Python之numpy教程(二):运算、索引、切片
1.numpy数组的特点在于,大小相等的数组之间,任何算数运算都会将运算应用到元素级。
请看下面的例子:
arr = np.array([[1.,2.,3.],[4.,5.,6.]])
arrarray([[ 1., 2., 3.],
[ 4., 5., 6.]])
arr * arrarray([[ 1., 4., 9.],
[ 16., 25., 36.]])
arr - arrarray([[ 0., 0., 0.],
[ 0., 0., 0.]])
1 / arrarray([[ 1. , 0.5 , 0.33333333],
[ 0.25 , 0.2 , 0.16666667]])
arr ** 0.5array([[ 1. , 1.41421356, 1.73205081],
[ 2. , 2.23606798, 2.44948974]])
2.数据 索引:Python是从0的位置开始
arr = np.arange(10)
arrarray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arr[5]5
arr[5:8]array([5, 6, 7])
3.索引位置可以用来 更改数组值:
arr[5:8] = 12array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
4.从上面可以看出,跟列表最重要的区别是,数组切片是原始数组的视图。这意味着数据不会被复制,任何修改都会直接反映到源数组上:
arr_slice = arr[5:8]
arr_slice[1] = 12345arrarray([ 0, 1, 2, 3, 4, 12, 12345, 12, 8, 9])
arr_slice[:] = 64array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
5.如果你不要改变原始数组,需要 复制一份,可以这样操作:
arr_copy = arr[5:8].copy()6.对于 高维数组,索引位置上的元素不再是标量而是低一维的数组,比如:
arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]])arr2d[2]array([7, 8, 9])
7.对于 高维数组,索引元素需要进行 递归访问,可以传入一个以逗号隔开的索引列表来获取单个元素。
arr2d[0][2]3
arr2d[0,2]3
以上两种方法是等价的。
arr3d = np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
arr3darray([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]]) 这是一个
(2×2×3)的数组,可以通过运行arr3d.shape进行验证。
arr3d[0]
array([[1, 2, 3],
[4, 5, 6]])
old_values = arr3d[0].copy()
arr3d[0]= 42
arr3d
array([[[42, 42, 42],
[42, 42, 42]],
[[ 7, 8, 9],
[10, 11, 12]]])
arr3d[0]= old_values
arr3d
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
arr3d[1,0]
array([7, 8, 9])
9.再看几个二维数组的索引例子,用刚才创建的那个arr2d数组,注意 索引位置包括开头但不包括结尾,比如[0:2]是索引1、2位置,但没有3。
arr2darray([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
arr2d[:2]
array([[1, 2, 3],
[4, 5, 6]]) 注意没有第三个元素,也就是arr2d[2]
arr2d[:2,1:]
array([[2, 3],
[5, 6]])
arr2d[1,:2]array([4, 5]
arr2d[2,:1]
array([7])
arr2d[:,:1]
array([[1],
[4],
[7]])
arr2d[:2,1:] = 0
arr2d
array([[1, 0, 0],
[4, 0, 0],
[7, 8, 9]]) 可以借助下图来理解:
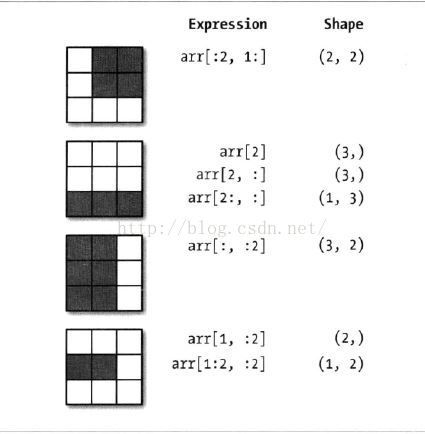
10.布尔型索引
names = np.array(['Bob','Joe','Will','Bob','Will','Joe','Joe'])
namesarray(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'],
dtype=' 生产一组随机数组
import numpy.random
data = numpy.random.randn(7,4)
data
输出:
array([[ 0.98990731, -0.26694924, 1.17834132, -0.21712539],
[ 1.10877471, 0.04496048, 0.99851866, -0.65930485],
[ 0.20479382, -0.09918733, -0.51451222, 1.43864803],
[-0.30217902, 1.20441035, -0.88069583, -0.31243213],
[-1.47970158, 0.08452533, -1.56347609, 1.88383865],
[ 0.45802479, 0.84710767, -1.87281658, 0.90212452],
[ 0.57361001, 0.61528872, 1.25977742, -0.06899717]])
判断,产生一个布尔型数组
names == 'Bob'
输出:
array([ True, False, False, True, False, False, False], dtype=bool)
这个布尔型数组可以用于数组索引
data[names == 'Bob']
输出:
array([[ 0.98990731, -0.26694924, 1.17834132, -0.21712539],
[-0.30217902, 1.20441035, -0.88069583, -0.31243213]]) 可以将布尔型数组跟切片、整数混合使用
data[names == 'Bob',2:]
输出:
array([[ 1.17834132, -0.21712539],
[-0.88069583, -0.31243213]])
data[names == 'Bob',3]
输出:
array([-0.21712539, -0.31243213])
也可以用不等号(!=)进行或者符号(-)对条件进行否定索引
names != 'Bob'
输出:
array([False, True, True, False, True, True, True], dtype=bool)
data[-(names == 'Bob')]
输出:
array([[ 1.10877471, 0.04496048, 0.99851866, -0.65930485],
[ 0.20479382, -0.09918733, -0.51451222, 1.43864803],
[-1.47970158, 0.08452533, -1.56347609, 1.88383865],
[ 0.45802479, 0.84710767, -1.87281658, 0.90212452],
[ 0.57361001, 0.61528872, 1.25977742, -0.06899717]])
11.也可以使用
多个布尔型条件进行索引,这在实际操作中十分常见
mask = (names == 'Bob')|(names == 'Will')
mask
输出:
array([ True, False, True, True, True, False, False], dtype=bool)
data[mask]
输出:
array([[ 0.98990731, -0.26694924, 1.17834132, -0.21712539],
[ 0.20479382, -0.09918733, -0.51451222, 1.43864803],
[-0.30217902, 1.20441035, -0.88069583, -0.31243213],
[-1.47970158, 0.08452533, -1.56347609, 1.88383865]])
把小于0的数都变为0
data[data < 0] = 0
data
输出:
array([[ 0.98990731, 0. , 1.17834132, 0. ],
[ 1.10877471, 0.04496048, 0.99851866, 0. ],
[ 0.20479382, 0. , 0. , 1.43864803],
[ 0. , 1.20441035, 0. , 0. ],
[ 0. , 0.08452533, 0. , 1.88383865],
[ 0.45802479, 0.84710767, 0. , 0.90212452],
[ 0.57361001, 0.61528872, 1.25977742, 0. ]])
data[names != 'Joe'] = 7
data
输出:
array([[ 7. , 7. , 7. , 7. ],
[ 1.10877471, 0.04496048, 0.99851866, 0. ],
[ 7. , 7. , 7. , 7. ],
[ 7. , 7. , 7. , 7. ],
[ 7. , 7. , 7. , 7. ],
[ 0.45802479, 0.84710767, 0. , 0.90212452],
[ 0.57361001, 0.61528872, 1.25977742, 0. ]])
11.花式索引:
花式索引(Fancy indexing)是一个Numpy术语,它指的是利用整数数组进行索引。
先建立一个8×4的empty数组
arr = np.empty((8,4))
arr
输出:
array([[ 2.27764263e-321, 0.00000000e+000, 3.65717707e-316,
0.00000000e+000],
[ 0.00000000e+000, 2.50223420e-315, 0.00000000e+000,
4.42980404e-316],
[ 0.00000000e+000, 3.61995693e-316, 2.50223420e-315,
4.43565180e-316],
[ 2.50097935e-315, 4.59507256e-316, 0.00000000e+000,
0.00000000e+000],
[ 0.00000000e+000, 0.00000000e+000, 4.42208160e-316,
0.00000000e+000],
[ 3.65629171e-316, 1.98465379e-317, 2.50224669e-315,
2.63675246e-316],
[ 0.00000000e+000, 0.00000000e+000, 0.00000000e+000,
0.00000000e+000],
[ 2.50224384e-315, 0.00000000e+000, 0.00000000e+000,
4.59490260e-316]])
给其赋值
for i in range(8):
arr[i] = i
arr
输出:
array([[ 0., 0., 0., 0.],
[ 1., 1., 1., 1.],
[ 2., 2., 2., 2.],
[ 3., 3., 3., 3.],
[ 4., 4., 4., 4.],
[ 5., 5., 5., 5.],
[ 6., 6., 6., 6.],
[ 7., 7., 7., 7.]]) 以
特定的顺序选取行子集,只需传入一个用于指定顺序的整数列表或ndarray:
arr[[4,3,0,6]]
输出:
array([[ 4., 4., 4., 4.],
[ 3., 3., 3., 3.],
[ 0., 0., 0., 0.],
[ 6., 6., 6., 6.]])
使用负数索引会从末尾开始:
arr[[-3,-5,-7]]
输出:
array([[ 5., 5., 5., 5.],
[ 3., 3., 3., 3.],
[ 1., 1., 1., 1.]])
使用reshape函数改变行列数
arr = np.arange(32).reshape((8,4))
arr
输出:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
arr[[1,5,7,2],[0,3,1,2]]
输出:
array([ 4, 23, 29, 10])
可以看出,最终选出的元素是(1,0)、(5,3)、(7,1)、(2,2)
arr[[1,5,7,2]][:,[0,3,1,2]]
输出:
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]]) 另外一个办法是使用
np.ix_函数,它可以将两个一维整数数组转换为一个用于选取
方形区域的索引器:
arr[np.ix_([1,5,7,2],[0,3,1,2])]
输出:
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]]) 注意:花式索引跟切片不一样,它总是将数据复
制到新数组中。