torchtext学习总结
torchtext学习总结
- TorchText
- API一览
- 概述
- Field对象
- Dataset
- 迭代器(iterator)
- 具体使用
- 使用Dataset类
- 自定义Dataset类
- 构建数据集
- 构建词表
- 最简单的方法:build_vocab()方法中传入用于构建词表的数据集
- 使用预训练词向量
- 构建迭代器
- 批数据的使用
- 在模型中指定Embedding层的权重
- 使用torchtext构建的数据集用于LSTM
- 一个使用torchtext内置数据集的例子
- 读取json文件并生成batch
- 设置Field
- 使用torchtext.data.Tabulardataset.splits读取文件
- 构建vocab表
- 使用torchtext.data.Iterator.splits生成batch
- 做推理的例子
- 参考链接
更新 2019/4/9
分享一个不错的torchtext入门github,地址在这
TorchText
API一览
torchtext.data
- torchtext.data.Example : 用来表示一个样本,数据+标签
- torchtext.vocab.Vocab: 词汇表相关
- torchtext.data.Datasets: 数据集类,getitem 返回 Example实例
- torchtext.data.Field : 用来定义字段的处理方法(文本字段,标签字段)
- 创建 Example时的预处理
- batch 时的一些处理操作。
- torchtext.data.Iterator: 迭代器,用来生成 batch
torchtext.datasets: 包含了常见的数据集.
概述
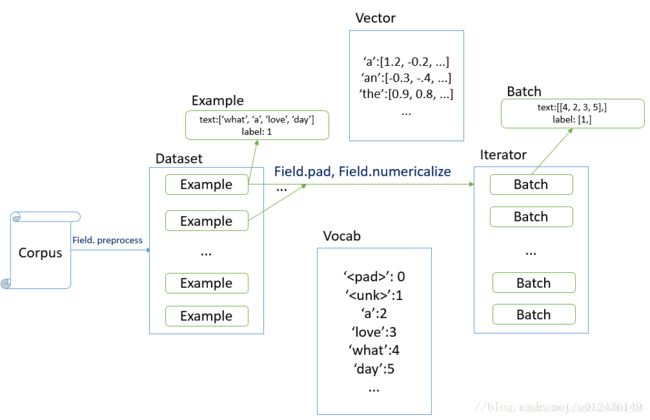
torchtext对数据的处理可以概括为Field,Dataset和迭代器三部分。
Field对象
Field对象指定要如何处理某个字段
Dataset
Dataset定义数据源信息
Arguments:
- examples: List of Examples.
- fields (List(tuple(str, Field))): The Fields to use in this tuple. The string is a field name, and the Field is the associated field.
- filter_pred (callable or None): Use only examples for which filter_pred(example) is True, or use all examples if None. Default is None.
迭代器(iterator)
迭代器返回模型所需要的处理后的数据。迭代器主要分为Iterator,BucketIterator,BPTTIterator三种。
- Iterator:标准迭代器
- BucketIterator:相比于标准迭代器,会将类似长度的样本当做一批来处理,因为在文本处理中经常会需要将每一批样本长度补齐为当前批中最长序列的长度,因此当样本长度差别较大时,使用BucketIerator可以带来填充效率的提高。除此之外,我们还可以在Field中通过fix_length参数来对样本进行截断补齐操作。
- BPTTIterator:基于BPTT(基于时间的反向传播算法)的迭代器,一般用于语言模型中。
具体使用
使用Dataset类
- 导入torchtext相关包
from torchtext import data
from torchtext.vocab import Vectors
from torch.nn import init
from tqdm import tqdm
- 构建Field对象
tokenize = lambda x: x.split()
# fix_length指定每条文本的长度,截断补长
TEXT = data.Field(sequential=True, tokenize=tokenize, lower=True, fix_length=200)
LABEL = data.Field(sequential=False, use_vocab=False)
- 使用torchtext内置的Dataset构建数据集
torchtext预置的Dataset类的API如下,我们必须至少传入examples和fields这两个参数。examples为由torchtext中的Example对象构造的列表,Example为对数据集中一条数据的抽象。fields可简单理解为每一列数据和Field对象的绑定关系,在下面的代码中将分别用train_examples和test_examples来构建训练集和测试集的examples对象,train_fields和test_fields数据集的fields对象。
class torchtext.data.Dataset(examples, fields, filter_pred=None)
train_data = pd.read_csv('data/train_one_label.csv')
valid_data = pd.read_csv('data/valid_one_label.csv')
test_data = pd.read_csv('data/test.csv')
TEXT = data.Field(sequential=True, tokenize=tokenize, lower=True)
LABEL = data.Field(sequential=False, use_vocab=False)
# get_dataset构造并返回Dataset所需的examples和fields
def get_dataset(csv_data, text_field, label_field, test=False):
fields = [('id', None), ('comment_text', text_field), ('toxic', label_field)]
examples = []
if test:
for text in tqdm(csv_data['comment_text']):
examples.append(data.Example.fromlist([None, text, None], fields))
else:
for text, label in tqdm(zip(csv_data['comment_text'], csv_data['toxic'])):
examples.append(data.Example.fromlist([None, text, label], fields))
return examples, fields
# 得到构建Dataset所需的examples和fields
train_examples, train_fields = get_dataset(train_data, TEXT, LABEL)
valid_examples, valid_fields = get_dataset(valid_data, TEXT, LABEL)
test_examples, test_fields = get_dataset(test_data, TEXT, None, True)
# 构建Dataset数据集
train = data.Dataset(train_examples, train_fields)
valid = data.Dataset(valid_examples, valid_fields)
test = data.Dataset(test_examples, test_fields)
自定义Dataset类
当构建简单的数据集时,可直接使用torch.text.Dataset来构建,当对原始数据集只进行简单的划分处理时,例如读取数据并划分训练集验证集等操作,也可以直接使用TabularDataset类和split类方法来实现,该类支持读取csv,tsv等格式。但是当我们需要对数据进行更多的预处理时,例如shuffle,dropout等数据增强操作时,自定义Dataset会更灵活。
- 核心代码:
from torchtext import data
from torchtext.vocab import Vectors
from tqdm import tqdm
import pandas as pd
import numpy as np
import torch
import random
import os
train_path = 'data/train_one_label.csv'
valid_path = 'data/valid_one_label.csv'
test_path = 'data/test.csv'
class MyDataset(data.Dataset):
def __init__(self, path, text_field, label_field, test=False, aug=False, **kwargs):
fields = [("id", None), ("comment_text", text_field), ("toxic", label_field)]
examples = []
csv_data = pd.read_csv(path)
print('read data from {}'.format(path))
if test:
for text in tqdm(csv_data['comment_text']):
examples.append(data.Example.fromlist([None, text, None], fields))
else:
for text, label in tqdm(zip(csv_data['comment_text'], csv_data['toxic'])):
if aug:
rate = random.random()
if rate > 0.5:
text = self.dropout(text)
else:
text = self.shuffle(text)
examples.append(data.Example.fromlist([None, text, label-1], fields)
super(MyDataset, self).__init__(examples, fields, **kwargs)
def shuffle(self, text):
text = np.random.permutation(text.strip().split())
return ' '.join(text)
def dropout(self, text, p=0.5):
text = text.strip().split()
len_ = len(text)
indexs = np.random.choice(len_, int(len_ * p))
for i in indexs:
text[i] = ''
retrurn ' '.join(text)
构建数据集
train = MyDataset(train_path, text_field=TEXT, label_field=LABEL, test=False, aug=1)
valid = MyDataset(valid_path, text_field=TEXT, label_field=LABEL, test=False, aug=1)
test = MyDataset(test_path, text_field=TEXT, label_field=LABEL, test=True, aug=1)
构建词表
所谓构建词表,即需要给每个单词编码,也就是用数字表示每个单词,这样才能传入模型。
最简单的方法:build_vocab()方法中传入用于构建词表的数据集
TEXT.build_vocab(train)
# 统计词频
TEXT.vocab.freqs.most_common(10)
使用预训练词向量
在使用pytorch或tensorflow等神经网络框架进行nlp任务的处理时,可以通过对应的Embedding层做词向量的处理,更多的时候,使用预训练好的词向量会带来更优的性能,下面介绍如何在torchtext中使用预训练的词向量,进而传送给神经网络模型进行训练。
1. 使用torchtext默认支持的预训练词向量
默认情况下,会自动下载对应的预训练词向量文件到当前文件夹下的.vector_cache目录下,.vector_cache为默认的词向量文件和缓存文件的目录。
from torchtext.vocab import GloVe
from torchtext import data
TEXT = data.Field(sequential=True)
TEXT.build_vocab(train, vectors=GloVe(name='6B', dim=300))
TEXT.build_vocab(train, vectors="glove.6B.300d")
2. 使用外部预训练好的词向量
上述使用预训练词向量文件的方式存在一大问题,即我们每做一个nlp任务时,建立词表时都需要在对应的.vector_cache文件夹中下载预训练词向量文件,如何解决这一问题?我们可以使用torchtext.vocab.Vectors中的name和cachae参数指定预训练的词向量文件和缓存文件的所在目录。因此我们也可以使用自己用word2vec等工具训练出的词向量文件,只需将词向量文件放在name指定的目录中即可。
- 通过name参数可以指定预训练词向量文件所在的目录
默认情况下预训练词向量文件和缓存文件的目录位置都为当前目录下的 .vector_cache目录,虽然通过name参数指定了预训练词向量文件存在的目录,但是因为缓存文件的目录没有特殊指定,此时在当前目录下仍然需要存在 .vector_cache 目录。
if not os.path.exists('.vector_cache'):
os.mkdir('.vector_cache')
vectors = Vectors(name='myvector/glove/glove.6B.200d.txt')
TEXT.build_vocab(train, vectors=vectors)
- 通过cache参数指定缓存目录
cache = '.vector_cache'
if not os.path.exists(cache):
os.mkdir(cache)
vectors = Vectors(name='myvector/glove/glove.6B.200d.txt', cache=cache)
# 指定Vector缺失值的初始化方式,没有命中的token的初始化方式
vectors.unk_init = init.uniform_
TEXT.build_vocab(train, vectors=vectors)
构建迭代器
在训练神经网络时,是对一个batch的数据进行操作,因此我们需要使用torchtext内部的迭代器对数据进行处理。
from torchtext.data import Iterator, BucketIterator
# 若只对训练集构造迭代器
# train_iter = data.BucketIterator(dataset=train, batch_size=8, shuffle=True, sort_within_batch=False, repeat=False)
# 若同时对训练集和验证集进行迭代器构建
train_iter, val_iter = BucketIterator.splits(
(train, valid),
batch_size=(8, 8),
device=-1, # 如果使用gpu,将-1更换为GPU的编号
sort_key=lambda x: len(x.comment_text),
sort_within_batch=False,
repeat=False
)
test_iter = Iterator(test, batch_size=8, device=-1, sort=False, sort_within_batch=False, repeat=False)
BucketIterator相比Iterator的优势是会自动选取样本长度相似的数据来构建批数据。但是在测试集中一般不想改变样本顺序,因此测试集使用Iterator迭代器来构建。
sort_within_batch参数设置为True时,按照sort_key按降序对每个小批次内的数据进行排序。如果我们需要padded序列使用pack_padded_sequence转换为PackedSequence对象时,这是非常重要的,我们知道如果想pack_padded_sequence方法必须将批样本按照降序排列。由此可见,torchtext不仅可以对文本数据进行很方便的处理,还可以很方便的和torchtext的很多内建方法进行结合使用。
批数据的使用
for idx, batch in enumerate(train_iter):
text, label = batch.comment_text, batch.toxic
在模型中指定Embedding层的权重
在使用预训练好的词向量时,我们需要在神经网络模型的Embedding层中明确地传递嵌入矩阵的初始权重。权重包含在词汇表的vectors属性中。以Pytorch搭建的Embedding层为例:
embedding = nn.Embedding(2000, 256)
weight_matrix = TEXT.vocab.vectors
embedding.weight.data.copy_(weight_matrix)
使用torchtext构建的数据集用于LSTM
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
weight_matrix = TEXT.vocab.vectors
class LSTM(nn.Module):
def __init__(self):
super(LSTM, self).__init__()
self.word_embeddings = nn.Embedding(len(TEXT.vocab), 300)
self.word_embeddings.weight.data.copy_(weight_matrix)
self.lstm = nn.LSTM(input_size=300, hidden_size=128, num_layer=1)
self.decoder = nn.Linear(128, 2)
def forward(self, sentence):
embeds = self.word_embeddings(sentence)
lstm_out = self.lstm(embeds)[0]
final = lstm_out[-1]
y = self.decoder(final)
return y
def main():
model = LSTM()
model.train()
optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=0.01)
loss_funciton = F.cross_entropy
for epoch, batch in enumerate(train_iter):
optimizer.zero_grad()
start = time.time()
predicted = model(batch.comment_text)
loss = loss_function(predicted, batch.toxic)
loss.backward()
optimizer.step()
print(loss)
一个使用torchtext内置数据集的例子
import torch
from torchtext import data
from torchtext import datasets
from torchtext.vocab import GloVe
import numpy as np
def load_data(opt):
print('loading {} dataset'.format(opt.dataset))
text = data.Field(lower=True, include_lengths=True, batch_first=True, fix_length=opt.max_seq_len)
label = data.Field(sequential=False)
train, test = datasets.IMDB.splits(text, label)
text.build_vocab(train, vectors=GloVe(name='6B', dim=300)
label.build_vocab(train)
print('len(TEXT.vocab)', len(text.vocab))
print('TEXT.vocab.vectors.size()', text.vocab.vectors.size())
读取json文件并生成batch
设置Field
# 设置Field
from torchtext import data
question = data.Field(sequential=True, fix_length=20, pad_token='0')
label = data.Field(sequential=False, use_vocab=False)
| sequential=True | tokenizer | fix_length | pad_first=True | tensor_type | lower |
|---|---|---|---|---|---|
| 是否为sequences | 分词器 | 文本长度 | 是否从左补全 | Tensor type | 是否令英文字符为小写 |
sequential表明输入是否是序列文本,序列文本需要配合tokenize进行分词(默认使用splits)。如果需要处理中文文本,可以自定义tokenizer对中文进行切分。
import jieba
def chinese_tokenizer(text):
return [tok for tok in jieba.lcut(text)]
question = data.Field(sequential=True, tokenize=chinese_tokenizer, fix_length=20)
使用torchtext.data.Tabulardataset.splits读取文件
Tabulardataset:Defines a Dataset of columns stored in CSV, TSV, or JSON format.
train, val, test = data.TabularDataset.splits(
path='./',
train='train.json',
validation='test.json',
test='test.json',
format='json',
# fields (list(tuple(str, Field)) or dict[str: tuple(str, Field)]
fields={'question': ('question': question), 'label': ('label': label)})
构建vocab表
cache = '.vector_cache'
if not os.path.exists(cache):
os.mkdir(cache)
vectors = Vectors(name=configs.embedding_path, cache=cache)
vectors.unk_init = init.xaiver_uniform_
使用torchtext.data.Iterator.splits生成batch
train_iter = data.Iterator(dataset=train, batch_size=256, shuffle=True, sort_within_batch=False, repeat=False, device=configs.device)
val_iter = data.Iterator(dataset=val, batch_size=256, shuffle, sort=False, repeat=False, device=configs.device)
test_iter = data.Iterator(dataset=test, batch_size=256, sort=False, repeat=False, device=configs.device)
dataset:加载的数据集
batch_size:Batch的大小
batch_size_fn:产生动态的batch_size的函数
sort_key:排序的key
train:是否是训练集
repeat:是否在不同epoch中重复迭代
shuffle:是否打乱数据
sort:是否对数据进行排序
sort_with_batch:batch内部是否排序
做推理的例子
模型训练完后, 需要对真实数据进行推理预测结果.
以下是一个二分类的例子.
def predict(model, sentence, min_len = 5):
model.eval()
tokenized = [tok.text for tok in nlp.tokenizer(sentence)]
if len(tokenized) < min_len:
tokenized += ['' ] * (min_len - len(tokenized))
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(1)
prediction = torch.sigmoid(model(tensor))
return prediction.item()
参考链接
torchtext使用
torchtext官方文档
A Tutorial on Torchtext
pytorch学习笔记(十九):torchtext