socket通信和异常处理札记
Linux socket通信出现CLOSE_WAIT状态的原因与解决方法
这个问题之前没有怎么留意过,是最近在面试过程中遇到的一个问题,面了两家公司,两家公司竟然都面到到了这个问题,不得不使我开始关注这个问题。说起CLOSE_WAIT状态,如果不知道的话,还是先瞧一下TCP的状态转移图吧。
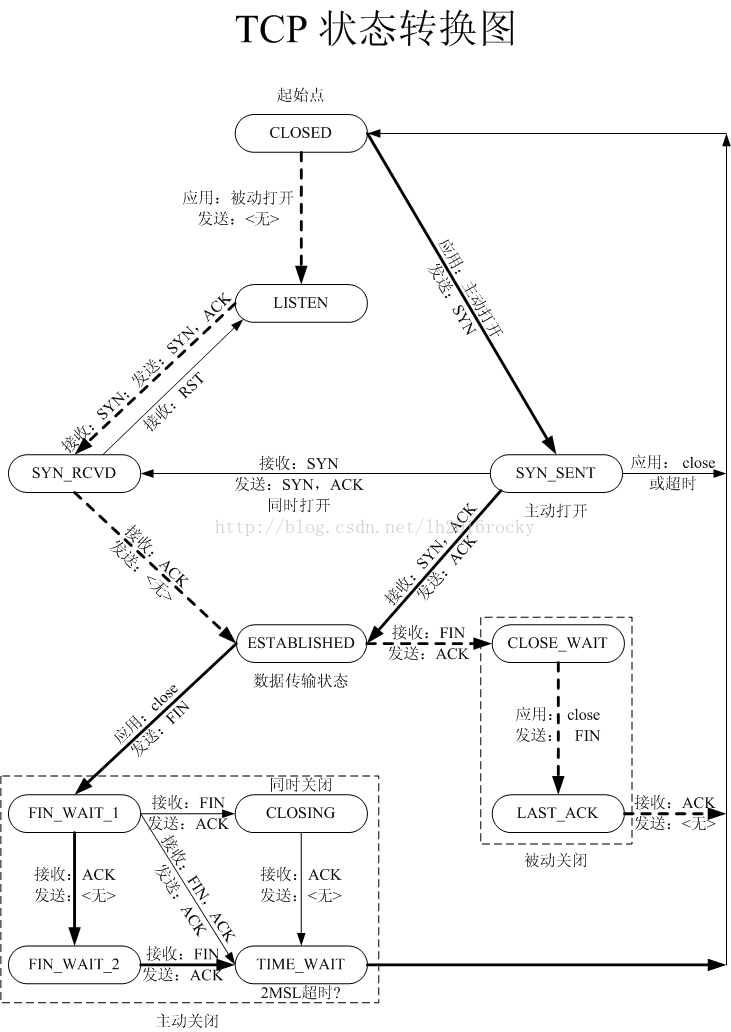
关闭socket分为主动关闭(Active closure)和被动关闭(Passive closure)两种情况。前者是指有本地主机主动发起的关闭;而后者则是指本地主机检测到远程主机发起关闭之后,作出回应,从而关闭整个连接。将关闭部分的状态转移摘出来,就得到了下图:

产生原因
通过图上,我们来分析,什么情况下,连接处于CLOSE_WAIT状态呢?
在被动关闭连接情况下,在已经接收到FIN,但是还没有发送自己的FIN的时刻,连接处于CLOSE_WAIT状态。
通常来讲,CLOSE_WAIT状态的持续时间应该很短,正如SYN_RCVD状态。但是在一些特殊情况下,就会出现连接长时间处于CLOSE_WAIT状态的情况。
出现大量close_wait的现象,主要原因是某种情况下对方关闭了socket链接,但是我方忙与读或者写,没有关闭连接。代码需要判断socket,一旦读到0,断开连接,read返回负,检查一下errno,如果不是AGAIN,就断开连接。
参考资料4中描述,通过发送SYN-FIN报文来达到产生CLOSE_WAIT状态连接,没有进行具体实验。不过个人认为协议栈会丢弃这种非法报文,感兴趣的同学可以测试一下,然后把结果告诉我;-)
为了更加清楚的说明这个问题,我们写一个测试程序,注意这个测试程序是有缺陷的。
只要我们构造一种情况,使得对方关闭了socket,我们还在read,或者是直接不关闭socket就会构造这样的情况。
server.c:
#include
#include
#include
#define MAXLINE 80
#define SERV_PORT 8000
int main(void)
{
struct sockaddr_in servaddr, cliaddr;
socklen_t cliaddr_len;
int listenfd, connfd;
char buf[MAXLINE];
char str[INET_ADDRSTRLEN];
int i, n;
listenfd = socket(AF_INET, SOCK_STREAM, 0);
int opt = 1;
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(SERV_PORT);
bind(listenfd, (struct sockaddr *)&servaddr, sizeof(servaddr));
listen(listenfd, 20);
printf("Accepting connections ...\n");
while (1) {
cliaddr_len = sizeof(cliaddr);
connfd = accept(listenfd,
(struct sockaddr *)&cliaddr, &cliaddr_len);
//while (1)
{
n = read(connfd, buf, MAXLINE);
if (n == 0) {
printf("the other side has been closed.\n");
break;
}
printf("received from %s at PORT %d\n",
inet_ntop(AF_INET, &cliaddr.sin_addr, str, sizeof(str)),
ntohs(cliaddr.sin_port));
for (i = 0; i //这里故意不关闭socket,或者是在close之前加上一个sleep都可以
//sleep(5);
//close(connfd);
}
}
client.c:
#include
#include
#include
#include
#include
#include
#define MAXLINE 80
#define SERV_PORT 8000
int main(int argc, char *argv[])
{
struct sockaddr_in servaddr;
char buf[MAXLINE];
int sockfd, n;
char *str;
if (argc != 2) {
fputs("usage: ./client message\n", stderr);
exit(1);
}
str = argv[1];
sockfd = socket(AF_INET, SOCK_STREAM, 0);
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
inet_pton(AF_INET, "127.0.0.1", &servaddr.sin_addr);
servaddr.sin_port = htons(SERV_PORT);
connect(sockfd, (struct sockaddr *)&servaddr, sizeof(servaddr));
write(sockfd, str, strlen(str));
n = read(sockfd, buf, MAXLINE);
printf("Response from server:\n");
write(STDOUT_FILENO, buf, n);
write(STDOUT_FILENO, "\n", 1);
close(sockfd);
return 0;
}
结果如下:
debian-wangyao:~$ ./client a
Response from server:
A
debian-wangyao:~$ ./client b
Response from server:
B
debian-wangyao:~$ ./client c
Response from server:
C
debian-wangyao:~$ netstat -antp | grep CLOSE_WAIT
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 1 0 127.0.0.1:8000 127.0.0.1:58309 CLOSE_WAIT 6979/server
tcp 1 0 127.0.0.1:8000 127.0.0.1:58308 CLOSE_WAIT 6979/server
tcp 1 0 127.0.0.1:8000 127.0.0.1:58307 CLOSE_WAIT 6979/server
解决方法
基本的思想就是要检测出对方已经关闭的socket,然后关闭它。
1.代码需要判断socket,一旦read返回0,断开连接,read返回负,检查一下errno,如果不是AGAIN,也断开连接。(注:在UNP 7.5节的图7.6中,可以看到使用select能够检测出对方发送了FIN,再根据这条规则就可以处理CLOSE_WAIT的连接)
2.给每一个socket设置一个时间戳last_update,每接收或者是发送成功数据,就用当前时间更新这个时间戳。定期检查所有的时间戳,如果时间戳与当前时间差值超过一定的阈值,就关闭这个socket。
3.使用一个Heart-Beat线程,定期向socket发送指定格式的心跳数据包,如果接收到对方的RST报文,说明对方已经关闭了socket,那么我们也关闭这个socket。
4.设置SO_KEEPALIVE选项,并修改内核参数
前提是启用socket的KEEPALIVE机制://启用socket连接的KEEPALIVEint iKeepAlive = 1;setsockopt(s, SOL_SOCKET, SO_KEEPALIVE, (void *)&iKeepAlive, sizeof(iKeepAlive));
缺点:影响所有打开KEEPALIVE选项的socket;-(
tcp_keepalive_intvl (integer; default: 75; since Linux 2.4)
The number of seconds between TCP keep-alive probes.
tcp_keepalive_probes (integer; default: 9; since Linux 2.2)
The maximum number of TCP keep-alive probes to send before giving up and killing the connection if no response is obtained from the other end.
tcp_keepalive_time (integer; default: 7200; since Linux 2.2)
The number of seconds a connection needs to be idle before TCP begins sending out keep-alive probes. Keep-alives are only sent when the SO_KEEPALIVE socket option is enabled. The default value is 7200 seconds (2 hours). An idle connec‐ ion is terminated after approximately an additional 11 minutes (9 probes an interval of 75 seconds apart) when keep-alive is enabled.
echo 120 > /proc/sys/net/ipv4/tcp_keepalive_time
echo 2 > /proc/sys/net/ipv4/tcp_keepalive_intvl
echo 1 > /proc/sys/net/ipv4/tcp_keepalive_probes
参考:
http://blog.chinaunix.net/u/20146/showart_1217433.html
http://blog.csdn.net/eroswang/archive/2008/03/10/2162986.aspx
http://haka.sharera.com/blog/BlogTopic/32309.htm
http://learn.akae.cn/media/ch37s02.html
http://faq.csdn.net/read/208036.html
http://www.cndw.com/tech/server/2006040430203.asp
http://davidripple.bokee.com/1741575.html
http://doserver.net/post/keepalive-linux-1.php
本文来自ChinaUnix博客,如果查看原文请点:http://blog.chinaunix.net/u2/76292/showart_2060881.html
linux下 CLOSE_WAIT过多的解决方法
情景描述:系统产生大量“Too many open files”
原因分析:在服务器与客户端通信过程中,因服务器发生了socket未关导致的closed_wait发生,致使监听port打开的句柄数到了1024个,且均处于close_wait的状态,最终造成配置的port被占满出现“Too many open files”,无法再进行通信。
close_wait状态出现的原因是被动关闭方未关闭socket造成,如附件图所示:
解决办法:有两种措施可行
一、解决:
原因是因为调用ServerSocket类的accept()方法和Socket输入流的read()方法时会引起线程阻塞,所以应该用setSoTimeout()方法设置超时(缺省的设置是0,即超时永远不会发生);超时的判断是累计式的,一次设置后,每次调用引起的阻塞时间都从该值中扣除,直至另一次超时设置或有超时异常抛出。
比如,某种服务需要三次调用read(),超时设置为1分钟,那么如果某次服务三次read()调用的总时间超过1分钟就会有异常抛出,如果要在同一个Socket上反复进行这种服务,就要在每次服务之前设置一次超时。
二、规避:
调整系统参数,包括句柄相关参数和TCP/IP的参数;
注意:
/proc/sys/fs/file-max 是整个系统可以打开的文件数的限制,由sysctl.conf控制;
ulimit修改的是当前shell和它的子进程可以打开的文件数的限制,由limits.conf控制;
lsof是列出系统所占用的资源,但是这些资源不一定会占用打开文件号的;比如:共享内存,信号量,消息队列,内存映射等,虽然占用了这些资源,但不占用打开文件号;
因此,需要调整的是当前用户的子进程打开的文件数的限制,即limits.conf文件的配置;
如果cat /proc/sys/fs/file-max值为65536或甚至更大,不需要修改该值;
若ulimit -a ;其open files参数的值小于4096(默认是1024),则采用如下方法修改open files参数值为8192;方法如下:
1.使用root登陆,修改文件/etc/security/limits.conf
vi /etc/security/limits.conf 添加
xxx - nofile 8192
xxx 是一个用户,如果是想所有用户生效的话换成 *,设置的数值与硬件配置有关,别设置太大了。
#
* soft nofile 8192
* hard nofile 8192
#所有的用户每个进程可以使用8192个文件描述符。
2.使这些限制生效
确定文件/etc/pam.d/login和/etc/pam.d/sshd包含如下行:
session required pam_limits.so
然后用户重新登陆一下即可生效。
3. 在bash下可以使用ulimit -a参看是否已经修改:
一、 修改方法:(暂时生效,重新启动服务器后,会还原成默认值)
sysctl -w net.ipv4.tcp_keepalive_time=600
sysctl -w net.ipv4.tcp_keepalive_probes=2
sysctl -w net.ipv4.tcp_keepalive_intvl=2
注意:Linux的内核参数调整的是否合理要注意观察,看业务高峰时候效果如何。
二、 若做如上修改后,可起作用;则做如下修改以便永久生效。
vi /etc/sysctl.conf
若配置文件中不存在如下信息,则添加:
net.ipv4.tcp_keepalive_time = 1800
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl = 15
编辑完 /etc/sysctl.conf,要重启network才会生效
/etc/rc.d/init.d/network restart
然后,执行sysctl命令使修改生效,基本上就算完成了。
------------------------------------------------------------
修改原因:
当客户端因为某种原因先于服务端发出了FIN信号,就会导致服务端被动关闭,若服务端不主动关闭socket发FIN给Client,此时服务端Socket会处于CLOSE_WAIT状态(而不是LAST_ACK状态)。通常来说,一个CLOSE_WAIT会维持至少2个小时的时间(系统默认超时时间的是7200秒,也就是2小时)。如果服务端程序因某个原因导致系统造成一堆CLOSE_WAIT消耗资源,那么通常是等不到释放那一刻,系统就已崩溃。因此,解决这个问题的方法还可以通过修改TCP/IP的参数来缩短这个时间,于是修改tcp_keepalive_*系列参数:
tcp_keepalive_time:
/proc/sys/net/ipv4/tcp_keepalive_time
INTEGER,默认值是7200(2小时)
当keepalive打开的情况下,TCP发送keepalive消息的频率。建议修改值为1800秒。
tcp_keepalive_probes:INTEGER
/proc/sys/net/ipv4/tcp_keepalive_probes
INTEGER,默认值是9
TCP发送keepalive探测以确定该连接已经断开的次数。(注意:保持连接仅在SO_KEEPALIVE套接字选项被打开是才发送.次数默认不需要修改,当然根据情形也可以适当地缩短此值.设置为5比较合适)
tcp_keepalive_intvl:INTEGER
/proc/sys/net/ipv4/tcp_keepalive_intvl
INTEGER,默认值为75
当探测没有确认时,重新发送探测的频度。探测消息发送的频率(在认定连接失效之前,发送多少个TCP的keepalive探测包)。乘以tcp_keepalive_probes就得到对于从开始探测以来没有响应的连接杀除的时间。默认值为75秒,也就是没有活动的连接将在大约11分钟以后将被丢弃。(对于普通应用来说,这个值有一些偏大,可以根据需要改小.特别是web类服务器需要改小该值,15是个比较合适的值)
【检测办法】
1. 系统不再出现“Too many open files”报错现象。
2. 处于TIME_WAIT状态的sockets不会激长。
在 Linux 上可用以下语句看了一下服务器的TCP状态(连接状态数量统计):
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
返回结果范例如下:
ESTABLISHED 1423
FIN_WAIT1 1
FIN_WAIT2 262
SYN_SENT 1
TIME_WAIT 962
socket shutdown close操作
int transport_close(int sock)
{
int rc;
rc = shutdown(sock, SHUT_WR);
rc = recv(sock, NULL, (size_t)0, 0);
rc = close(sock);
return rc;
}
socket关闭的close和shutdown区别
socket关闭有2个close,shutdown
他们之间的区别:
close-----关闭本进程的socket id,但链接还是开着的,用这个socket id的其它进程还能用这个链接,能读或写这个socket id
shutdown--则破坏了socket链接,读的时候可能侦探到EOF结束符,写的时候可能会收到一个SIGPIPE信号,这个信号可能直到
socket buffer被填充了才收到,shutdown还有一个关闭方式的参数,0不能再读,1不能再写,2读写都不能。
===============================================================================================================
socket 多进程中的shutdown, close使用
当所有的数据操作结束以后,你可以调用close()函数来释放该socket,从而停止在该socket上的任何数据操作:
close(sockfd);
你也可以调用shutdown()函数来关闭该socket。该函数允许你只停止在某个方向上的数据传输,而一个方向上的数据传输继
续进行。如你可以关闭某socket的写操作而允许继续在该socket上接受数据,直至读入所有数据。
int shutdown(int sockfd,int how);
Sockfd是需要关闭的socket的描述符。参数 how允许为shutdown操作选择以下几种方式:
SHUT_RD:关闭连接的读端。也就是该套接字不再接受数据,任何当前在套接字接受缓冲区的数据将被丢弃。进程将不能对该
套接字发出任何读操作。对TCP套接字该调用之后接受到的任何数据将被确认然后无声的丢弃掉。
SHUT_WR:关闭连接的写端,进程不能在对此套接字发出写操作
SHUT_RDWR:相当于调用shutdown两次:首先是以SHUT_RD,然后以SHUT_WR
使用close中止一个连接,但它只是减少描述符的参考数,并不直接关闭连接,只有当描述符的参考数为0时才关闭连接。
shutdown可直接关闭描述符,不考虑描述符的参考数,可选择中止一个方向的连接。
注意:
1>. 如果有多个进程共享一个套接字,close每被调用一次,计数减1,直到计数为0时,也就是所用进程都调用了close,套
接字将被释放。
2>. 在多进程中如果一个进程中shutdown(sfd, SHUT_RDWR)后其它的进程将无法进行通信.如果一个进程close(sfd)将不会
影响到其它进程. 得自己理解引用计数的用法了.有Kernel编程知识的更好理解了.
以上为转载文章,后面个人的理解一般在开发过程中,应该是先close(),如果close()失败才再去调用shutdown()操作,如果shutdown()再失败,一般这个情况的时候就不是一般的错误发生了,对于这种错误就涉及到操作系统内核级的错误了,所以应用程序开发到这一级就足以。
要注意的是,虽然shutdown()提供了读写分别关闭的操作,但是它是影响到所有的进程的,所以需要注意。
关于close与shutdown的区别
终止网络连接的通常方法是调用close函数。不过close有两个限制,却可以使用shutdown来避免。
1 close把描述字的引用计数减1,仅在该计数变为0的时候才关闭套接口。而使用shutdown可以不管引用计数的值是多少就激发TCP的正常连接终止序列,也即是发送FIN节。
2 close终止数据传送的两个方向:读和写。而有的时候只是想关闭读或写,那么此时就使用shutdown函数进行关闭套接口描述字某一方向的操作。
例如:在有父子进程的服务器程序中,套接口描述字是在父子进程之间共享的,因此它的引用计数为2。要是父进程调用close,那么这只是把该引用计数由2减为1,而且既然它仍然大于,FIN就不发送。这就是为什么在shutdown函数的原因,不管套接口的计数值为多少,FIN都必须被近发送出去。 当shutdown函数中的第2个参数为SHUT_WR的时候,称为半关闭,此操作后,当前留在套接口发送缓冲中的数据将被发送掉,后跟TCP的正常连接终止序列。
linux网络编程常见socket错误分析
EINTR:
阻塞的操作被取消阻塞的调用打断。如设置了发送接收超时,就会遇到这种错误。
只能针对阻塞模式的socket。读,写阻塞的socket时,-1返回,错误号为INTR。另外,如果出现EINTR即errno为4,错误描述 Interrupted system call,操作也应该继续。如果recv的返回值为0,那表明连接已经断开,接收操作也应该结束。
ETIMEOUT:
1、操作超时。一般设置了发送接收超时,遇到网络繁忙的情况,就会遇到这种错误。
2、服务器做了读数据做了超时限制,读时发生了超时。
3、错误被描述为“connect time out”,即“连接超时”,这种情况一般发生在服务器主机崩溃。此时客户 TCP 将在一定时间内(依具体实现)持续重发数据分节,试图从服务 TCP获得一个 ACK分节。当最终放弃尝试后(此时服务器未重新启动),内核将会向客户进程返回 ETIMEDOUT错误。如果某个中间路由器判定该服务器主机已经不可达,则一般会响应“destination unreachable”-“目的地不可达”的ICMP消息,相应的客户进程返回的错误是 EHOSTUNREACH 或ENETUNREACH。当服务器重新启动后,由于 TCP状态丢失,之前所有的连接信息也不存在了,此时对于客户端发来请求将回应 RST。如果客户进程对检测服务器主机是否崩溃很有必要,要求即使客户进程不主动发送数据也能检测出来,那么需要使用其它技术,如配置 SO_KEEPALIVE Socket选项,或实现某些心跳函数。
EAGAIN:
1、Send返回值小于要发送的数据数目,会返回EAGAIN和EINTR。
2、recv 返回值小于请求的长度时说明缓冲区已经没有可读数据,但再读不一定会触发EAGAIN,有可能返回0表示TCP连接已被关闭。
3、当socket是非阻塞时,如返回此错误,表示写缓冲队列已满,可以做延时后再重试.
4、在Linux进行非阻塞的socket接收数据时经常出现Resource temporarily unavailable,errno代码为11(EAGAIN),表明在非阻塞模式下调用了阻塞操作,在该操作没有完成就返回这个错误,这个错误不会破坏 socket的同步,不用管它,下次循环接着recv就可以。对非阻塞socket而言,EAGAIN不是一种错误。
EWOULDBLOCK:EAGAIN (POSIX.1-2001 allows)
资源暂时不可用。这个错误是从对非阻塞socket进行的不能立即结束的操作返回的,如当没有数据在队列中可以读时,调用recv。并不是fatal错误,稍后操作可以被重复。调用在一个非阻塞的SOCK_STREAM socket 上调用connect时会产生这个错误,因为有时连接建立必须消耗一定的时间。
EPIPE:
1、Socket 关闭,但是socket号并没有置-1。继续在此socket上进行send和recv,就会返回这种错误。这个错误会引发SIGPIPE信号,系统会将产生此EPIPE错误的进程杀死。所以,一般在网络程序中,首先屏蔽此消息,以免发生不及时设置socket进程被杀死的情况。
2、write(..) on a socket that has been closed at the other end will cause a SIGPIPE.
3、错误被描述为“broken pipe”,即“管道破裂”,这种情况一般发生在客户进程不理会(或未及时处理)Socket错误,继续向服务 TCP 写入更多数据时,内核将向客户进程发送 SIGPIPE信号,该信号默认会使进程终止(此时该前台进程未进行 core dump)。结合上边的 ECONNRESET错误可知,向一个 FIN_WAIT2状态的服务 TCP(已 ACK响应 FIN 分节)写入数据不成问题,但是写一个已接收了 RST的 Socket则是一个错误。
ECONNREFUSED:
1、拒绝连接。一般发生在连接建立时。
拔服务器端网线测试,客户端设置keep alive时,recv较快返回0,先收到ECONNREFUSED (Connection refused)错误码,其后都是ETIMEOUT。
2、an error returned from connect(), so it can only occur in a client (if a client is defined as the party that initiates the connection
ECONNRESET:
1、在客户端服务器程序中,客户端异常退出,并没有回收关闭相关的资源,服务器端会先收到ECONNRESET错误,然后收到EPIPE错误。
2、连接被远程主机关闭。有以下几种原因:远程主机停止服务,重新启动;当在执行某些操作时遇到失败,因为设置了“keep alive”选项,连接被关闭,一般与ENETRESET一起出现。
3、远程端执行了一个“hard”或者“abortive”的关闭。应用程序应该关闭socket,因为它不再可用。当执行在一个UDP socket上时,这个错误表明前一个send操作返回一个ICMP“port unreachable”信息。
4、如果client关闭连接,server端的select并不出错(不返回-1,使用select对唯一一个socket进行non- blocking检测),但是写该socket就会出错,用的是send.错误号:ECONNRESET.读(recv)socket并没有返回错误。
5、该错误被描述为“connection reset by peer”,即“对方复位连接”,这种情况一般发生在服务进程较客户进程提前终止。当服务进程终止时会向客户 TCP 发送 FIN 分节,客户 TCP 回应 ACK,服务 TCP将转入 FIN_WAIT2 状态。此时如果客户进程没有处理该 FIN(如阻塞在其它调用上而没有关闭 Socket时),则客户 TCP 将处于 CLOSE_WAIT状态。当客户进程再次向 FIN_WAIT2状态的服务 TCP发送数据时,则服务 TCP将立刻响应 RST。一般来说,这种情况还可以会引发另外的应用程序异常,客户进程在发送完数据后,往往会等待从网络IO接收数据,很典型的如 read 或 readline 调用,此时由于执行时序的原因,如果该调用发生在 RST分节收到前执行的话,那么结果是客户进程会得到一个非预期的 EOF错误。此时一般会输出“server terminated prematurely”-“服务器过早终止”错误。
ECONNABORTED:
1、软件导致的连接取消。一个已经建立的连接被host方的软件取消,原因可能是数据传输超时或者是协议错误。
2、该错误被描述为“software caused connection abort”,即“软件引起的连接中止”。原因在于当服务和客户进程在完成用于 TCP 连接的“三次握手”后,客户 TCP却发送了一个 RST (复位)分节,在服务进程看来,就在该连接已由 TCP排队,等着服务进程调用 accept的时候 RST却到达了。POSIX规定此时的 errno值必须 ECONNABORTED。源自 Berkeley的实现完全在内核中处理中止的连接,服务进程将永远不知道该中止的发生。服务器进程一般可以忽略该错误,直接再次调用accept。
当TCP协议接收到RST数据段,表示连接出现了某种错误,函数read将以错误返回,错误类型为ECONNERESET。并且以后所有在这个套接字上的读操作均返回错误。错误返回时返回值小于0。
连接过程出错分析
(1)如果客户机TCP协议没有接收到对它的SYN数据段的确认,函数以错误返回,错误类型为ETIMEOUT。通常TCP协议在发送SYN数据段失败之后,会多次发送SYN数据段,在所有的发送都高中失败之后,函数以错误返回。
注:SYN(synchronize)位:请求连接。TCP用这种数据段向对方TCP协议请求建立连接。在这个数据段中,TCP协议将它选择的初始序列号通知对方,并且与对方协议协商最大数据段大小。SYN数据段的序列号为初始序列号,这个SYN数据段能够被确认。当协议接收到对这个数据段的确认之后,建立TCP连接。
(2)如果远程TCP协议返回一个RST数据段,函数立即以错误返回,错误类型为ECONNREFUSED。当远程机器在SYN数据段指定的目的端口号处没有服务进程在等待连接时,远程机器的TCP协议将发送一个RST数据段,向客户机报告这个错误。客户机的TCP协议在接收到RST数据段后不再继续发送SYN数据段,函数立即以错误返回。
注:RST(reset)位:表示请求重置连接。当TCP协议接收到一个不能处理的数据段时,向对方TCP协议发送这种数据段,表示这个数据段所标识的连接出现了某种错误,请求TCP协议将这个连接清除。有3种情况可能导致TCP协议发送RST数据段:(1)SYN数据段指定的目的端口处没有接收进程在等待;(2)TCP协议想放弃一个已经存在的连接;(3)TCP接收到一个数据段,但是这个数据段所标识的连接不存在。接收到RST数据段的TCP协议立即将这条连接非正常地断开,并向应用程序报告错误。
(3)如果客户机的SYN数据段导致某个路由器产生“目的地不可到达”类型的ICMP消息,函数以错误返回,错误类型为EHOSTUNREACH或 ENETUNREACH。通常TCP协议在接收到这个ICMP消息之后,记录这个消息,然后继续几次发送SYN数据段,在所有的发送都告失败之后,TCP协议检查这个ICMP消息,函数以错误返回。
注:ICMP:Internet消息控制协议。Internet的运行主要是由Internet的路由器来控制,路由器完成IP数据包的发送和接收,如果发送数据包时发生错误,路由器使用 ICMP协议来报告这些错误。
调用函数connect的过程中,当客户机TCP协议发送了SYN数据段的确认之后,TCP状态由CLOSED状态转为SYN_SENT状态,在接收到对 SYN数据段的确认之后,TCP状态转换成ESTABLISHED状态,函数成功返回。如果调用函数connect失败,应该用close关闭这个套接字描述符,不能再次使用这个套接字描述符来调用函数connect。
connect函数的出错处理:
(1)ETIMEOUT-connection timed out目的主机不存在,没有返回任何相应,例如主机关闭
(2)ECONNREFUSED-connection refused(硬错)到达目的主机后,由于各种原因建立不了连接,主机返回RST(复位)响应,例如主机监听进程未启用,tcp取消连接等
(3)EHOSTTUNREACH-no route to host(软错)路由上引发了一个目的地不可达的ICMP错误
其中(1)(3),客户端会进行定时多次重试,一定次数后才返回错误。另外,当connect连接失败时,sockfd套接口不可用,必须关闭后重新socket分配才行。
gethostbyname失败
分类: LINUX
网络编程时,gethostbyname失败一次之后便总是失败,查找了原因,发现是实现的库函数只读一次存储dns的文件,放到缓存里。因此当dns存储文件更新之后,gethostbyname就会失败。解决方式是通过调用res_init()强制更新一下,但是效率肯定受影响了。
写了一个非常简单的测试程序,在SUN Solaris是可以编译通过的
请楼上的几位在HP-UX上测试一下能编译成功吗?
#include
#include
#include
#include
#include
int main(int argc, char **argv)
{
int ret = res_init();
if(ret != 0 )
{
printf("init error\n"
;
return -1;
}
else
{
printf("test ok\n"
;
}
return 0;
}
gethostbyname和 gethostbyname_r(可重入的)得到dns信息
分类: linux_高级编程2012-04-06 14:03 3204人阅读评论(0)收藏举报
nulldststruct网络googlelist
使用这个东西,首先要包含2个头文件:
#include
#include
struct hostent *gethostbyname(const char *name);
这个函数的传入值是域名或者主机名,例如"www.google.com","wpc"等等。
传出值,是一个hostent的结构(如下)。如果函数调用失败,将返回NULL。
struct hostent {
char *h_name;
char **h_aliases;
int h_addrtype;
int h_length;
char **h_addr_list;
};
解释一下这个结构, 其中:
char *h_name 表示的是主机的规范名。例如www.google.com的规范名其实是www.l.google.com。
char **h_aliases 表示的是主机的别名。www.google.com就是google他自己的别名。有的时候,有的主机可能有好几个别名,这些,其实都是为了易于用户记忆而为自己的网站多取的名字。
int h_addrtype 表示的是主机ip地址的类型,到底是ipv4(AF_INET),还是ipv6(AF_INET6)
int h_length 表示的是主机ip地址的长度
int **h_addr_lisst 表示的是主机的ip地址,注意,这个是以网络字节序存储的。千万不要直接用printf带%s参数来打这个东西,会有问题的哇。所以到真正需要打印出这个IP的话,需要调用inet_ntop()。
const char *inet_ntop(int af, const void *src, char *dst, socklen_t cnt) :
这个函数,是将类型为af的网络地址结构src,转换成主机序的字符串形式,存放在长度为cnt的字符串中。
这个函数,其实就是返回指向dst的一个指针。如果函数调用错误,返回值是NULL。
下面是例程,有详细的注释。
#include
#include
int main(int argc, char **argv)
{
char *ptr,**pptr;
struct hostent *hptr;
char str[32];
/* 取得命令后第一个参数,即要解析的域名或主机名 */
ptr = argv[1];
/* 调用gethostbyname()。调用结果都存在hptr中 */
if( (hptr = gethostbyname(ptr) ) == NULL )
{
printf("gethostbyname error for host:%s/n", ptr);
return 0; /* 如果调用gethostbyname发生错误,返回1 */
}
/* 将主机的规范名打出来 */
printf("official hostname:%s/n",hptr->h_name);
/* 主机可能有多个别名,将所有别名分别打出来 */
for(pptr = hptr->h_aliases; *pptr != NULL; pptr++)
printf(" alias:%s/n",*pptr);
/* 根据地址类型,将地址打出来 */
switch(hptr->h_addrtype)
{
case AF_INET:
case AF_INET6:
pptr=hptr->h_addr_list;
/* 将刚才得到的所有地址都打出来。其中调用了inet_ntop()函数 */
for(;*pptr!=NULL;pptr++)
printf(" address:%s/n", inet_ntop(hptr->h_addrtype, *pptr, str, sizeof(str)));
break;
default:
printf("unknown address type/n");
break;
}
return 0;
}
*******************************************************************************************************************************
使用gethostbyname_r得到dns信息
在使用前需要看看所使用系统是否有这个函数
在网络开发中 经常出现需要从主机名得到ip地址的情况这时就使用gethostbyname
但是因为gethostbyname返回的是一个指向静态变量的指针不可重入
很可能刚要读时值就被其它线程修改
所以 新的posix中增加了另一个可重入的从主机名(域名)得到DNS的孙数
gethostbyname_r
下面是它用法的简单例子
CODE
#include
#include
#include
#define DUMP(...) printf(__VA_ARGS__)
int main(int argc,char** argv)
- {
| char buf[1024];
| struct hostent hostinfo,*phost;
| int ret;
|
| DUMP("argc:%d\n",argc);
- if(argc <2 ){
2 printf("ERROR:test domainname\n");
2 return 1;
2 }
|
| if(gethostbyname_r(argv[1],&hostinfo,buf,sizeof(buf),&phost,&ret))
| printf("ERROR:gethostbyname(%s) ret:%d,phost:%d\n",argv[1],ret,(int)ph
| ost);
- else{
2 int i;
printf("gethostbyname(%s) success:ret:%d,",argv[1],ret);
2 if(phost)
2 printf("phost(%d):name:%s,addrtype:%d(AF_INET:%d),len:%d,addr[0]:%
2 d,[1]:%d\n",
2 (int)phost,phost->h_name,phost->h_addrtype,AF_INET,
2 phost->h_length,
2 (int)phost->h_addr_list[0],
2 phost->h_addr_list[0] == NULL?0
2 :(int)phost->h_addr_list[1]);
2 for(i = 0;hostinfo.h_aliases[i];i++)
2 printf("host(%d) alias is:%s\n",(int)&hostinfo,hostinfo.h_aliases[
2 i]);
2 for(i = 0;hostinfo.h_addr_list[i];i++)
2 printf("host addr is:%s\n",inet_ntoa(*(struct in_addr*)hostinfo.h_
2 addr_list[i]));
2 }
|
| return 0;
| }
linux socket编程出现信号SIGPIPE,分析及解决
在编写一个仿QQ软件,C/S模式。出现的问题:当客户机关闭时,服务器也随着关闭,纠结很久之后,我gdb了下,出现下面提示信息:
Program received signal SIGPIPE, Broken pipe.
海姹网(网址:http://www.seacha.com),标签:linux socket编程 出现信号SIGPIPE,分析及解决, Socket,signal,SIGPIPE
0x0012e416 in __kernel_vsyscall ()
在网上查了一下出现SIGPIPE的原因:如果尝试send到一个已关闭的 socket上两次,就会出现此信号,也就是用协议TCP的socket编程,服务器是不能知道客户机什么时候已经关闭了socket,导致还在向该已关闭的socket上send,导致SIGPIPE。
而系统默认产生SIGPIPE信号的措施是关闭进程,所以出现了服务器也退出。
下面分析TCP协议的缺陷以至于服务器无法及时判断对方socket已关闭:
具体的分析可以结合TCP的"四次握手"关闭. TCP是全双工的信道, 可以看作两条单工信道, TCP连接两端的两个端点各负责一条.当对端调用close时,虽然本意是关闭整个两条信道,但本端只是收到FIN包.按照TCP协议的语义,表示对端只是关闭了其所负责的那一条单工信道,仍然可以继续接收数据.也就是说, 因为TCP协议的限制,一个端点无法获知对端的socket是调用了close还是shutdown.(此段网上抄来的)
海姹网(网址:http://www.seacha.com),标签:linux socket编程 出现信号SIGPIPE,分析及解决, Socket,signal,SIGPIPE
解决方法:
重新定义遇到SIGPIPE的措施,signal(SIGPIPE, SIG_IGN);具体措施在函数SIG_IGN里面写。
摘自:
send或者write socket遭遇SIGPIPE信号
当服务器close一个连接时,若client端接着发数据。根据TCP协议的规定,会收到一个RST响应,client再往这个服务器发送数据时,系统会发出一个SIGPIPE信号给进程,告诉进程这个连接已经断开了,不要再写了。
又或者当一个进程向某个已经收到RST的socket执行写操作是,内核向该进程发送一个SIGPIPE信号。该信号的缺省学位是终止进程,因此进程必须捕获它以免不情愿的被终止。
根据信号的默认处理规则SIGPIPE信号的默认执行动作是terminate(终止、退出),所以client会退出。若不想客户端退出可以把 SIGPIPE设为SIG_IGN,如:
signal(SIGPIPE, SIG_IGN);
这时SIGPIPE交给了系统处理。
海姹网(网址:http://www.seacha.com),标签:linux socket编程 出现信号SIGPIPE,分析及解决, Socket,signal,SIGPIPE
服务器采用了fork的话,要收集垃圾进程,防止僵尸进程的产生,可以这样处理:
signal(SIGCHLD,SIG_IGN);
交给系统init去回收。
这里子进程就不会产生僵尸进程了。
在linux下写socket的程序的时候,如果尝试send到一个disconnected socket上,就会让底层抛出一个SIGPIPE信号。
这个信号的缺省处理方法是退出进程,大多数时候这都不是我们期望的。因此我们需要重载这个信号的处理方法。调用以下代码,即可安全的屏蔽SIGPIPE:
struct sigaction sa;
sa.sa_handler = SIG_IGN;
sigaction( SIGPIPE, &sa, 0 );
signal设置的信号句柄只能起一次作用,信号被捕获一次后,信号句柄就会被还原成默认值了。
sigaction设置的信号句柄,可以一直有效,值到你再次改变它的设置。
struct sigaction action;
action.sa_handler = handle_pipe;
海姹网(网址:http://www.seacha.com),标签:linux socket编程 出现信号SIGPIPE,分析及解决, Socket,signal,SIGPIPE
sigemptyset(&action.sa_mask);
action.sa_flags = 0;
sigaction(SIGPIPE, &action, NULL);
void handle_pipe(int sig)
{
//不做任何处理即可
}
RST的含义为“复位”,它是TCP在某些错误情况下所发出的一种TCP分节。有三个条件可以产生RST:
1)、 SYN到达某端口但此端口上没有正在监听的服务器。
2)、 TCP想取消一个已有连接
3)、 TCP接收了一个根本不存在的连接上的分节。
1. Connect 函数返回错误ECONNREFUSED:
如果对客户的SYN的响应是RST,则表明该服务器主机在我们指定的端口上没有进程在等待与之连接(例如服务器进程也许没有启动),这称为硬错(hard error),客户一接收到RST,马上就返回错误ECONNREFUSED.
TCP为监听套接口维护两个队列。两个队列之和不超过listen函数第二个参数backlog。
海姹网(网址:http://www.seacha.com),标签:linux socket编程 出现信号SIGPIPE,分析及解决, Socket,signal,SIGPIPE
当一个客户SYN到达时,若两个队列都是满的,TCP就忽略此分节,且不发送RST.这个因为:这种情况是暂时的,客户TCP将重发SYN,期望不久就能在队列中找到空闲条目。要是TCP服务器发送了一个RST,客户connect函数将立即发送一个错误,强制应用进程处理这种情况,而不是让TCP正常的重传机制来处理。还有,客户区别不了这两种情况:作为SYN的响应,意为“此端口上没有服务器”的RST和意为“有服务器在此端口上但其队列满”的 RST.
Posix.1g允许以下两种处理方法:忽略新的SYN,或为此SYN响应一个RST.历史上,所有源自Berkeley的实现都是忽略新的SYN。
2.如果杀掉服务器端处理客户端的子进程,进程退出后,关闭它打开的所有文件描述符,此时,当服务器TCP接收到来自此客户端的数据时,由于先前打开的那个套接字接口的进程已终止,所以以RST响应。
经常遇到的问题:
如果不判断read , write函数的返回值,就不知道服务器是否响应了RST,此时客户端如果向接收了RST的套接口进行写操作时,内核给该进程发一个SIGPIPE信号。此信号的缺省行为就是终止进程,所以,进程必须捕获它以免不情愿地被终止。
海姹网(网址:http://www.seacha.com),标签:linux socket编程 出现信号SIGPIPE,分析及解决, Socket,signal,SIGPIPE
进程不论是捕获了该信号并从其信号处理程序返回,还是不理会该信号,写操作都返回EPIPE错误。
3.服务器主机崩溃后重启
如果服务器主机与客户端建立连接后崩溃,如果此时,客户端向服务器发送数据,而服务器已经崩溃不能响应客户端ACK,客户TCP将持续重传数据分节,试图从服务器上接收一个ACK,如果服务器一直崩溃客户端会发现服务器已经崩溃或目的地不可达,但可能需要比较长的时间;如果服务器在客户端发现崩溃前重启,服务器的TCP丢失了崩溃前的所有连接信息,所以服务器TCP对接收的客户数据分节以RST响应。
二、关于socket的recv:
对于TCP non-blocking socket, recv返回值== -1,但是errno == EAGAIN,此时表示在执行recv时相应的socket buffer中没有数据,应该继续recv。
海姹网(网址:http://www.seacha.com),标签:linux socket编程 出现信号SIGPIPE,分析及解决, Socket,signal,SIGPIPE
【If no messages are available at the socket and O_NONBLOCK is not set on the socket's file descriptor, recv() shall block until a message arrives. If no messages are available at the socket and O_NONBLOCK is set on the socket's file descriptor, recv() shall fail and set errno to [EAGAIN] or [EWOULDBLOCK].】
对于UDP recv 应该一直读取直到recv()==-1 && errno==EAGAIN,表示buffer中数据包被全部读取。
接收数据时常遇到Resource temporarily unavailable的提示,errno代码为11(EAGAIN)。这表明你在非阻塞模式下调用了阻塞操作,在该操作没有完成就返回这个错误,这个错误不会破坏socket的同步,不用管它,下次循环接着recv就可以。对非阻塞socket而言,EAGAIN不是一种错误。在VxWorks和 Windows上,EAGAIN的名字叫做EWOULDBLOCK。其实这算不上错误,只是一种异常而已。
while (res != 0)
{
//len = recv(sockfd, buff, MAXBUF, 0);
海姹网(网址:http://www.seacha.com),标签:linux socket编程 出现信号SIGPIPE,分析及解决, Socket,signal,SIGPIPE
len = recv(sockfd, buff, 5, 0);
if (len < 0 )
{
if(errno == EAGAIN)
{
printf("RE-Len:%d errno EAGAIN\n", len);
continue;
}
if (errno == EINTR)
continue;
perror("recv error\n");
break;
海姹网(网址:http://www.seacha.com),标签:linux socket编程 出现信号SIGPIPE,分析及解决, Socket,signal,SIGPIPE
}
else if (len > 0)
{
printf("Recved:%s, and len is:%d \n", buff, len);
len = send(sockfd, buff, len, 0);
if (len < 0)
{
perror("send error");
return -1;
}
memset(buff, 0, MAXBUF);
continue;
}
海姹网(网址:http://www.seacha.com),标签:linux socket编程 出现信号SIGPIPE,分析及解决, Socket,signal,SIGPIPE
else
{
//==0
printf("Disconnected by peer!\n");
res = 0;
return res;
}
}
外记:
accetp()是慢系统调用,在信号产生时会中断其调用并将errno变量设置为EINTR,此时应重新调用accept()。
所以使用时应这样:
while(1)
{
if ( (connfd = accept(....)) == -1 )
{
海姹网(网址:http://www.seacha.com),标签:linux socket编程 出现信号SIGPIPE,分析及解决, Socket,signal,SIGPIPE
if (errno == EINTR)
continue;
perror("accept()");
exit(1);
}
}
signal 与 sigaction区别:
signal函数每次设置具体的信号处理函数(非SIG_IGN)只能生效一次,每次在进程响应处理信号时,随即将信号处理函数恢复为默认处理方式.所以如果想多次相同方式处理某个信号,通常的做法是,在响应函数开始,再次调用signal设置。
int sig_int(); //My signal handler
...
signal(SIGINT, sig_int);
...
int sig_int()
{
signal(SIGINT, sig_int);
海姹网(网址:http://www.seacha.com),标签:linux socket编程 出现信号SIGPIPE,分析及解决, Socket,signal,SIGPIPE
....
}
这种代码段的一个问题是:在信号发生之后到信号处理程序中调用s i g n a l函数之间有一个时间窗口。在此段时间中,可能发生另一次中断信号。第二个信号会造成执行默认动作,而对中断信号则是终止该进程。这种类型的程序段在大多数情况下会正常工作,使得我们认为它们正确,而实际上却并不是如此。
另一个问题是:在进程不希望某种信号发生时,它不能关闭该信号
sigaction:
1.在信号处理程序被调用时,系统建立的新信号屏蔽字会自动包括正被递送的信号。因此保证了在处理一个
给定的信号时,如果这种信号再次发生,那么它会被阻塞到对前一个信号的处理结束为止
2.响应函数设置后就一直有效,不会重置
3.对除S I G A L R M以外的所有信号都企图设置S A _ R E S TA RT标志,于是被这些信号中断的系统调用(read,write)都能自动再起动。不希望再起动由S I G A L R M信号中断的系统调用的原因是希望对I / O操作可以设置时间限制。所以希望能用相同方式处理信号的多次出现,最好用sigaction.信号只出现并处理一次,可以用signal
服务端关闭已连接客户端,客户端接着发数据产生问题,
1. 当服务器close一个连接时,若client端接着发数据。根据TCP协议的规定,会收到一个RST响应,client再往这个服务器发送数据时,系统会发出一个SIGPIPE信号给进程,告诉进程这个连接已经断开了,不要再写了。
根据信号的默认处理规则SIGPIPE信号的默认执行动作是terminate(终止、退出),所以client会退出。若不想客户端退出可以把SIGPIPE设为SIG_IGN
如: signal(SIGPIPE,SIG_IGN);
这时SIGPIPE交给了系统处理。
2. 客户端write一个已经被服务器端关闭的sock后,返回的错误信息Broken pipe.
1)broken pipe的字面意思是“管道破裂”。broken pipe的原因是该管道的读端被关闭。
2)broken pipe经常发生socket关闭之后(或者其他的描述符关闭之后)的write操作中
3)发生broken pipe错误时,进程收到SIGPIPE信号,默认动作是进程终止。
4)broken pipe最直接的意思是:写入端出现的时候,另一端却休息或退出了,因此造成没有及时取走管道中的数据,从而系统异常退出;
服务器采用了fork的话,要收集垃圾进程,防止僵尸进程的产生,可以这样处理:
signal(SIGCHLD,SIG_IGN); //交给系统init去回收。
这里子进程就不会产生僵尸进程了。
Linux下socket编程write()函数崩溃导致进程退出
问题描述:
当服务器close一个连接时,若client端接着发数据。根据TCP协议的规定,会收到一个RST响应,client再往这个服务器发送数据时,系统会发出一个SIGPIPE信号给进程,告诉进程这个连接已经断开了,不要再写了。
又或者当一个进程向某个已经收到RST的socket执行写操作是,内核向该进程发送一个SIGPIPE信号。该信号的缺省学位是终止进程,因此进程必须捕获它以免不情愿的被终止。
我遇到的情况是客户端socket句柄已关闭,然后服务器像一个已关闭的客户端连接句柄中执行写操作,从而产生了SIGPIPE信号。
问题原因:
根据信号的默认处理规则SIGPIPE信号的默认执行动作是terminate(终止、退出),所以进程会退出。
系统里边定义了三种处理方法:
1)SIG_DFL
2)SIG_IGN
3)SIG_ERR
根据信号的默认处理规则SIGPIPE信号的默认执行动作是terminate(终止、退出),所以进程会退出。若不想客户端退出,需要把SIGPIPE默认执行动作屏蔽。
问题解决:
将SIGPIPE的默认处理方法屏蔽,我找到了两种方法:用signal(SIGCHLD,SIG_IGN)或者重载其处理方法。个人选了后者。两者区别在于signal设置的信号句柄只能起一次作用,信号被捕获一次后,信号句柄就会被还原成默认值了;sigaction设置的信号句柄,可以一直有效,值到你再次改变它的设置。具体代码如下:
struct sigaction action;
action.sa_handler = handle_pipe;
sigemptyset(&action.sa_mask);
action.sa_flags = 0;
sigaction(SIGPIPE, &action, NULL);
void handle_pipe(int sig)
{//不做任何处理即可}
在源文件中要添加signal.h头文件:#include
linux下写socket的程序的时候,如果尝试send到一个disconnected socket上,就会让底层抛出一个SIGPIPE信号。 client端通过 pipe发送信息到server端后,就关闭client端,这时server端,返回信息给 client端时就产生Broken pipe信号了。 对于产生信号,我们可以在产生信号前利用方法 signal(int signum, sighandler_t handler)设置信号的处理。如果没有调用此方法,系统就会调用默认处理方法:中止程序,显示提示信息(就是我们经常遇到的问题)。我们可以调用系统的处理方法,也可以自定义处理方法。对一个已经收到FIN包的socket调用read方法,如果接收缓冲已空,则返回0,这就是常说的表示连接关闭.但第一次对其调用write方法时,如果发送缓冲没问题,会返回正确写入(发送).但发送的报文会导致对端发送RST报文,因为对端的socket已经调用了close,完全关闭,既不发送,也不接收数据.所以,第二次调用write方法(假设在收到RST之后),会生成SIGPIPE信号,导致进程退出.为了避免进程退出,可以捕获SIGPIPE信号,或者忽略它,给它设置SIG_IGN信号处理函数: signal(SIGPIPE, SIG_IGN);这样,第二次调用write方法时,会返回-1,同时errno置为SIGPIPE.程序便能知道对端已经关闭.
signal(SIGPIPE, SIG_IGN)
当服务器close一个连接时,若client端接着发数据。根据TCP协议的规定,会收到一个RST响应,client再往这个服务器发送数据时,系统会发出一个SIGPIPE信号给进程,告诉进程这个连接已经断开了,不要再写了。
根据信号的默认处理规则SIGPIPE信号的默认执行动作是terminate(终止、退出),所以client会退出。若不想客户端退出可以把SIGPIPE设为SIG_IGN
如: signal(SIGPIPE,SIG_IGN);
这时SIGPIPE交给了系统处理。
服务器采用了fork的话,要收集垃圾进程,防止僵尸进程的产生,可以这样处理:
signal(SIGCHLD,SIG_IGN);交给系统init去回收。
这里子进程就不会产生僵尸进程了。
http://hi.baidu.com/__zhuanxin/blog/item/6be6233875b275ec3b87ce6d.html
########################################################################
关于SIGPIPE信号
http://www.360doc.com/content/11/0604/09/4363353_121584610.shtml
我写了一个服务器程序,在Linux下测试,然后用C++写了客户端用千万级别数量的短链接进行压力测试. 但是服务器总是莫名退出,没有core文件.
最后问题确定为, 对一个对端已经关闭的socket调用两次write,第二次将会生成SIGPIPE信号,该信号默认结束进程.
具体的分析可以结合TCP的"四次握手"关闭. TCP是全双工的信道, 可以看作两条单工信道, TCP连接两端的两个端点各负责一条.当对端调用close时,虽然本意是关闭整个两条信道,但本端只是收到FIN包.按照TCP协议的语义,表示对端只是关闭了其所负责的那一条单工信道,仍然可以继续接收数据.也就是说, 因为TCP协议的限制,一个端点无法获知对端的socket是调用了close还是shutdown.
对一个已经收到FIN包的socket调用read方法,如果接收缓冲已空,则返回0,这就是常说的表示连接关闭.但第一次对其调用write方法时,如果发送缓冲没问题,会返回正确写入(发送).但发送的报文会导致对端发送RST报文,因为对端的socket已经调用了close,完全关闭,既不发送,也不接收数据.所以,第二次调用write方法(假设在收到RST之后),会生成SIGPIPE信号,导致进程退出.
为了避免进程退出, 可以捕获SIGPIPE信号,或者忽略它,给它设置SIG_IGN信号处理函数:
signal(SIGPIPE, SIG_IGN);
这样, 第二次调用write方法时,会返回-1,同时errno置为SIGPIPE.程序便能知道对端已经关闭.
在linux下写socket的程序的时候,如果尝试send到一个disconnected socket上,就会让底层抛出一个SIGPIPE信号。
这个信号的缺省处理方法是退出进程,大多数时候这都不是我们期望的。因此我们需要重载这个信号的处理方法。调用以下代码,即可安全的屏蔽SIGPIPE:
signal (SIGPIPE, SIG_IGN);
我的程序产生这个信号的原因是:
client端通过 pipe 发送信息到server端后,就关闭client端,这时server端,返回信息给 client端时就产生Broken pipe信号了,服务器就会被系统结束了。
对于产生信号,我们可以在产生信号前利用方法 signal(int signum, sighandler_t handler) 设置信号的处理。如果没有调用此方法,系统就会调用默认处理方法:中止程序,显示提示信息(就是我们经常遇到的问题)。我们可以调用系统的处理方法,也可以自定义处理方法。
系统里边定义了三种处理方法:
(1)SIG_DFL信号专用的默认动作:
(a)如果默认动作是暂停线程,则该线程的执行被暂时挂起。当线程暂停期间,发送给线程的任何附加信号都不交付,直到该线程开始执行,但是SIGKILL除外。
(b)把挂起信号的信号动作设置成SIG_DFL,且其默认动作是忽略信号 (SIGCHLD)。
(2)SIG_IGN忽略信号
(a)该信号的交付对线程没有影响
(b)系统不允许把SIGKILL或SIGTOP信号的动作设置为SIG_DFL
3)SIG_ERR
项目中我调用了signal(SIGPIPE,SIG_IGN),这样产生 SIGPIPE信号时就不会中止程序,直接把这个信号忽略掉。
当client断开后,如果server连续调用send()发送数据,则linux在第二次调用send()的时候产生SIGPIPE信号(第一次直接返回错误码).而linux系统默认处理SIGPIPE是kill掉该线程,因此导致进程死机
解决办法:
(1)进程在循环调用send()/write()/receive()/read()的地方,必须严格检查返回值,如果发生了错误,必须退出循环,不再发送/读取任何数据
(2)调用signal(SIGPIPE,SIG_IGN)忽略SIGPIPE信号.
只有“写”才会触发SIGPIPE,recv是不可能的。
recv 是读缓存的的数据,数据都接收到了。
做一个很简单的通信模块:服务器端监听服务请求并接收数据;客户端连接服务器段并发送数据。考虑到一种情况:客户端向服务器端连续两次发送数据,而服务器端在accept之后就关闭了连接。
通过在服务器端accept成功之后调用close(fd)模仿这种情形。UNP的5.13节说客户端在第二次发送数据时会接收到第一次发送数据时服务器端返回的RST从而导致内核发出SIGPIPE信号。于是我在客户端程序中使用signal(SIGPIPE, sig_pipe)捕捉SIGPIPE信号,程序调试时证明UNP说得没错,但在运行状态时有时候捕捉不到SIGPIPE信号。
仔细看书,UNP第113面的5.12节中有一小段文字讲RST被客户端收到的时间取决于时序问题,于是猜想第二此调用send函数发送数据时有可能服务器端的RST还未返回。为了验证这个猜想,在第二次发送数据前sleep一下程序,使得RST能在send前返回。测试程序,乖乖,这次都能捕捉到SIPPIPE信号了。
问题是:假如我想100%的捕捉SIGPIPE信号,那么每次的sleep就会影响到程序的效率。
linux编程下signal()函数
(2012-01-10 10:12:25)
转载▼
标签: 杂谈分类:linux
当服务器close一个连接时,若client端接着发数据。根据TCP协议的规定,会收到一个RST响应,client再往这个服务器发送数据时,系统会发出一个SIGPIPE信号给进程,告诉进程这个连接已经断开了,不要再写了。根据信号的默认处理规则SIGPIPE信号的默认执行动作是 terminate(终止、退出),所以client会退出。
若不想客户端退出可以把 SIGPIPE设为SIG_IGN
如: signal(SIGPIPE,SIG_IGN);
这时SIGPIPE交给了系统处理。
服务器采用了fork的话,要收集垃圾进程,防止僵死进程的产生,可以这样处理:
signal(SIGCHLD,SIG_IGN); 交给系统init去回收。
这里子进程就不会产生僵死进程了。
signal(SIGHUP, SIG_IGN);
signal信号函数,第一个参数表示需要处理的信号值(SIGHUP),第二个参数为处理函数或者是一个表示,这里,SIG_IGN表示忽略SIGHUP那个注册的信号。
SIGHUP和控制台操作有关,当控制台被关闭时系统会向拥有控制台sessionID的所有进程发送HUP信号,默认HUP信号的action是 exit,如果远程登陆启动某个服务进程并在程序运行时关闭连接的话会导致服务进程退出,所以一般服务进程都会用nohup工具启动或写成一个 daemon。
unix中进程组织结构为 session包含一个前台进程组及一个或多个后台进程组,一个进程组包含多个进程。
一个session可能会有一个session首进程,而一个session首进程可能会有一个控制终端。
一个进程组可能会有一个进程组首进程。进程组首进程的进程ID与该进程组ID相等。
这儿是可能会有,在一定情况之下是没有的。
与终端交互的进程是前台进程,否则便是后台进程
SIGHUP会在以下3种情况下被发送给相应的进程:
1、终端关闭时,该信号被发送到session首进程以及作为job提交的进程(即用 & 符号提交的进程)
2、session首进程退出时,该信号被发送到该session中的前台进程组中的每一个进程
3、若父进程退出导致进程组成为孤儿进程组,且该进程组中有进程处于停止状态(收到SIGSTOP或SIGTSTP信号),该信号会被发送到该进程组中的每一个进程。
系统对SIGHUP信号的默认处理是终止收到该信号的进程。所以若程序中没有捕捉该信号,当收到该信号时,进程就会退出。
表头文件 #include
功能:
设置某一信号的对应动作
函数原型:
void (*signal(int signum,void(* handler)(int)))(int);
或者:typedef void(*sig_t) ( int ); sig_t signal(int signum,sig_t handler);
参数说明:
第一个参数signum指明了所要处理的信号类型,它可以取除了SIGKILL和SIGSTOP外的任何一种信号。
第二个参数handler描述了与信号关联的动作,它可以取以下三种值:
(1)一个返回值为正数的函数地址 此函数必须在signal()被调用前申明,handler中为这个函数的名字。当接收到一个类型为sig的信号时,就执行handler所指定的函数。这个函数应有如下形式的定义: intfunc(int sig); sig是传递给它的唯一参数。执行了signal()调用后,进程只要接收到类型为sig的信号,不管其正在执行程序的哪一部分,就立即执行func()函数。当func()函数执行结束后,控制权返回进程被中断的那一点继续执行。
(2)SIGIGN 这个符号表示忽略该信号,执行了相应的signal()调用后,进程会忽略类型为sig的信号。
(3)SIGDFL 这个符号表示恢复系统对信号的默认处理。
函数说明: signal()会依参数signum指定的信号编号来设置该信号的处理函数。当指定的信号到达时就会跳转到参数handler指定的函数执行。当一个信号的信号处理函数执行时, 如果进程又接收到了该信号,该信号会自动被储存而不会中断信号处理函数的执行,直到信号处理函数执行完毕再重新调用相应的处理函数。但是如果在信号处理函数执行时进程收到了其它类型的信号,该函数的执行就会被中断。
返回值:返回先前的信号处理函数指针,如果有错误则返回SIG_ERR(-1)。
附加说明:在信号发生跳转到自定的handler处理函数执行后,系统会自动将此处理函数换回原来系统预设的处理方式,如果要改变此操作请改用sigaction()。
下面的情况可以产生Signal:
1. 按下CTRL+C产生SIGINT
2. 硬件中断,如除0,非法内存访问(SIGSEV)等等
3. Kill函数可以对进程发送Signal
4. Kill命令。实际上是对Kill函数的一个包装
5. 软件中断。如当Alarm Clock超时(SIGURG),当Reader中止之后又向管道写数据(SIGPIPE),等等
2 Signals:
Signal Description
SIGABRT由调用abort函数产生,进程非正常退出
SIGALRM 用alarm函数设置的timer超时或setitimer函数设置的interval timer超时
SIGBUS某种特定的硬件异常,通常由内存访问引起
SIGCANCEL 由Solaris Thread Library内部使用,通常不会使用
SIGCHLD 进程Terminate或Stop的时候,SIGCHLD会发送给它的父进程。缺省情况下该Signal会被忽略
SIGCONT当被stop的进程恢复运行的时候,自动发送
SIGEMT和实现相关的硬件异常
SIGFPE数学相关的异常,如被0除,浮点溢出,等等
SIGFREEZE Solaris专用,Hiberate或者Suspended时候发送
SIGHUP 发送给具有Terminal的Controlling Process,当terminal被disconnect时候发送
SIGILL 非法指令异常
SIGINFO BSD signal。由Status Key产生,通常是CTRL+T。发送给所有Foreground Group的进程
SIGINT 由Interrupt Key产生,通常是CTRL+C或者DELETE。发送给所有ForeGround Group的进程
SIGIO 异步IO事件
SIGIOT 实现相关的硬件异常,一般对应SIGABRT
SIGKILL无法处理和忽略。中止某个进程
SIGLWP 由Solaris Thread Libray内部使用
SIGPIPE 在reader中止之后写Pipe的时候发送
SIGPOLL 当某个事件发送给Pollable Device的时候发送
SIGPROF Setitimer指定的Profiling Interval Timer所产生
SIGPWR 和系统相关。和UPS相关。
SIGQUIT 输入Quit Key的时候(CTRL+\)发送给所有Foreground Group的进程
SIGSEGV 非法内存访问
SIGSTKFLT Linux专用,数学协处理器的栈异常
SIGSTOP中止进程。无法处理和忽略。
SIGSYS 非法系统调用
SIGTERM请求中止进程,kill命令缺省发送
SIGTHAW Solaris专用,从Suspend恢复时候发送
SIGTRAP实现相关的硬件异常。一般是调试异常
SIGTSTP Suspend Key,一般是Ctrl+Z。发送给所有Foreground Group的进程
SIGTTIN 当Background Group的进程尝试读取Terminal的时候发送
SIGTTOU 当Background Group的进程尝试写Terminal的时候发送
SIGURG 当out-of-band data接收的时候可能发送
SIGUSR1 用户自定义signal 1
SIGUSR2 用户自定义signal 2
SIGVTALRM setitimer函数设置的Virtual Interval Timer超时的时候
SIGWAITING Solaris Thread Library内部实现专用
SIGWINCH 当Terminal的窗口大小改变的时候,发送给Foreground Group的所有进程
SIGXCPU 当CPU时间限制超时的时候
SIGXFSZ进程超过文件大小限制
SIGXRESSolaris专用,进程超过资源限制的时候发送
1、不要使用低级的或者STDIO.H的IO函数 2、不要使用对操作 3、不要进行系统调用 4、不是浮点信号的时候不要用longjmp 5、singal函数是由ISO C定义的。因为ISO C不涉及多进程,进程组以及终端I/O等,所以他对信号的定义非常含糊,以至于对UNIX系统而言几乎毫无用处。 备注:因为singal的语义于现实有关,所以最好使用sigaction函数替代本函数。
setsocketopt getsocketopt比较全的参数说明
分类: Linux2011-08-20 12:52 1709人阅读评论(0)收藏举报
socketsocketscredentialslinuxinterfaceinteger
These socket options can be set by using setsockopt(2) and read withgetsockopt(2) with the socket level set toSOL_SOCKET for all sockets:
SO_ACCEPTCONN
Returns a value indicating whether or not this socket has been marked to accept connections withlisten(). The value 0 indicates that this is not a listening socket, the value 1 indicates that this is a listening socket. Can only be read withgetsockopt().
SO_BSDCOMPAT
Enable BSD bug-to-bug compatibility. This is used by the UDP protocol module in Linux 2.0 and 2.2. If enabled ICMP errors received for a UDP socket will not be passed to the user program. In later kernel versions, support for this option has been phased out: Linux 2.4 silently ignores it, and Linux 2.6 generates a kernel warning (printk()) if a program uses this option. Linux 2.0 also enabled BSD bug-to-bug compatibility options (random header changing, skipping of the broadcast flag) for raw sockets with this option, but that was removed in Linux 2.2.
SO_BINDTODEVICE
Bind this socket to a particular device like "eth0", as specified in the passed interface name. If the name is an empty string or the option length is zero, the socket device binding is removed. The passed option is a variable-length null terminated interface name string with the maximum size of IFNAMSIZ. If a socket is bound to an interface, only packets received from that particular interface are processed by the socket. Note that this only works for some socket types, particularlyAF_INET sockets. It is not supported for packet sockets (use normalbind(8) there).
SO_BROADCAST
Set or get the broadcast flag. When enabled, datagram sockets receive packets sent to a broadcast address and they are allowed to send packets to a broadcast address. This option has no effect on stream-oriented sockets.
SO_DEBUG
Enable socket debugging. Only allowed for processes with the CAP_NET_ADMIN capability or an effective user ID of 0.
SO_ERROR
Get and clear the pending socket error. Only valid as a getsockopt(). Expects an integer.
SO_DONTROUTE
Don't send via a gateway, only send to directly connected hosts. The same effect can be achieved by setting theMSG_DONTROUTE flag on a socketsend(2) operation. Expects an integer boolean flag.
SO_KEEPALIVE
Enable sending of keep-alive messages on connection-oriented sockets. Expects an integer boolean flag.
SO_LINGER
Sets or gets the SO_LINGER option. The argument is a linger structure.
struct linger {
int l_onoff; /* linger active */
int l_linger; /* how many seconds to linger for */
};
When enabled, a close(2) orshutdown(2) will not return until all queued messages for the socket have been successfully sent or the linger timeout has been reached. Otherwise, the call returns immediately and the closing is done in the background. When the socket is closed as part ofexit(2), it always lingers in the background.
SO_OOBINLINE
If this option is enabled, out-of-band data is directly placed into the receive data stream. Otherwise out-of-band data is only passed when theMSG_OOB flag is set during receiving.
SO_PASSCRED
Enable or disable the receiving of the SCM_CREDENTIALS control message. For more information seeunix(7).
SO_PEERCRED
Return the credentials of the foreign process connected to this socket. This is only possible for connectedPF_UNIX stream sockets andPF_UNIX stream and datagram socket pairs created usingsocketpair(2); seeunix(7). The returned credentials are those that were in effect at the time of the call toconnect(2) orsocketpair(2). Argument is a ucred structure. Only valid as a getsockopt().
SO_PRIORITY
Set the protocol-defined priority for all packets to be sent on this socket. Linux uses this value to order the networking queues: packets with a higher priority may be processed first depending on the selected device queueing discipline. Forip(7), this also sets the IP type-of-service (TOS) field for outgoing packets. Setting a priority outside the range 0 to 6 requires theCAP_NET_ADMIN capability.
SO_RCVLOWAT and SO_SNDLOWAT
Specify the minimum number of bytes in the buffer until the socket layer will pass the data to the protocol (SO_SNDLOWAT) or the user on receiving (SO_RCVLOWAT). These two values are initialised to 1.SO_SNDLOWAT is not changeable on Linux (setsockopt fails with the error ENOPROTOOPT). SO_RCVLOWAT is changeable only since Linux 2.4. Theselect(2) andpoll(2) system calls currently do not respect theSO_RCVLOWAT setting on Linux, and mark a socket readable when even a single byte of data is available. A subsequent read from the socket will block untilSO_RCVLOWAT bytes are available.
SO_RCVTIMEO and SO_SNDTIMEO
Specify the receiving or sending timeouts until reporting an error. The parameter is astruct timeval. If an input or output function blocks for this period of time, and data has been sent or received, the return value of that function will be the amount of data transferred; if no data has been transferred and the timeout has been reached then -1 is returned witherrno set to EAGAIN or EWOULDBLOCK just as if the socket was specified to be nonblocking. If the timeout is set to zero (the default) then the operation will never timeout.
SO_RCVBUF
Sets or gets the maximum socket receive buffer in bytes. The kernel doubles this value (to allow space for bookkeeping overhead) when it is set usingsetsockopt(), and this doubled value is returned bygetsockopt(). The default value is set by thermem_default sysctl and the maximum allowed value is set by thermem_max sysctl. The minimum (doubled) value for this option is 256.
SO_RCVBUFFORCE (since Linux 2.6.14)
Using this socket option, a privileged (CAP_NET_ADMIN) process can perform the same task asSO_RCVBUF, but thermem_max limit can be overridden.
SO_REUSEADDR
Indicates that the rules used in validating addresses supplied in a bind(2) call should allow reuse of local addresses. ForPF_INET sockets this means that a socket may bind, except when there is an active listening socket bound to the address. When the listening socket is bound toINADDR_ANY with a specific port then it is not possible to bind to this port for any local address.
SO_SNDBUF
Sets or gets the maximum socket send buffer in bytes. The kernel doubles this value (to allow space for bookkeeping overhead) when it is set usingsetsockopt(), and this doubled value is returned bygetsockopt(). The default value is set by thewmem_default sysctl and the maximum allowed value is set by thewmem_max sysctl. The minimum (doubled) value for this option is 2048.
SO_SNDBUFFORCE (since Linux 2.6.14)
Using this socket option, a privileged (CAP_NET_ADMIN) process can perform the same task asSO_SNDBUF, but thewmem_max limit can be overridden.
SO_TIMESTAMP
Enable or disable the receiving of the SO_TIMESTAMP control message. The timestamp control message is sent with levelSOL_SOCKET and thecmsg_data field is a struct timeval indicating the reception time of the last packet passed to the user in this call. Seecmsg(3) for details on control messages.
SO_TYPE
Gets the socket type as an integer (like SOCK_STREAM). Can only be read withgetsockopt().
Linux下高并发socket最大连接数所受的各种限制
2011-07-19 08:10 40458人阅读评论(15)收藏 举报
linuxsockettcplinux内核网络通讯
1、修改用户进程可打开文件数限制
在Linux平台上,无论编写客户端程序还是服务端程序,在进行高并发TCP连接处理时,最高的并发数量都要受到系统对用户单一进程同时可打开文件数量的限制(这是因为系统为每个TCP连接都要创建一个socket句柄,每个socket句柄同时也是一个文件句柄)。可使用ulimit命令查看系统允许当前用户进程打开的文件数限制:
[speng@as4 ~]$ ulimit -n
1024
这表示当前用户的每个进程最多允许同时打开1024个文件,这1024个文件中还得除去每个进程必然打开的标准输入,标准输出,标准错误,服务器监听 socket,进程间通讯的unix域socket等文件,那么剩下的可用于客户端socket连接的文件数就只有大概1024-10=1014个左右。也就是说缺省情况下,基于Linux的通讯程序最多允许同时1014个TCP并发连接。
对于想支持更高数量的TCP并发连接的通讯处理程序,就必须修改Linux对当前用户的进程同时打开的文件数量的软限制(soft limit)和硬限制(hardlimit)。其中软限制是指Linux在当前系统能够承受的范围内进一步限制用户同时打开的文件数;硬限制则是根据系统硬件资源状况(主要是系统内存)计算出来的系统最多可同时打开的文件数量。通常软限制小于或等于硬限制。
修改上述限制的最简单的办法就是使用ulimit命令:
[speng@as4 ~]$ ulimit -n
上述命令中,在中指定要设置的单一进程允许打开的最大文件数。如果系统回显类似于“Operation notpermitted”之类的话,说明上述限制修改失败,实际上是因为在中指定的数值超过了Linux系统对该用户打开文件数的软限制或硬限制。因此,就需要修改Linux系统对用户的关于打开文件数的软限制和硬限制。
第一步,修改/etc/security/limits.conf文件,在文件中添加如下行:
speng soft nofile 10240
speng hard nofile 10240
其中speng指定了要修改哪个用户的打开文件数限制,可用’*'号表示修改所有用户的限制;soft或hard指定要修改软限制还是硬限制;10240则指定了想要修改的新的限制值,即最大打开文件数(请注意软限制值要小于或等于硬限制)。修改完后保存文件。
第二步,修改/etc/pam.d/login文件,在文件中添加如下行:
session required /lib/security/pam_limits.so
这是告诉Linux在用户完成系统登录后,应该调用pam_limits.so模块来设置系统对该用户可使用的各种资源数量的最大限制(包括用户可打开的最大文件数限制),而pam_limits.so模块就会从/etc/security/limits.conf文件中读取配置来设置这些限制值。修改完后保存此文件。
第三步,查看Linux系统级的最大打开文件数限制,使用如下命令:
[speng@as4 ~]$ cat /proc/sys/fs/file-max
12158
这表明这台Linux系统最多允许同时打开(即包含所有用户打开文件数总和)12158个文件,是Linux系统级硬限制,所有用户级的打开文件数限制都不应超过这个数值。通常这个系统级硬限制是Linux系统在启动时根据系统硬件资源状况计算出来的最佳的最大同时打开文件数限制,如果没有特殊需要,不应该修改此限制,除非想为用户级打开文件数限制设置超过此限制的值。修改此硬限制的方法是修改/etc/rc.local脚本,在脚本中添加如下行:
echo 22158 > /proc/sys/fs/file-max
这是让Linux在启动完成后强行将系统级打开文件数硬限制设置为22158。修改完后保存此文件。
完成上述步骤后重启系统,一般情况下就可以将Linux系统对指定用户的单一进程允许同时打开的最大文件数限制设为指定的数值。如果重启后用 ulimit-n命令查看用户可打开文件数限制仍然低于上述步骤中设置的最大值,这可能是因为在用户登录脚本/etc/profile中使用ulimit -n命令已经将用户可同时打开的文件数做了限制。由于通过ulimit-n修改系统对用户可同时打开文件的最大数限制时,新修改的值只能小于或等于上次 ulimit-n设置的值,因此想用此命令增大这个限制值是不可能的。所以,如果有上述问题存在,就只能去打开/etc/profile脚本文件,在文件中查找是否使用了ulimit-n限制了用户可同时打开的最大文件数量,如果找到,则删除这行命令,或者将其设置的值改为合适的值,然后保存文件,用户退出并重新登录系统即可。
通过上述步骤,就为支持高并发TCP连接处理的通讯处理程序解除关于打开文件数量方面的系统限制。
2、修改网络内核对TCP连接的有关限制(参考对比下篇文章“优化内核参数”)
在Linux上编写支持高并发TCP连接的客户端通讯处理程序时,有时会发现尽管已经解除了系统对用户同时打开文件数的限制,但仍会出现并发TCP连接数增加到一定数量时,再也无法成功建立新的TCP连接的现象。出现这种现在的原因有多种。
第一种原因可能是因为Linux网络内核对本地端口号范围有限制。此时,进一步分析为什么无法建立TCP连接,会发现问题出在connect()调用返回失败,查看系统错误提示消息是“Can’t assign requestedaddress”。同时,如果在此时用tcpdump工具监视网络,会发现根本没有TCP连接时客户端发SYN包的网络流量。这些情况说明问题在于本地Linux系统内核中有限制。其实,问题的根本原因在于Linux内核的TCP/IP协议实现模块对系统中所有的客户端TCP连接对应的本地端口号的范围进行了限制(例如,内核限制本地端口号的范围为1024~32768之间)。当系统中某一时刻同时存在太多的TCP客户端连接时,由于每个TCP客户端连接都要占用一个唯一的本地端口号(此端口号在系统的本地端口号范围限制中),如果现有的TCP客户端连接已将所有的本地端口号占满,则此时就无法为新的TCP客户端连接分配一个本地端口号了,因此系统会在这种情况下在connect()调用中返回失败,并将错误提示消息设为“Can’t assignrequested address”。有关这些控制逻辑可以查看Linux内核源代码,以linux2.6内核为例,可以查看tcp_ipv4.c文件中如下函数:
static int tcp_v4_hash_connect(struct sock *sk)
请注意上述函数中对变量sysctl_local_port_range的访问控制。变量sysctl_local_port_range的初始化则是在tcp.c文件中的如下函数中设置:
void __init tcp_init(void)
内核编译时默认设置的本地端口号范围可能太小,因此需要修改此本地端口范围限制。
第一步,修改/etc/sysctl.conf文件,在文件中添加如下行:
net.ipv4.ip_local_port_range = 1024 65000
这表明将系统对本地端口范围限制设置为1024~65000之间。请注意,本地端口范围的最小值必须大于或等于1024;而端口范围的最大值则应小于或等于65535。修改完后保存此文件。
第二步,执行sysctl命令:
[speng@as4 ~]$ sysctl -p
如果系统没有错误提示,就表明新的本地端口范围设置成功。如果按上述端口范围进行设置,则理论上单独一个进程最多可以同时建立60000多个TCP客户端连接。
第二种无法建立TCP连接的原因可能是因为Linux网络内核的IP_TABLE防火墙对最大跟踪的TCP连接数有限制。此时程序会表现为在 connect()调用中阻塞,如同死机,如果用tcpdump工具监视网络,也会发现根本没有TCP连接时客户端发SYN包的网络流量。由于 IP_TABLE防火墙在内核中会对每个TCP连接的状态进行跟踪,跟踪信息将会放在位于内核内存中的conntrackdatabase中,这个数据库的大小有限,当系统中存在过多的TCP连接时,数据库容量不足,IP_TABLE无法为新的TCP连接建立跟踪信息,于是表现为在connect()调用中阻塞。此时就必须修改内核对最大跟踪的TCP连接数的限制,方法同修改内核对本地端口号范围的限制是类似的:
第一步,修改/etc/sysctl.conf文件,在文件中添加如下行:
net.ipv4.ip_conntrack_max = 10240
这表明将系统对最大跟踪的TCP连接数限制设置为10240。请注意,此限制值要尽量小,以节省对内核内存的占用。
第二步,执行sysctl命令:
[speng@as4 ~]$ sysctl -p
如果系统没有错误提示,就表明系统对新的最大跟踪的TCP连接数限制修改成功。如果按上述参数进行设置,则理论上单独一个进程最多可以同时建立10000多个TCP客户端连接。
3、使用支持高并发网络I/O的编程技术
在Linux上编写高并发TCP连接应用程序时,必须使用合适的网络I/O技术和I/O事件分派机制。
可用的I/O技术有同步I/O,非阻塞式同步I/O(也称反应式I/O),以及异步I/O。在高TCP并发的情形下,如果使用同步I/O,这会严重阻塞程序的运转,除非为每个TCP连接的I/O创建一个线程。但是,过多的线程又会因系统对线程的调度造成巨大开销。因此,在高TCP并发的情形下使用同步 I/O是不可取的,这时可以考虑使用非阻塞式同步I/O或异步I/O。非阻塞式同步I/O的技术包括使用select(),poll(),epoll等机制。异步I/O的技术就是使用AIO。
从I/O事件分派机制来看,使用select()是不合适的,因为它所支持的并发连接数有限(通常在1024个以内)。如果考虑性能,poll()也是不合适的,尽管它可以支持的较高的TCP并发数,但是由于其采用“轮询”机制,当并发数较高时,其运行效率相当低,并可能存在I/O事件分派不均,导致部分TCP连接上的I/O出现“饥饿”现象。而如果使用epoll或AIO,则没有上述问题(早期Linux内核的AIO技术实现是通过在内核中为每个 I/O请求创建一个线程来实现的,这种实现机制在高并发TCP连接的情形下使用其实也有严重的性能问题。但在最新的Linux内核中,AIO的实现已经得到改进)。
综上所述,在开发支持高并发TCP连接的Linux应用程序时,应尽量使用epoll或AIO技术来实现并发的TCP连接上的I/O控制,这将为提升程序对高并发TCP连接的支持提供有效的I/O保证。
内核参数sysctl.conf的优化
/etc/sysctl.conf 是用来控制linux网络的配置文件,对于依赖网络的程序(如web服务器和cache服务器)非常重要,RHEL默认提供的最好调整。
推荐配置(把原/etc/sysctl.conf内容清掉,把下面内容复制进去):
net.ipv4.ip_local_port_range = 1024 65536
net.core.rmem_max=16777216
net.core.wmem_max=16777216
net.ipv4.tcp_rmem=4096 87380 16777216
net.ipv4.tcp_wmem=4096 65536 16777216
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_window_scaling = 0
net.ipv4.tcp_sack = 0
net.core.netdev_max_backlog = 30000
net.ipv4.tcp_no_metrics_save=1
net.core.somaxconn = 262144
net.ipv4.tcp_syncookies = 0
net.ipv4.tcp_max_orphans = 262144
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_syn_retries = 2
这个配置参考于cache服务器varnish的推荐配置和SunOne服务器系统优化的推荐配置。
varnish调优推荐配置的地址为:http://varnish.projects.linpro.no/wiki/Performance
不过varnish推荐的配置是有问题的,实际运行表明“net.ipv4.tcp_fin_timeout = 3”的配置会导致页面经常打不开;并且当网友使用的是IE6浏览器时,访问网站一段时间后,所有网页都会打不开,重启浏览器后正常。可能是国外的网速快吧,我们国情决定需要调整“net.ipv4.tcp_fin_timeout = 10”,在10s的情况下,一切正常(实际运行结论)。
修改完毕后,执行:
/sbin/sysctl -p /etc/sysctl.conf
/sbin/sysctl -w net.ipv4.route.flush=1
命令生效。为了保险起见,也可以reboot系统。
调整文件数:
linux系统优化完网络必须调高系统允许打开的文件数才能支持大的并发,默认1024是远远不够的。
执行命令:
Shell代码
echo ulimit -HSn 65536 >> /etc/rc.local
echo ulimit -HSn 65536 >>/root/.bash_profile
ulimit -HSn 65536
非阻塞connect
步骤1:设置非阻塞,启动连接
实现非阻塞 connect ,首先把 sockfd设置成非阻塞的。这样调用 connect可以立刻返回,根据返回值和 errno处理三种情况:
(1) 如果返回 0,表示 connect成功。
(2) 如果返回值小于 0, errno为 EINPROGRESS, 表示连接建立已经启动但是尚未完成。这是期望的结果,不是真正的错误。
(3) 如果返回值小于0,errno不是 EINPROGRESS,则连接出错了。
步骤2:判断可读和可写
然后把 sockfd 加入 select 的读写监听集合,通过 select判断 sockfd
是否可写,处理三种情况:
(1) 如果连接建立好了,对方没有数据到达,那么 sockfd是可写的
(2) 如果在 select之前,连接就建立好了,而且对方的数据已到达,那么 sockfd是可读和可写的。
(3) 如果连接发生错误,sockfd也是可读和可写的。
判断 connect 是否成功,就得区别 (2) 和 (3),这两种情况下 sockfd都是
可读和可写的,区分的方法是,调用 getsockopt检查是否出错。
步骤3:使用 getsockopt函数检查错误
getsockopt(sockfd, SOL_SOCKET, SO_ERROR, &error, &len)
在 sockfd 都是可读和可写的情况下,我们使用 getsockopt来检查连接
是否出错。但这里有一个可移植性的问题。
如果发生错误,getsockopt源自 Berkeley 的实现将在变量 error 中
返回错误,getsockopt本身返回0;然而 Solaris却让 getsockopt 返回 -1,
并把错误保存在 errno 变量中。所以在判断是否有错误的时候,要处理这两种情况。
代码:
- int conn_nonb(int sockfd, const struct sockaddr_in *saptr, socklen_t salen, int nsec)
- {
- int flags, n, error, code;
- socklen_t len;
- fd_set wset;
- struct timeval tval;
- flags = fcntl(sockfd, F_GETFL, 0);
- fcntl(sockfd, F_SETFL, flags | O_NONBLOCK);
- error = 0;
- if ((n == connect(sockfd, saptr, salen)) == 0) {
- goto done;
- } else if (n < 0 && errno != EINPROGRESS){
- return (-1);
- }
- /* Do whatever we want while the connect is taking place */
- FD_ZERO(&wset);
- FD_SET(sockfd, &wset);
- tval.tv_sec = nsec;
- tval.tv_usec = 0;
- if ((n = select(sockfd+1, NULL, &wset,
- NULL, nsec ? &tval : NULL)) == 0) {
- close(sockfd); /* timeout */
- errno = ETIMEDOUT;
- return (-1);
- }
- if (FD_ISSET(sockfd, &wset)) {
- len = sizeof(error);
- code = getsockopt(sockfd, SOL_SOCKET, SO_ERROR, &error, &len);
- /* 如果发生错误,Solaris实现的getsockopt返回-1,
- * 把pending error设置给errno. Berkeley实现的
- * getsockopt返回0, pending error返回给error.
- * 我们需要处理这两种情况 */
- if (code < 0 || error) {
- close(sockfd);
- if (error)
- errno = error;
- return (-1);
- }
- } else {
- fprintf(stderr, "select error: sockfd not set");
- exit(0);
- }
- done:
- fcntl(sockfd, F_SETFL, flags); /* restore file status flags */
- return (0);
- }
linux下使用TCP存活(keepalive)定时器
2009-10-13 21:42:34
标签:linux 休闲 职场 keepalive
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://machael.blog.51cto.com/829462/211989
一、什么是keepalive定时器?[1]
在一个空闲的(idle)TCP连接上,没有任何的数据流,许多TCP/IP的初学者都对此感到惊奇。也就是说,如果TCP连接两端没有任何一个进程在向对方发送数据,那么在这两个TCP模块之间没有任何的数据交换。你可能在其它的网络协议中发现有轮询(polling),但在TCP中它不存在。言外之意就是我们只要启动一个客户端进程,同服务器建立了TCP连接,不管你离开几小时,几天,几星期或是几个月,连接依旧存在。中间的路由器可能崩溃或者重启,电话线可能go down或者back up,只要连接两端的主机没有重启,连接依旧保持建立。
这就可以认为不管是客户端的还是服务器端的应用程序都没有应用程序级(application-level)的定时器来探测连接的不活动状态(inactivity),从而引起任何一个应用程序的终止。然而有的时候,服务器需要知道客户端主机是否已崩溃并且关闭,或者崩溃但重启。许多实现提供了存活定时器来完成这个任务。
存活定时器是一个包含争议的特征。许多人认为,即使需要这个特征,这种对对方的轮询也应该由应用程序来完成,而不是由TCP中实现。此外,如果两个终端系统之间的某个中间网络上有连接的暂时中断,那么存活选项(option)就能够引起两个进程间一个良好连接的终止。例如,如果正好在某个中间路由器崩溃、重启的时候发送存活探测,TCP就将会认为客户端主机已经崩溃,但事实并非如此。
存活(keepalive)并不是TCP规范的一部分。在Host Requirements RFC罗列有不使用它的三个理由:(1)在短暂的故障期间,它们可能引起一个良好连接(good connection)被释放(dropped),(2)它们消费了不必要的宽带,(3)在以数据包计费的互联网上它们(额外)花费金钱。然而,在许多的实现中提供了存活定时器。
一些服务器应用程序可能代表客户端占用资源,它们需要知道客户端主机是否崩溃。存活定时器可以为这些应用程序提供探测服务。Telnet服务器和Rlogin服务器的许多版本都默认提供存活选项。
个人计算机用户使用TCP/IP协议通过Telnet登录一台主机,这是能够说明需要使用存活定时器的一个常用例子。如果某个用户在使用结束时只是关掉了电源,而没有注销(log off),那么他就留下了一个半打开(half-open)的连接。在图18.16,我们看到如何在一个半打开连接上通过发送数据,得到一个复位(reset)返回,但那是在客户端,是由客户端发送的数据。如果客户端消失,留给了服务器端半打开的连接,并且服务器又在等待客户端的数据,那么等待将永远持续下去。存活特征的目的就是在服务器端检测这种半打开连接。
二、keepalive如何工作?[1]
在此描述中,我们称使用存活选项的那一段为服务器,另一端为客户端。也可以在客户端设置该选项,且没有不允许这样做的理由,但通常设置在服务器。如果连接两端都需要探测对方是否消失,那么就可以在两端同时设置(比如NFS)。
若在一个给定连接上,两小时之内无任何活动,服务器便向客户端发送一个探测段。(我们将在下面的例子中看到探测段的样子。)客户端主机必须是下列四种状态之一:
1) 客户端主机依旧活跃(up)运行,并且从服务器可到达。从客户端TCP的正常响应,服务器知道对方仍然活跃。服务器的TCP为接下来的两小时复位存活定时器,如果在这两个小时到期之前,连接上发生应用程序的通信,则定时器重新为往下的两小时复位,并且接着交换数据。
2) 客户端已经崩溃,或者已经关闭(down),或者正在重启过程中。在这两种情况下,它的TCP都不会响应。服务器没有收到对其发出探测的响应,并且在75秒之后超时。服务器将总共发送10个这样的探测,每个探测75秒。如果没有收到一个响应,它就认为客户端主机已经关闭并终止连接。
3) 客户端曾经崩溃,但已经重启。这种情况下,服务器将会收到对其存活探测的响应,但该响应是一个复位,从而引起服务器对连接的终止。
4) 客户端主机活跃运行,但从服务器不可到达。这与状态2类似,因为TCP无法区别它们两个。它所能表明的仅是未收到对其探测的回复。
服务器不必担心客户端主机被关闭然后重启的情况(这里指的是操作员执行的正常关闭,而不是主机的崩溃)。当系统被操作员关闭时,所有的应用程序进程(也就是客户端进程)都将被终止,客户端TCP会在连接上发送一个FIN。收到这个FIN后,服务器TCP向服务器进程报告一个文件结束,以允许服务器检测这种状态。
在第一种状态下,服务器应用程序不知道存活探测是否发生。凡事都是由TCP层处理的,存活探测对应用程序透明,直到后面2,3,4三种状态发生。在这三种状态下,通过服务器的TCP,返回给服务器应用程序错误信息。(通常服务器向网络发出一个读请求,等待客户端的数据。如果存活特征返回一个错误信息,则将该信息作为读操作的返回值返回给服务器。)在状态2,错误信息类似于“连接超时”。状态3则为“连接被对方复位”。第四种状态看起来像连接超时,或者根据是否收到与该连接相关的ICMP错误信息,而可能返回其它的错误信息。
三、在Linux中如何使用keepalive?[2]
Linux has built-in support for keepalive. You need to enable TCP/IP networking in order to use it. You also need procfs support andsysctl support to be able to configure the kernel parameters at runtime.
The procedures involving keepalive use three user-driven variables:
tcp_keepalive_time
the interval between the last data packet sent (simple ACKs are not considered data) and the first keepalive probe; after the connection is marked to need keepalive, this counter is not used any further
tcp_keepalive_intvl
the interval between subsequential keepalive probes, regardless of what the connection has exchanged in the meantime
tcp_keepalive_probes
the number of unacknowledged probes to send before considering the connection dead and notifying the application layer
Remember that keepalive support, even if configured in the kernel, is not the default behavior in Linux. Programs must request keepalive control for their sockets using the setsockopt interface. There are relatively few programs implementing keepalive, but you can easily add keepalive support for most of them following the instructions.
上面一段话已经说得很明白,linux内核包含对keepalive的支持。其中使用了三个参数:tcp_keepalive_time(开启keepalive的闲置时长)tcp_keepalive_intvl(keepalive探测包的发送间隔) 和tcp_keepalive_probes (如果对方不予应答,探测包的发送次数);如何配置这三个参数呢?
There are two ways to configure keepalive parameters inside the kernel via userspace commands:
- procfs interface
- sysctl interface
We mainly discuss how this is accomplished on the procfs interface because it's the most used, recommended and the easiest to understand. The sysctl interface, particularly regarding the sysctl(2) syscall and not the sysctl(8) tool, is only here for the purpose of background knowledge.
The procfs interface
This interface requires both sysctl and procfs to be built into the kernel, and procfs mounted somewhere in the filesystem (usually on/proc, as in the examples below). You can read the values for the actual parameters by "catting" files in /proc/sys/net/ipv4/directory:
# cat /proc/sys/net/ipv4/tcp_keepalive_time
7200
# cat /proc/sys/net/ipv4/tcp_keepalive_intvl
75
# cat /proc/sys/net/ipv4/tcp_keepalive_probes
9
The first two parameters are expressed in seconds, and the last is the pure number. This means that the keepalive routines wait for two hours (7200 secs) before sending the first keepalive probe, and then resend it every 75 seconds. If no ACK response is received for nine consecutive times, the connection is marked as broken.
Modifying this value is straightforward: you need to write new values into the files. Suppose you decide to configure the host so that keepalive starts after ten minutes of channel inactivity, and then send probes in intervals of one minute. Because of the high instability of our network trunk and the low value of the interval, suppose you also want to increase the number of probes to 20.
Here's how we would change the settings:
# echo 600 > /proc/sys/net/ipv4/tcp_keepalive_time
# echo 60 > /proc/sys/net/ipv4/tcp_keepalive_intvl
# echo 20 > /proc/sys/net/ipv4/tcp_keepalive_probes
To be sure that all succeeds, recheck the files and confirm these new values are showing in place of the old ones.
这样,上面的三个参数配置完毕。使这些参数重启时保持不变的方法请阅读参考文献[2]。
四、在程序中如何使用keepalive?[2]-[4]
All you need to enable keepalive for a specific socket is to set the specific socket option on the socket itself. The prototype of the function is as follows:
int setsockopt(int s, int level, int optname,
const void *optval, socklen_t optlen)
The first parameter is the socket, previously created with the socket(2); the second one must be SOL_SOCKET, and the third must beSO_KEEPALIVE . The fourth parameter must be a boolean integer value, indicating that we want to enable the option, while the last is the size of the value passed before.
According to the manpage, 0 is returned upon success, and -1 is returned on error (and errno is properly set).
There are also three other socket options you can set for keepalive when you write your application. They all use the SOL_TCP level instead of SOL_SOCKET, and they override system-wide variables only for the current socket. If you read without writing first, the current system-wide parameters will be returned.
TCP_KEEPCNT: overrides tcp_keepalive_probes
TCP_KEEPIDLE: overrides tcp_keepalive_time
TCP_KEEPINTVL: overrides tcp_keepalive_intvlint keepAlive = 1; // 开启keepalive属性
我们看到keepalive是一个开关选项,可以通过函数来使能。具体地说,可以使用以下代码:
setsockopt(rs, SOL_SOCKET, SO_KEEPALIVE, (void *)&keepAlive, sizeof(keepAlive));
上面英文资料中提到的第二个参数可以取为SOL_TCP,以设置keepalive的三个参数(具体代码参考文献[3]),在程序中实现需要头文件“netinet/tcp.h”。当然,在实际编程时也可以采用系统调用的方式配置的keepalive参数。
关于setsockopt的其他参数可以参考文献[4]。
五、如何判断TCP连接是否断开?[3]
当tcp检测到对端socket不再可用时(不能发出探测包,或探测包没有收到ACK的响应包),select会返回socket可读,并且在recv时返回-1,同时置上errno为ETIMEDOUT。