Python爬取58同城招聘信息
微信搜索关注“程序员微读”公众号,查看更多
环境要求:
(1)python3环境
(2)requests模块:是一个很实用的Python HTTP客户端库,安装指令pip install requests
(3)BeautifulSoup模块:提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,安装指令pip install BeautifulSoup
(4)lxml模块:解析HTML代码,pip install lxml
具体爬取过程
以杭州的软件工程师招聘信息为例
第一步:分析url
通过访问招聘信息的页面,发现共有九页内容,通过访问几页内容发现url是规律的,具体如下
第一页:http://hz.58.com/ruanjiangong/pn1/
第二页:http://hz.58.com/ruanjiangong/pn2/
第三页:http://hz.58.com/ruanjiangong/pn3/
…
第九页:http://hz.58.com/ruanjiangong/pn9/
发现url的规律之后,我们就可以轻轻松松的通过for循环爬取每一页的内容了。
第二步:分析源码以及如何获取指定数据
下面以第一页为例分析网页源码从而获取指定数据(假设我们只需要知道公司位置/具体职位/月薪/公司名称/福利/公司招聘网址):
我们通过查看源码发现每一条招聘信息对于一个li标签,而每个li中又通过div来分块,这样我们可以通过li的class属性值来获取这一系列标签,然后通过div的class属性值来获取某一区域的内容,接下来我们需要通过按标签一级一级来进行定位来从每个区域提取上述列出的内容。
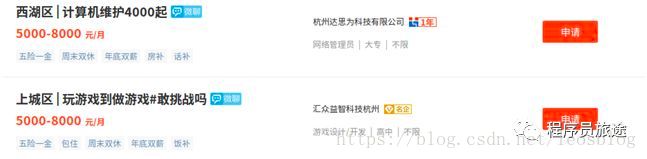
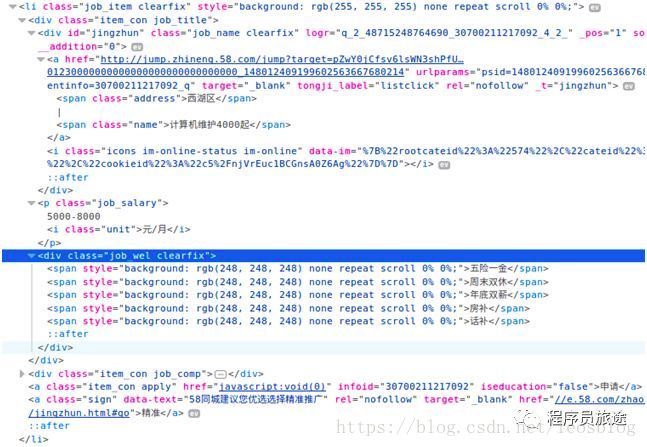
下面以获取某公司位置为例,鼠标放在“西湖区”右击选择检查(或查看元素)

这样我们可以在每个li标签中通过筛选每级的class值来获取公司位置,即位置获取方式是通过"div.item_con span.address"来获取,对应的python代码为:
address = item.select("div.item_con span.address")[0].text #select()返回的是list类型,text是获取标签的内容
同理,我们可以得出
name = item.select("div.item_con span.name")[0].text
salary = item.select("div.item_con p.job_salary")[0].text
welfare = item.select("div.item_con div.job_wel")[0].text
company = item.select("div.item_con div.comp_name a.fl")[0].text
href = item.select("div.item_con div.comp_name a.fl")[0].get("href") #get()是通过属性名来获取属性值
第三步:编写代码
根据第二步得出的数据的获取方式,接下来就是代码实现了
import requests
import time
from bs4 import BeautifulSoup
url = "http://hz.58.com/ruanjiangong/pn{}"
def spider():
for i in range(9):
req = requests.get(url.format(str(i + 1)))
req.encoding = "utf-8" #设置成网页的编码
soup = BeautifulSoup(req.text, "lxml")
items = soup.select("li.job_item")
for item in items:
address = item.select("div.item_con span.address")[0].text #select()返回的是list类型
name = item.select("div.item_con span.name")[0].text
salary = item.select("div.item_con p.job_salary")[0].text
if len(item.select("div.item_con div.job_wel")) > 0:
welfare = item.select("div.item_con div.job_wel")[0].text
company = item.select("div.item_con div.comp_name a.fl")[0].text
href = item.select("div.item_con div.comp_name a.fl")[0].get("href")
print("%s\t%s\t%s\t%s\t%s\t%s"%(address, name, salary, company,welfare,href))
time.sleep(2)
if __name__ == '__main__':
spider()
第四步:运行获取数据
运行代码,输出所需的数据:
