级联分类器训练过程(步骤)
本文借助百度翻译,翻译自:https://docs.opencv.org/master/dc/d88/tutorial_traincascade.html
由于本人英语水平有限,翻译有不通顺的地方请参考OpenCV官网,请谅解。正文详情如下:
介绍
使用改进的级联弱分类器包括两个主要阶段:训练阶段和检测阶段。检测阶段使用HAAR或基于LBP的模型,在对象检测教程(object detection tutorial,地址:https://docs.opencv.org/master/db/d28/tutorial_cascade_classifier.html)中描述。该文档概述了训练自己的弱分类器级联的功能。本指南将贯穿不同的阶段:收集培训数据,准备培训数据和执行实际模型培训。
为了支持本教程,将使用几个官方OpenCV应用程序: opencv_createsamples, opencv_annotation, opencv_traincascade 和opencv_visualisation.
重要说明
- 如果你遇到任何教程提到旧的openocv-haartraining工具(它被弃用并且仍然使用OpenCV1.x接口),那么请忽略该教程,并坚持opencv-tracecascade工具。这个工具是一个新的版本,根据OpenCV 2.x 和3.x的API用C++编写。opencv_traincascade支持Haar样小波特征[191 ]和LBP(局部二进制模式)[108 ]特征。LBP的特征产生整数精度与Haar特征相比,产生了浮点精度,因此LBP的训练和检测比HAAR特征要快几倍。对于LBP和Haar检测质量,主要取决于所使用的训练数据和训练参数的选择。在训练时间的百分比内训练一个基于LBP的分类器可以提供几乎与Haar基分类器相同的质量。
- 较新的级联分类器检测接口从OpenCV 2.x和OpenCV 3.x(cv::CascadeClassifier)支持与旧的和新的模型格式一起工作。opencv_traincascade甚至可以保存(导出)一个经过训练的级联,如果由于某种原因,你使用旧接口卡住。至少训练模型可以在最稳定的接口中完成。
- opencv_traincascade应用程序可以使用TBB进行多线程处理。要在多核模式下使用OpenCV,必须建立TBB支持。
训练数据的准备
为了训练一个增强的弱分类器级联,我们需要一组正样本(包含要检测的实际对象)和一组负面图像(包含所有你不想检测到的)。负样本的集合必须手动准备,而正样本集是使用opencv_createsamples应用程序创建的。
负样本
负样本取自任意图像,不包含要检测的对象。这些负的图像,从其中产生的样本,应该被列在一个特殊的负图像文件中,每行包含一个图像路径(可以是绝对的或相对的)。注意,负样本和样本图像也称为背景样本或背景图像,并且可在本文档中互换使用。
所描述的图像可以具有不同的尺寸。然而,每个图像应该等于或大于所需的训练窗口大小(对应于模型维度,大多是目标的平均大小),因为这些图像用于将给定的负图像子采样成具有此训练窗口大小的多个图像样本。
一个负样本文件示例:
目录结构:
/img
img1.jpg
img2.jpg
bg.txt文件 bg.txt:
img/img1.jpg
img/img2.jpg当你试图找到你感兴趣的目标时,你的一组负面窗口样本将被用来告诉机器学习步骤,在这种情况下,不必寻找。
正样本:
正样本是由opencv_createsamples应用程序创建的。它们被升压(boosting。本人对此翻译持怀疑态度,故将英文贴在此处)过程使用来定义当试图找到感兴趣的目标时,模型应该实际寻找什么。该应用支持生成正样本数据集的两种方式。
- 你可以从单个正目标图像中生成一组正样本。
- 您可以自己提供所有的正样本图像,使用工具将它们裁剪,调整大小,并把它们放在OpenCV所需的二进制格式中。
虽然第一种方法对于固定的物体(如不会变化的Logo)的工作很有意义,但是对于刚性较低的物体来说,它很快就会失败。在这种情况下,我们建议使用第二种方法。网上的许多教程甚至陈列了100个真实对象图像,通过使用opencv_createsamples应用程序,可以得到比1000个人工生成的更好的正模型。然而,如果你真的决定采取第一种方法,记住一些事情:
- 请注意,在将它提交给所提到的应用程序之前,您需要多于一个正样本,因为它只应用透视变换。
- 如果你想要一个健壮的模型,那么就要检查覆盖在你的对象类中的各种各样的品种。例如,在检测人脸的情况下,你应该考虑不同的种族和年龄组,情感,甚至胡须风格。这也适用于使用第二种方法。
第一种方法采用单个对象图像,例如公司Logo,并通过随机旋转对象,改变图像强度以及将图像放置在任意背景上,从给定的目标图像创建一组大的正样本。随机性的数量和范围可以由opencv_createsamples应用程序的命令行参数来控制。
命令行参数:
- -vec
: 输出文件的名称,包含用于训练的正样本。 -img: 源对象图像(例如,公司徽标)。-bg: 背景描述文件;包含作为背景随机扭曲对象的背景的图像列表。-num: 产生正样本的数目。-bgcolor: 背景颜色(当前假设灰度图像);背景颜色表示透明颜色。由于可能存在压缩伪影,颜色公差的量可以由 -bgthresh指定。bgcolor-bgthresh和bgcolor+bgthresh范围内的所有像素都被解释为透明的。- -bgthresh
-inv: 如果指定,颜色将被反转。-randinv: 如果指定,颜色将被随机反转。-maxidev: 前景样本中像素的最大强度偏差。-maxxangle: X轴的最大旋转角,必须以弧度表示。-maxyangle: 在y轴上的最大旋转角必须以弧度表示。-maxzangle: 对于Z轴的最大旋转角,必须以弧度给出。-show: 有用的调试选项。如果指定,每个样品将被显示。按“Esc”将退出显示图像继续样本生成步骤。-w: 输出样本的宽度(以像素为单位)。-h: 输出样本的高度(以像素为单位)。
当以这种方式运行opencv_createsamples时,使用以下过程创建示例对象实例:给定源图像在所有三个轴上随机旋转。选择的角度是有限的-maxxangle,-maxyangle和-maxzangle。然后,从[bg_color-bg_color_threshold; bg_color+bg_color_threshold]范围的强度的像素被解释为透明的。白噪声被添加到前景的强度。如果指定了-inv密钥,则前景像素强度被反转。如果指定了-randinv密钥,则算法随机选择是否应该将反演应用于该样本。最后,将所获得的图像从背景描述文件放置到任意背景,将大小调整为由-w和-h指定的所需大小,并存储到由-vec命令行选项指定的vec-文件中。
正样本也可以从先前标记的图像的集合中获得,这是构建健壮对象模型时的理想方式。该集合由与背景描述文件类似的文本文件来描述。该文件的每一行对应于一个图像。行的第一个元素是文件名,其次是对象注释的数量,接着是描述对象包围矩形(x,y,width,height)的坐标的数字。
描述文件示例:
目录结构:
/img
img1.jpg
img2.jpg
info.dat文件 info.dat:
img/img1.jpg 1 140 100 45 45
img/img2.jpg 2 100 200 50 50 50 30 25 25图像img1.jpg包含单个对象实例,其中包含矩形的以下坐标:(140, 100, 45,45)。图像img2.jpg包含两个对象实例。为了从这些集合中创建正样本,应该指定-info参数,而不是-img:
额外备注:
- opencv_createsamples实用程序可用于检查存储在任何给定的正样本文件中的样本。为了做到这一点,只需指定-vec、-w和-h参数。
- 这里的示例可以参考opencv/data/vec_files/trainingfaces_24-24.vec。它可用于训练具有以下窗口大小的面部检测器:-w 24 -h 24
使用OpenCV的集成注释工具
自从OpenCV 3.x以来,社区一直在提供和维护一个开源的注释工具,用于生成-info文件。如果OpenCV应用程序在其中构建,则可以通过命令opencv_annotation来访问该工具。
使用该工具是相当简单的。该工具接受几个需要的和一些可选参数:
--annotations(required) : 注释TXT文件的路径,在其中存储注释,然后将其传递给-info参数[example - /data/annotations.txt]--images(required) : 文件夹中包含对象的图像的路径 [example - /data/testimages/]--maxWindowHeight(optional) : 如果输入图像的高度较大,那么这里给定的分辨率,为了便于注释,调整图像的大小,使用--resizeFactor--resizeFactor(optional) : 用于在使用--maxWindowHeight参数时调整输入图像大小的因素。
请注意,可选参数只能一起使用。下面可以看到一个可以使用的命令的例子。
opencv_annotation --annotations=/path/to/annotations/file.txt --images=/path/to/image/folder/这个命令将触发包含第一个图像和鼠标光标的窗口,这将用于注释。一个关于如何使用注释工具的视频可以在 这里 找到。基本上有几个触发动作的击键。鼠标左键用于选择对象的第一个角落,然后继续绘制直到你觉得好了,然后在第二个鼠标左键点击注册时停止。每次选择后,您有以下选择:(本人对下面翻译持怀疑态度,其中的“注释”的英文为“annotation”,可能是指应用程序opencv_annotation)
- 按C:确认注释,把注释变成绿色并确保它已经保存
- 按D:删除注释集中的最后一条注释(方便移除错误注释)
- 按N:继续下一个图像
- 按Esc:这将退出注释软件
最后,您将得到一个可用的注释文件,该文件可以被传递到opencv_createsamples的 -info参数。
梯度训练(Cascade Training)
下一步是基于预先准备好的正、负数据集,对弱分类器的增强级联进行实际训练。
按目的分组的opencv_traincascade应用程序的命令行参数:
常见参数:
-data: 训练过的分类器应该存储在哪里。这个文件夹应该手动创建。-vec: 具有正样本的vec-文件(由opencv_createsamples utility创建)。-bg: 背景描述文件。包含负样品图像的文件。-numPos: 每个分类器阶段训练中使用的正样本数。-numNeg: 每个分类器阶段训练中使用的负样本数。-numStages: 要训练的梯度(cascsde stages)的数目。-precalcValBufSize: 预先计算的特征值的缓冲区大小(单位为MB)。您分配的内存越多,培训过程越快,但是请记住,-precalcValBufSize和-precalcIdxBufSize组合不应超过可用的系统内存。-precalcIdxBufSize: 预先计算的特征索引的缓冲区大小(在MB中)。您分配的内存越多,培训过程越快,但是请记住,-precalcValBufSize和-precalcIdxBufSize组合不应超过可用的系统内存。-baseFormatSave: 这个参数在Haar-like特征的情况下通用。如果它被指定,梯度将以旧格式保存。这仅适用于向后兼容性的原因,并且允许用户坚持旧的已弃用的接口,至少使用新的接口来训练模型。-numThreads: 训练期间要使用的最大线程数。请注意,实际使用的线程数可能较低,这取决于您的计算机和编译选项。默认情况下,如果使用TBB支持构建OpenCV,则可以选择最大可用线程,这是优化的必要条件。-acceptanceRatioBreakValue: 这个参数被用来确定你的模型应该保持精确的学习和何时停止。一个好的准则是训练不要超过10e^-5,以确保模型不会对你的训练数据造成过度训练。默认情况下,此值设置为-1,以禁用此功能。
梯度参数:
-stageType: 阶段的类型。目前仅支持增强型分类器作为阶段类型。-featureType<{HAAR(default), LBP}>: 特征类型:HAAR - Haar-like features, LBP - local binary patterns。-w: 训练样本的宽度(以像素为单位)。必须与训练样本创建时使用的值完全相同(opencv_createsamples utility)-h: 训练样本的高度(以像素为单位)。必须与训练样本创建时使用的值完全相同(opencv_createsamples utility)
增强分类器参数:
-bt <{DAB, RAB, LB, GAB(default)}>: 增强分类器类型:DAB - Discrete AdaBoost, RAB - Real AdaBoost, LB - LogitBoost, GAB - Gentle AdaBoost。-minHitRate: 分类器的每个阶段的最小期望命中率。总体命中率可估计为 (min_hit_rate ^ number_of_stages), [192] §4.1-maxFalseAlarmRate: 分类器的每个阶段的最大期望虚警率(false alarm rate)。整体虚警率可估计为(max_false_alarm_rate ^ number_of_stages), [192] §4.1-weightTrimRate: 指定是否应该使用修整和它的重量。一个不错的选择是0.95。-maxDepth: 弱树(weak tree)的最大深度。一个不错的选择是1,就是树桩(stumps)的例子。-maxWeakCount: 每个梯度的弱树的最大计数。增强分类器(阶段)将有许多弱树(<=maxWeakCount),根据需要实现给定的-maxFalseAlarmRate。
Haar-like特征参数:
-mode: 选择在训练中使用的Haar特征集的类型。基本使用只有直立功能,而全部使用全套直立和45度旋转特征集。详情请参阅[ 110 ]。
本地二进制格式(Local Binary Patterns)参数:无。
opencv_traincascade应用程序完成工作后,将被训练的级联保存在-data文件夹中的cascade.xml文件中。此文件夹中的其他文件是针对中断训练的情况创建的,因此您可以在完成训练后删除它们。
训练完成,你可以测试你的级联分类器!
可视化级联分类器
不时地,可视化的训练级联,看看它所选择的特征和它的阶段是多么复杂是有用的。为此OpenCV提供opencv_visualisation应用程序。此应用程序具有以下命令:
--image(required) : 对象模型的参考图像路径。这应该是一个注释,标注为[-w,-h],传递给opencv_createsamples和opencv_traincascade 应用程序。--model(required) : 训练模型的路径,它应该在提供给opencv_traincascade应用程序的-data参数的文件夹中。--data(optional) : 如果必须手动创建的data文件夹被提供,则将存储阶段输出和特征的视频。
下面可以看到一个示例命令
opencv_visualisation --image=/data/object.png --model=/data/model.xml --data=/data/result/当前可视化工具的一些局限性
- 只处理级联分类器模型,用 opencv_traincascade工具进行训练,包含树桩(stumps)作为决策树[默认设置]。
- 所提供的图像需要是具有原始模型维度的样本窗口,传递给
--image参数。
HAAR/LBP人脸模型的例子在安吉莉娜·朱莉的给定窗口上运行,它具有与级联分类器文件相同的预处理-> 24x24像素图像、灰度转换和直方图均衡:
为每个阶段制作视频,每个特征可视化:

每个阶段被存储为图像,用于将来对特征的验证:
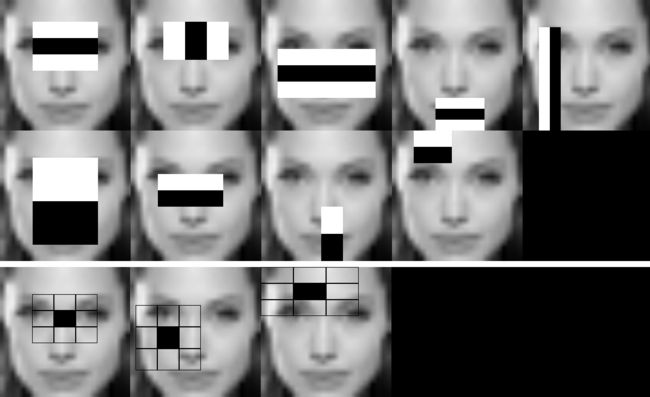
这项工作是由StevenPuttemans为OpenCV 3 Blueprints创建的,但Packt 出版社(Packt Publishing)同意将其集成到OpenCV中。