为 均值越小,分布偏斜的越厉害。
指数分布应用广泛,在日本的工业标准和美国军用标准中,半导体器件的抽验方案都是采用指数分布。此外,指数分布还用来描述大型 复杂系统(如计算机)的 平均故障间隔时间MTBF的失效分布。但是,由于指数分布具有缺乏“记忆”的特性.因而限制了它在机械可靠性研究中的应用,所谓缺乏“记忆”,是指某种产品或零件经过一段时间t0的工作后,仍然如同新的产品一样,不影响以后的工作寿命值,或者说,经过一段时间t0的工作之后,该产品的寿命分布与原来还未工作时的寿命分布相同,显然,指数分布的这种特性,与机械零件的疲劳、磨损、腐蚀、蠕变等损伤过程的实际情况是完全矛盾的,它违背了产品损伤累积和老化这一过程。所以,指数分布不能作为机械零件功能参数的分布形式。
指数分布虽然不能作为机械零件功能参数的分布规律,但是,它可以近似地作为高可靠性的复杂部件、机器或系统的失效分布模型,特别是在部件或机器的整机试验中得到广泛的应用。
指数分布的图形表面上看与幂律分布很相似,实际两者有极大不同,指数分布的收敛速度远快过幂律分布。
指数分布的参数为λ,则指数分布的期望为
 ,方差为
,方差为
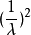 。
。
-
正态分布
正态分布(Normal distribution),也称“常态分布”,又名 高斯分布(Gaussian distribution),最早由A.棣莫弗在求 二项分布的渐近公式中得到。C.F.高斯在研究测量误差时从另一个角度导出了它。P.S.拉普拉斯和高斯研究了它的性质。是一个在 数学、物理及工程等领域都非常重要的 概率分布,在统计学的许多方面有着重大的影响力。
正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人们又经常称之为 钟形曲线。
若 随机变量X服从一个 数学期望为μ、 方差为σ^2的正态分布,记为N(μ,σ^2)。其 概率密度函数为正态分布的 期望值μ决定了其位置,其 标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是 标准正态分布。

正态分布概念是由德国的数学家和天文学家Moivre于1733年首次提出的,但由于德国数学家Gauss率先将其应用于天文学家研究,故正态分布又叫高斯分布,高斯这项工作对后世的影响极大,他使正态分布同时有了“高斯分布”的名称,后世之所以多将最小二乘法的发明权归之于他,也是出于这一工作。但现今德国10马克的印有高斯头像的钞票,其上还印有正态分布的 密度曲线。这传达了一种想法:在高斯的一切科学贡献中,其对 人类文明影响最大者,就是这一项。在高斯刚作出这个发现之初,也许人们还只能从其理论的简化上来评价其优越性,其全部影响还不能充分看出来。这要到20世纪正态小样本理论充分发展起来以后。 拉普拉斯很快得知高斯的工作,并马上将其与他发现的中心极限定理联系起来,为此,他在即将发表的一篇文章(发表于1810年)上加上了一点补充,指出如若误差可看成许多量的叠加,根据他的中心极限定理,误差理应有 高斯分布。这是历史上第一次提到所谓“元误差学说”——误差是由大量的、由种种原因产生的元误差叠加而成。后来到1837年,海根(G.Hagen)在一篇论文中正式提出了这个学说。
其实,他提出的形式有相当大的局限性:海根把误差设想成个数很多的、独立同分布的“元误差” 之和,每只取两值,其概率都是1/2,由此出发,按狄莫佛的中心极限定理,立即就得出误差(近似地)服从正态分布。拉普拉斯所指出的这一点有重大的意义,在于他给误差的正态理论一个更自然合理、更令人信服的解释。因为,高斯的说法有一点循环论证的气味:由于算术平均是优良的,推出误差必须服从正态分布;反过来,由后一结论又推出算术平均及最小二乘估计的优良性,故必须 认定这二者之一(算术平均的优良性,误差的正态性) 为出发点。但算术平均到底并没有自行成立的理由,以它作为理论中一个预设的出发点,终觉有其不足之处。拉普拉斯的理论把这断裂的一环连接起来,使之成为一个和谐的整体,实有着极重大的意义。
定理
由于一般的正态总体其图像不一定关于y 轴对称,对于任一正态总体,其取值小于x的概率。只要会用它求正态总体在某个特定区间的概率即可。
为了便于描述和应用,常将正态变量作数据转换。将一般正态分布转化成标准正态分布。
若

服从标准正态分布,通过查标准正态分布表就可以直接计算出原正态分布的概率值。故该变换被称为标准化变换。(标准正态分布表:标准正态分布表中列出了标准正态曲线下从-∞到X(当前值)范围内的面积比例。)
定义
一维正态分布
若 随机变量
 服从一个位置参数为
服从一个位置参数为
 、尺度参数为
、尺度参数为
 的概率分布,且其 概率密度函数为
的概率分布,且其 概率密度函数为
则这个 随机变量就称为
正态随机变量,正态随机变量服从的分布就称为
正态分布,记作
 ,读作
,读作
 服从
服从
 ,或
,或
 服从正态分布。
服从正态分布。
μ维随机 向量具有类似的概率规律时,称此随机向量遵从多维正态分布。多元正态分布有很好的性质,例如,多元正态分布的边缘分布仍为正态分布,它经任何 线性变换得到的随机向量仍为多维正态分布,特别它的线性组合为一元正态分布。
本词条的正态分布是一维正态分布,此外多维正态分布参见“ 二维正态分布”。
标准正态分布
当
 时,正态分布就成为
标准正态分布
时,正态分布就成为
标准正态分布

性质
正态分布的一些性质:
(1)如果
 且a与b是 实数,那么
且a与b是 实数,那么
 (参见 期望值和 方差)。
(参见 期望值和 方差)。
(2)如果
 与
与
 是
统计独立的正态 随机变量,那么:
是
统计独立的正态 随机变量,那么:
它们的和也满足正态分布

它们的差也满足正态分布

U与V两者是相互独立的。(要求X与Y的方差相等)
(3)如果
 和
和
 是独立常态随机变量,那么:
是独立常态随机变量,那么:
它们的积XY服从概率密度函数为p的分布
它们的比符合 柯西分布,满足

(4)如果
 为独立标准常态随机变量,那么
为独立标准常态随机变量,那么
 服从自由度为
n的 卡方分布。
服从自由度为
n的 卡方分布。
分布曲线
图形特征
集中性:正态曲线的高峰位于正中央,即 均数所在的位置。
对称性:正态曲线以均数为中心,左右对称,曲线两端永远不与 横轴相交。
均匀变动性:正态曲线由均数所在处开始,分别向左右两侧逐渐均匀下降。
曲线与横轴间的面积总等于1,相当于 概率密度函数的函数从正无穷到负无穷积分的概率为1。即频率的总和为100%。
 正态分布
正态分布
正态分布
关于μ对称,并在μ处取最大值,在正(负)无穷远处取值为0,在μ±σ处有 拐点,形状呈现中间高两边低,正态分布的概率密度函数 曲线呈钟形,因此人们又经常称之为
钟形曲线。
参数含义
正态分布有两个参数,即期望(均数)μ和标准差σ,σ
2为方差。
 正态分布公式
正态分布公式
正态分布公式
正态分布具有两个参数μ和σ^2的 连续型随机变量的分布,第一参数μ是服从正态分布的随机变量的 均值,第二个参数σ^2是此随机变量的 方差,所以正态分布记作N(μ,σ
2)。
μ是正态分布的位置参数,描述正态分布的 集中趋势位置。概率规律为取与μ邻近的值的概率大,而取离μ越远的值的概率越小。正态分布以X=μ为 对称轴,左右完全对称。正态分布的期望、 均数、 中位数、众数相同,均等于μ。
σ描述正态分布资料数据分布的离散程度,σ越大,数据分布越分散,σ越小,数据分布越集中。也称为是正态分布的形状参数,σ越大,曲线越扁平,反之,σ越小,曲线越瘦高。
面积分布
1.实际工作中,正态曲线下横轴上一定区间的面积反映该区间的例数占总例数的百分比,或变量值落在该区间的概率(概率分布)。不同 范围内正态曲线下的面积可用公式计算。
⒉正态曲线下, 横轴区间(μ-σ,μ+σ)内的面积为68.268949%。
P{|X-μ|<σ}=2Φ(1)-1=0.6826
横轴区间(μ-1.96σ,μ+1.96σ)内的面积为95.449974%。
P{|X-μ|<2σ}=2Φ(2)-1=0.9544
横轴区间(μ-2.58σ,μ+2.58σ)内的面积为99.730020%。
P{|X-μ|<3σ}=2Φ(3)-1=0.9974
由于
“小概率事件”和 假设检验的基本思想 “小概率事件”通常指发生的概率小于5%的事件,认为在一次试验中该事件是几乎不可能发生的。由此可见X落在(μ-3σ,μ+3σ)以外的概率小于千分之三,在实际问题中常认为相应的事件是不会发生的,基本上可以把区间(μ-3σ,μ+3σ)看作是随机变量X实际可能的取值区间,这称之为正态分布的“3σ”原则。