文本检测模型综述
之前做车牌检测使用文本检测模型,如east、ctpn和textboxes,但是效果不是很好,需要针对车牌专门训练。后面就采用ssd和yolo进行车牌的检测,但是车牌有时是旋转的,使用ssd和yolo模型无法对车牌的四个点进行精确定位,而文本检测模型很多都能精确的回归文本四个点的位置,因此还是需要对文本检测模型进行一定的了解。
首先介绍为什么直接使用ssd和yolo进行文字检测效果不理想,原因如下:
- 相比于常规物体,文字行长度、长宽比例变化范围很大,而ssd和yolo都是anchor-based,它们有固定位置以及长宽比例,如果长宽比例和文字形状差别很大,就很难通过回归找到一个紧凑包围它的边框。
- 文本行有方向性,anchor-based的检测通常是水平和垂直方向的矩形。
- 有些艺术字体形状变化非常大,很多是弯曲的。
- 由于丰富的背景图像干扰,手工设计特征在自然场景文本识别任务中不够鲁棒。
具体可以看下图:


针对这些问题,目前主要围绕特征提取、RPN、多目标协同训练、loss改进、NMS、半监督学习等角度对常规物体检测方法进行改造。极大的提高了自然场景图像中文本检测准确率。
如:
- ctpn方案中,用blstm模块提取字符所在图像上下文特征,以提高文本块识别精度。
- east方案中,模型支持任意方向的四边形检测,输出的结果要么为四个点坐标,要么为回归的框以及对应的角度。
- seglink方案中,该模型能预测单个小文字块,然后将其link成单词,并且能够预测倾斜的文本。
- textboxes方案中,分别调整了anchor box和卷积核的尺寸为长方形,以更适应文本细长型的特点。
- textboxes++方案中,相比textboxes,它能预测任意方向的文本框,因为对anchor box和卷积核都做了相应的修改。
- rrpn方案中,文本框标注采用bbox+方向角度的形式,模型中产生出可旋转的文字区域候选框,并在边框回归计算过程中找到待测文本行的倾斜角度。
- dmpnet方案中,使用quadrilateral作为anchor box,从而能够更好的检测倾斜文本行。
- pixellink方案中,并未使用常规的回归方式,而是使用实例分割的方法来预测文本行。
- wordsup方案中,使用弱监督的训练方式, 在文本行和单词级标注的数据集上训练出字符级的检测模型。
接下来我们详细描述上面提到的模型:
CTPN模型:
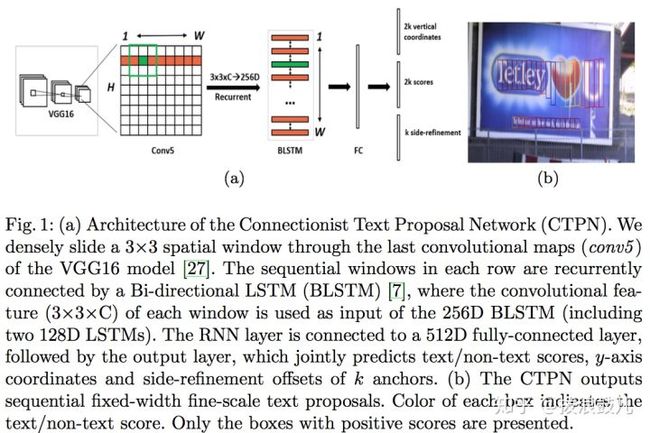
CTPN模型可以检测水平或微斜的文本行,其中文本行被看成一个字符sequence,而不是一般物体检测中单个独立的目标。同一文本行上各个字符图像间可以互为上下文,在训练阶段让检测模型学习图像中蕴含的这种上下文统计规律,可以使得预测阶段有效提升文本块预测准确率。下面简单描述其基本流程:
- 用vgg16的前五个conv stage得到feature map(W*H*C)
- 在conv5的feature map的每个位置上取3*3*C的窗口的特征,这些特征将用于预测该位置K个anchor对应的类别信息和位置信息
- 将每一行的所有窗口对应的3*3*C的特征(W*3*3*C)输入到BLSTM中,得到W*256的输出
- 将BLSTM的W*256输入到512维的fc层
- fc层特征输入到三个分类+回归层中,其中第二个2k scores表示的是k个anchor的类别信息(是否为字符)。第一个2k vertical coordinate(bounding box的高度和中心的y坐标)和第三个k side-refinement(bounding box的水平平移量)用来回归k个anchor的位置信息。这里只用三个参数表示回归的bounding box,因为这里默认了每个anchor的width是16,且不再变化(vgg16的conv5的stride是16)。
- 用简单的文本线构造算法,把分类得到的文字的proposal合并乘文本线。
下图是我使用ctpn的检测效果:


EAST模型
EAST(Efficient and Accuracy Scene Text detection pipeline)模型,这种模型支持旋转矩形框、任意四边形两种文本区域标注形式。对于四边形标注,模型执行时会对特征图中每个像素预测其到四个顶点的坐标差值。对于旋转矩形框标注,模型执行时会对特征图中每个像素预测其到矩形框四边的距离以及矩形框的方向角。
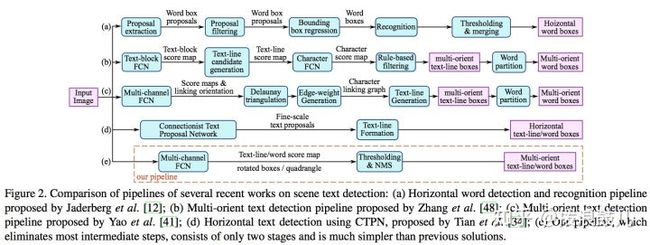
下图中的(e)部分即为east的过程,从图中可以看出它的efficient体现在对一些过程的消除上。相比(a)(b)(c)(d),该模型省略了常见的区域建议、单词分割、子块合并等步骤,因此速度较快。另外east类似于上面介绍的ctpn模型,不过ctpn只支持水平方向的检测,而east可以支持多方向文本的定位。
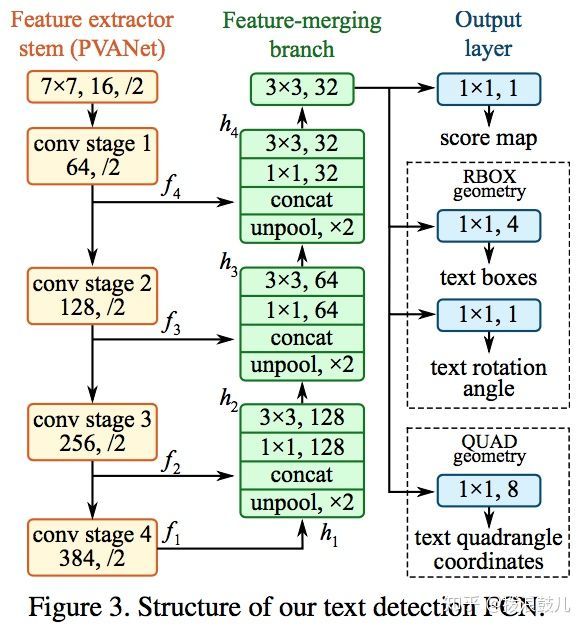
具体做法如下:
首先使用PVANet作为backbone,这里使用fpn的思想分别从stage1,stage2,stage3,stage4提取特征。之后对抽取的特征做上采样,并concat到一起。最后的输出层会输出一个score map,四个回归的框以及一个角度信息,或者输出一个score map和八个坐标信息。
下面是我使用EAST的检测效果:
从结果可以看出该模型对英文短单词检测效果较好,但是长文本的效果欠佳。如果针对长文本进行针对性训练,也许能够取得更好的效果。
SegLink模型
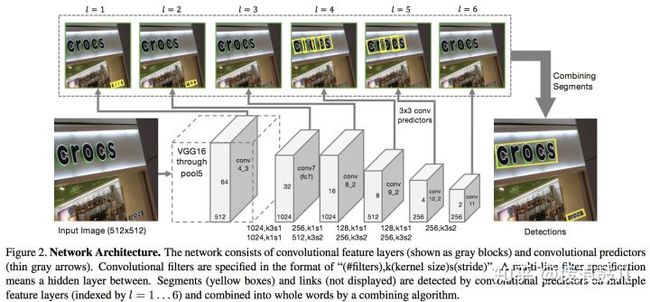
seglink(segment+link)模型先将每个单词切割成更易检测的有方向的小文字块(segment),然后用邻近连接将各个小文字块link成单词。这种方法方便识别长度变化范围很大、带方向的单词和文本行。
作者所使用的网络是ssd网络,它会输出两类信息:
- 一个是文本的box信息,该box不是整个文本行的box,而是文本行的一部分,称为segment,它可能是一个字符或者几个字符等。这个信息是带有角度的,如下图的黄框表示。
- 另一个是不同segment的link信息,它的输出是整个文本行,因此它需要将这些box连接成文本行,而这个link也是在网络中自动学习的,由网络判定哪些segment属于一个文本行,由下图的绿线表示。

下图是采用的ssd网络结构:
这里简要描述它和ssd的区别:
- ssd输出x,y,w,h四个参数,而seglink加入了角度信息,输出的是x,y,w,h,θ,这个角度代表矩形框的角度,与水平方向的的夹角顺时针为正、逆时针为负
- ssd每个feature map的每个位置上由多个不同的aspect ratio的default box,seglink每个位置上只有一个default box,这样可以加速
- ssd每层的feature map决定的default box的scale人工定义(10-90,平均分5次),seglink的scale由感受野大小来决定
- seglink不但学习segment,也学习segment之间的link关系,来表示是否为同一个单词
- seglink训练用的gt除了因为多方向所以用的旋转后的gt,还要有一个link的gt
- seglink的损失函数中加入了link的损失项
对于link的学习分为within-layer link(层内连接,周围的八个segment)和cross-layers link(层间link,一个word的segments可能同时被多层检测到)
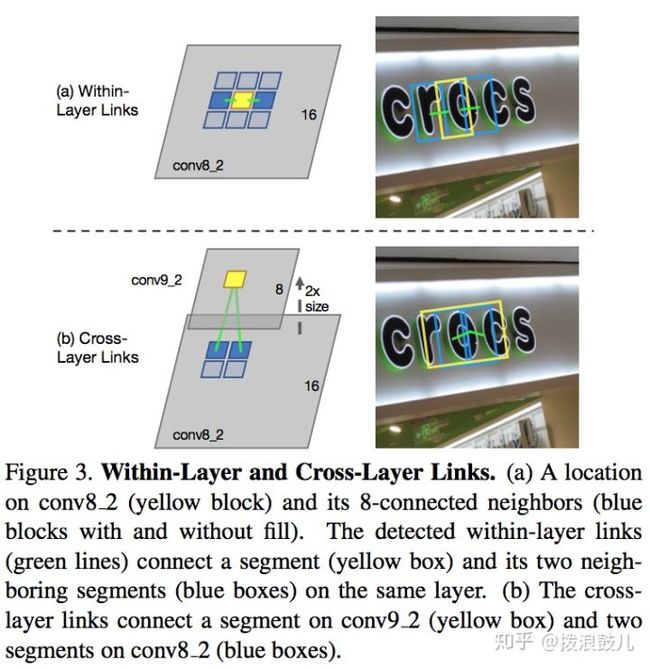
TextBoxes模型
该模型同上面类似,也是改进的ssd算法。其主要改进如下:
- 文字通常是细长型,因此将default box的长宽比改为1,2,3,5,7,10初始值
- 受inception风格的滤波器启发,设计了非常规的1*5滤波器,而没有采用3*3的滤波器,使其能适应大纵横比的单词,也避免了正方形感受野带来的噪声信号
- ssd从多类检测变为了单类检测
- 为了进一步提高检测精度,使用多个比例的输入图片作为输入
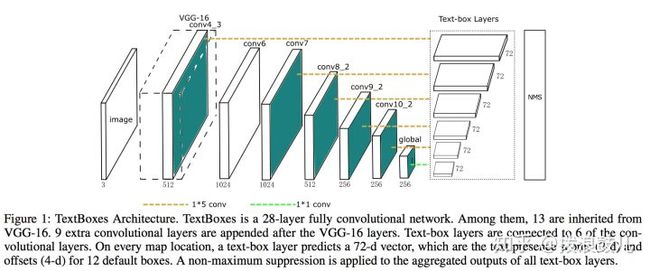
如上图所示,前面的和ssd结构基本一致,最后增加了text-box层,该层的深度是72,因为每个区域有12个比例不同,位置不同的default boxes,每个框需要预测4个坐标值,即预测框与默认框的偏差,还要预测通过softmax进行二分类得到2个概率值,因此总共是72维的向量。
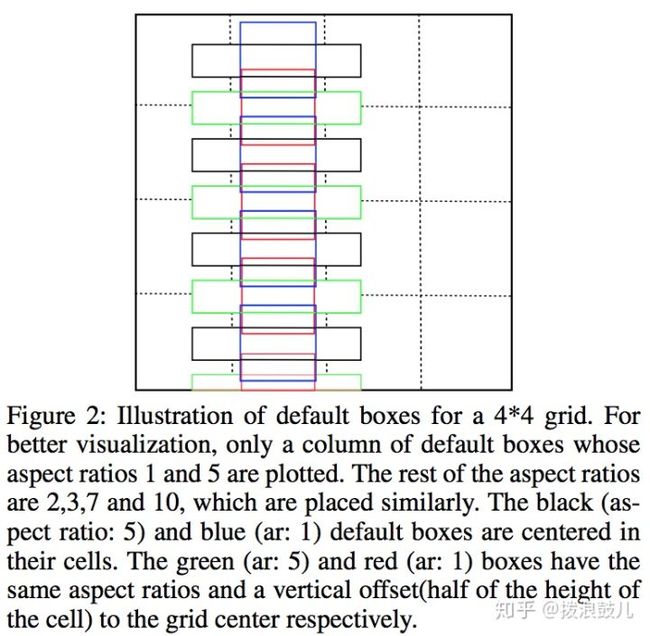
通常默认框在水平方向上排列紧密而在垂直方向上排列稀疏,这样会造成检测失误的情况,因此将水平方向上的这些默认框全部向下平移半个区域的单位,下图中是将黑色与蓝色向下平移得到绿色和红色。从而解决了默认框排列不均匀的问题
下面是我使用TextBoxes的检测效果:


TextBoxes++模型
textboxes模型只能预测水平的文字,而textboxes++模型可以预测任意方向的文字,其做了如下方面的改进
上图中黄色实线框是ground truth框,绿色虚线框是最匹配的default box框,黑色虚线框是不匹配的default box框,绿色实线框是包含ground truth框的最小外接矩形框。我们需要学习的就是绿色虚线框到黄色实线框以及绿色实线框的偏移。
因为该模型是预测带方向的文本框,因此默认的default box从1,2,3,5,7,10变为了1,2,3,5,1/2,1/3,1/5。另外1*5的卷积核也变成了3*5的卷积核以适应各个方向的文本框。
和textboxes相似的是在垂直方向加了default box,以应对只有水平方向default box密集的情况
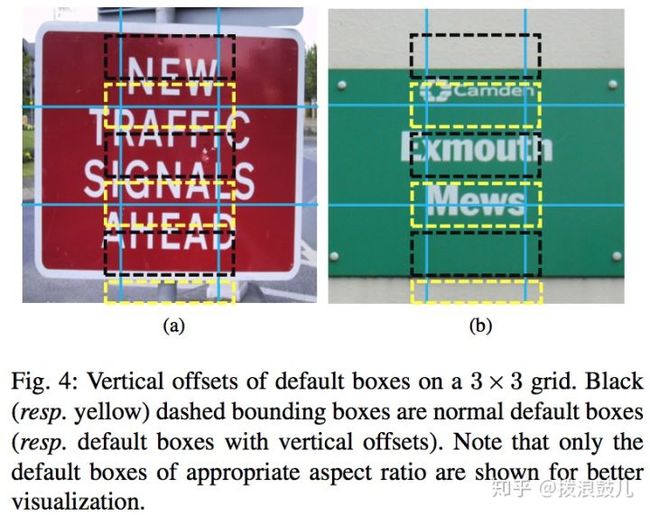
如上图左边中间的黑色虚线框所示,当两个单词很接近时它并不能同时处理这两个单词(通常一个ground truth可以匹配到多个anchor,但是一个anchor只能匹配一个ground truth)。如上图右边下面的黑色虚线框所示,它完全不能覆盖下面的单词。因此我们很有必要增加垂直的default boxes(图中黄框所示).
RRPN模型:
基于旋转区域候选网络(rotation region proposal networks)的方案,将旋转因素考虑进去。
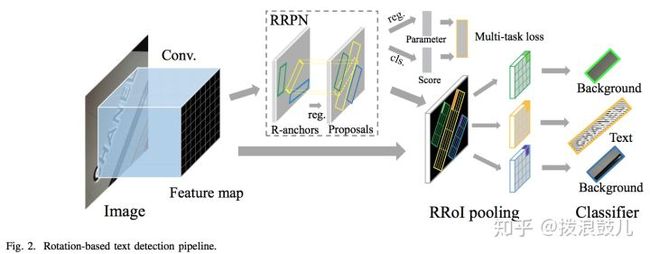
其中前端是vgg-16用来提取feature-map,中间是rrpn生成带倾斜角的候选区域,最后是multi-task loss。在训练阶段,一个文本区域的ground truth用一个五元组(x,y,h,w,θ)来表示,(x,y)表示边界框的几何中心的坐标。高度h表示短边的长度,宽度w表示长边的长度,而θ表示长边的方向。
对传统的锚点框进行了改进,以适应自然场景下的文本检测。首先,新增了方向变量,加入6个方向角:-π/6、0、π/6、π/3、π/2、2π/3。其次,为符合文本框的形状,将比例调整为:1:2、1:5、1:8。大小还是8,16,32保持不变。这样对于特征图上每一个点将生成54个R型锚点(6种方向,3种大小,3种比例)。因此分类层有108(2*54)个输出值,回归层有270(5*54)个输出值。
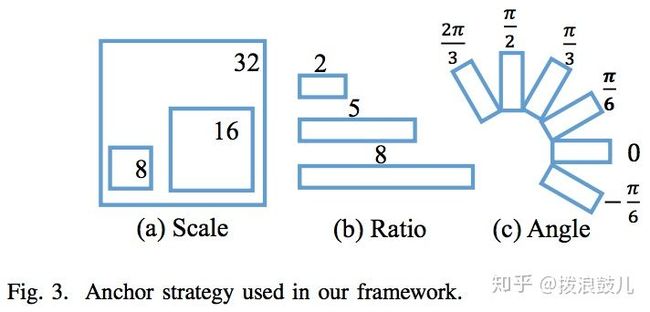
对正负锚点的标定规则如下:
- 如果锚点对应的box与gt的iou值最大,标记为正样本。
- 如果锚点对应的box与gt的iou>0.7,标记为正样本。
- 如果锚点对应的box与gt的夹角小于π/12,标记为正样本。
- iou小于0.3,标记为负样本。
- iou大于0.7,但是夹角大于π/12,标记为负样本。
- 剩下的非正非负,不用于训练。
损失函数分别采用交叉熵损失和smoothl1损失。
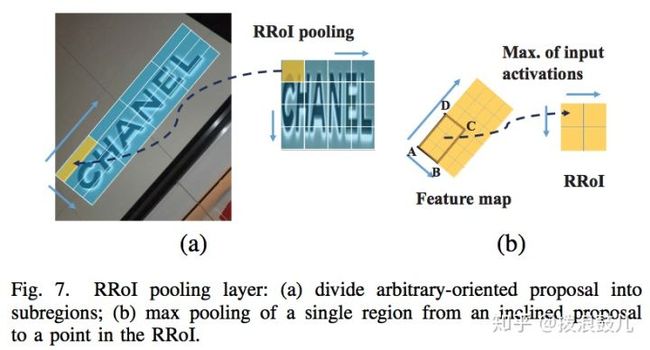
另外修改roi为rroi(rotation roi)池化层,将任意方向的区域建议先划分为子区域,然后对这些子区域分别做max pooling,并将结果投影到具有固定空间尺寸的特征图上。
DMPNet模型
DMPNet(deep matching prior network)模型以vgg16为base model,使用四边形来更紧凑的标注文本区域边界,因此该模型对倾斜文本块检测效果更好。
首先它使用quadrilateral sliding windows来对text进行粗定位
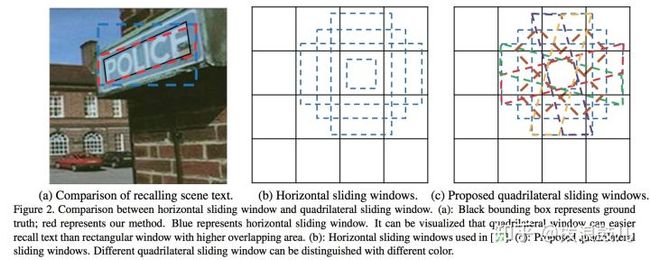
其中(c)就是作者提出的quadrilateral作为anchor box,从(a)里面可以看到水平anchor box和倾斜anchor box的差别很大。因此quadrilateral能够更好的对text进行定位,减少背景噪声的影响。
其次为了计算gt和anchor box的iou,作者认为原来的算法只能计算矩形之间的iou,并且效率不高,因此提出了基于蒙特卡洛的方法来计算多边形的面积。
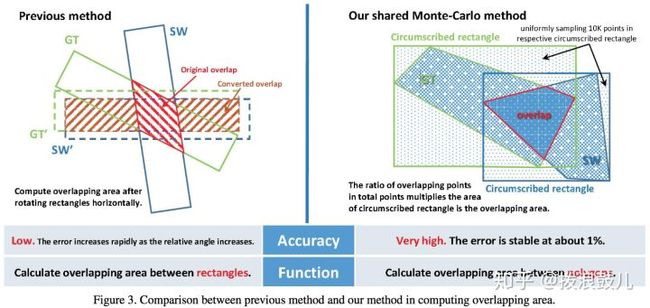
方法有下面两步:
- 对于ground truth,首先在它的外接矩形框里均匀采样10000个点,然后统计在ground truth多边形里面的点,得到gt的面积。
- 如果sliding windows的外接矩形和gt的外接矩形不相交,那么gt和sliding window的iou就是0,否则根据上一步骤的方法计算sliding window的面积,然后统计gt里面的点在sliding window里面的比例,求的交叉区域的面积,得到iou。
该方法在gpu上可以并行计算,因此这种方法的效率很高。
之后需要根据上一步骤可以得到哪些sliding window负责预测text之后,下一步就是根据这些sliding window的参数预测四边形的坐标。首先我们需要确定四边形四个点的预测顺序。
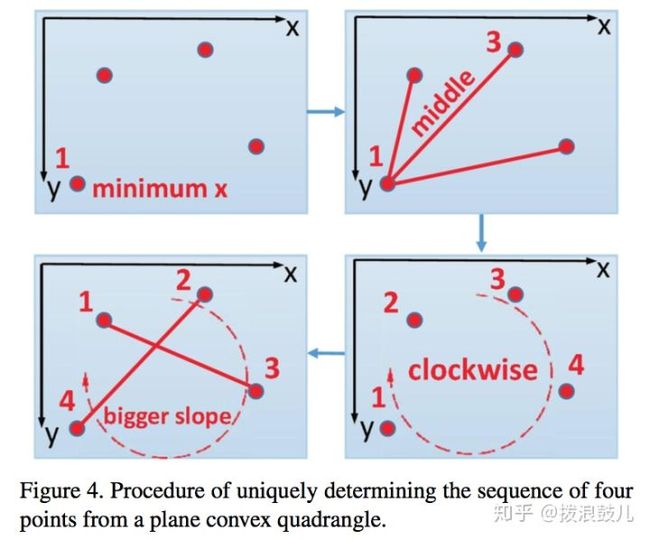
我们首先选择x坐标最少,同时y坐标也最小点作为点1,之后将这个点和剩下的点连成三条线段,取中间那条作为点3,位于使这条线大于0的点作为点2,否则为点4. 之后我们连接点1,3和点2,4。选择斜率更大的那条线上x更小的点作为新的点1,剩下的依次确定。
最后在我们确定了点的顺序后,要预测的参量其实就是四个点的坐标。作者这里换了一种预测方法:
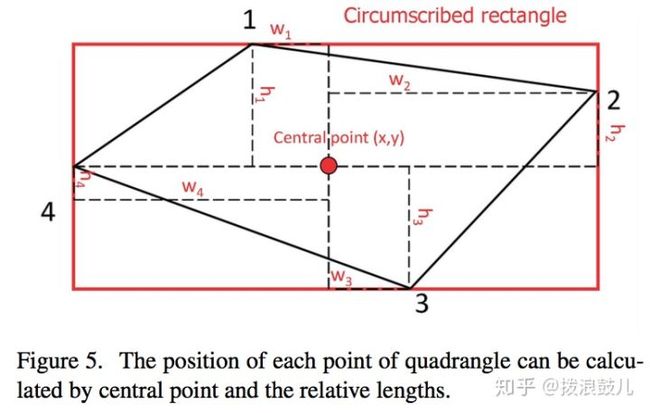
对于gt四边形,得到它的最小外接矩形。然后用(x,y,w1,h1,w2,h2,w3,h3,w4,h4)表示这个gt,其中(x,y)表示外接矩形的中心点坐标,(wi,hi)表示四边形四个点相对(x,y)的偏移。
对于回归loss函数的选取,作者认为smooth l1 loss相比l2 loss对于离群值的敏感度更小。但是从训练的角度来说,l2 loss能够加速收敛的速度。因为l1 loss的梯度始终为1,而l2 loss的梯度和误差同一量级,这样可以加速收敛。
因此作者提出了smooth ln loss,综合了l2 loss和smooth l1 loss的特点。
smoothLn(x) = (|d| + 1)ln(|d| + 1) − |d|
deviationLn(x) = sign(x) · ln(sign(x) · x + 1)
从图中可以看出,smooth ln loss对于离群值的敏感度低于smooth l2 loss,同时梯度的调节能力优于smooth l1 loss。
PixelLink模型
该模型和上面的模型差别很大,它并不是anchor-base的,而是用分割的思想来检测文字。自然场景图像文字通常混在一起,通过semantic segmentation(语义分割)很难将他们识别开来,因此这里采用instance segmentation(实例分割)方法来解决这个问题。
该模型的特征提取部分是vgg16为基础而构建的fcn网络。
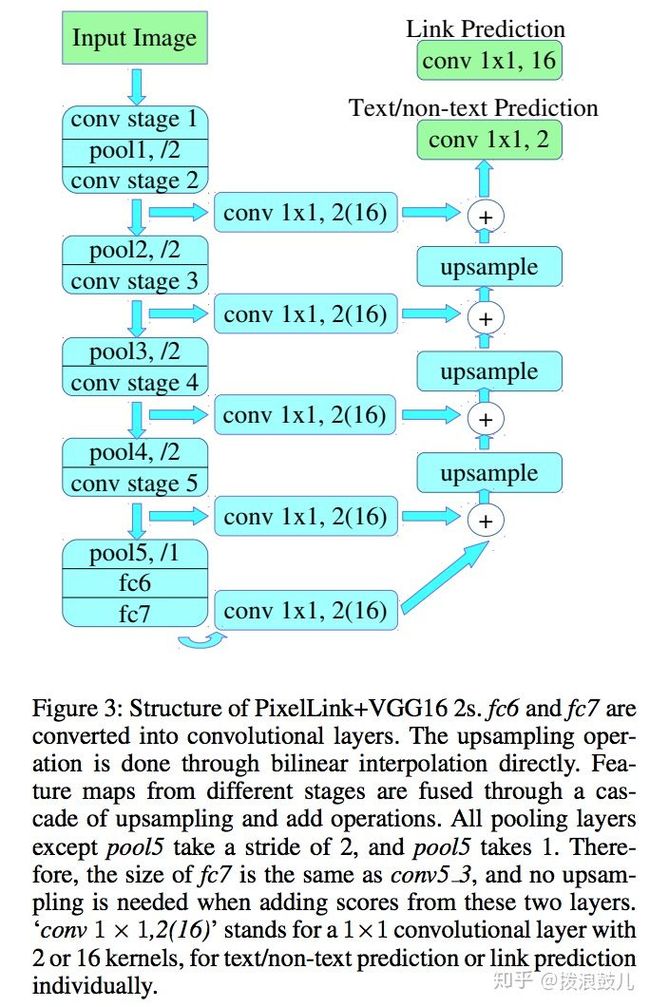
下图是其执行流程:
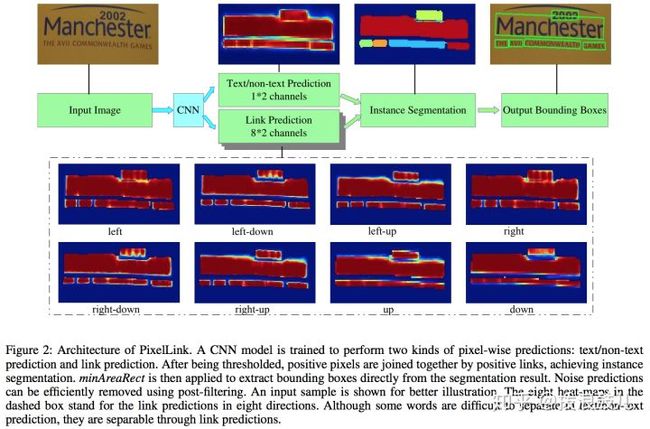
首先使用cnn模块执行两个像素级预测:一个文本二分类预测,一个链接二分类预测。
接着针对正链接连接邻居正文本像素,得到文本块实例分割结果。
最后由分割结果直接就获得文本块边框,这种方式可以生成倾斜边框。
可以看出该方法不需要回归边框,因此训练收敛速度更快,但是分割的方式通常需要复杂的后处理。
WordSup模型:
通常在数学公式图文识别、不规则形变文本行识别等应用中,我们需要进行字符级检测。但是字符级检测需要很高的标注成功,已知的公开数据集又很少,导致现在很多文本检测只能在文本行或者单词级别标注的数据进行训练。而该模型提出了一种弱监督的训练框架, 可以在文本行和单词级标注的数据集上训练出字符级的检测模型。
下图给出其训练的网络结构:
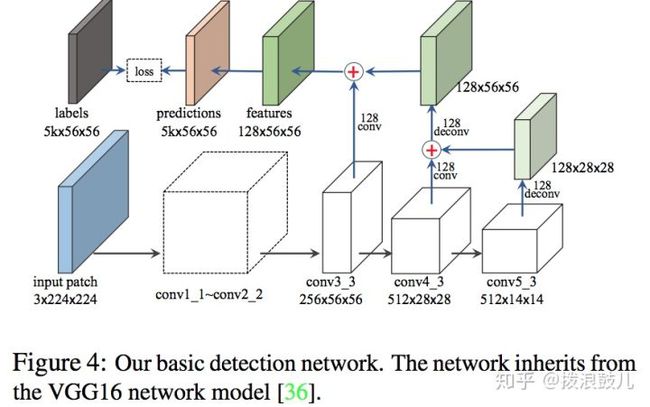
作者使用vgg16模型作为特征提取器,考虑到不同场景的字符在大小上具有非常大的差异,在1M像素的图像中有些字符可能只有10*10的大小,因此我们最终的特征图大小为原图的1/4,而不是像常用的物体检测1/16,1/32这种尺寸。但是由于更深的特征图具有更大的感受野,因此作者也使用fpn的形式将高层的特征图做上采样来和低层的特征图做融合(eltsum)。最终的预测特征图的channel数为5k,分别代表是否是文本(只需一个channel),以及4个回归的坐标。k代表anchor的数目,这里取k=3,代表在224*244的输入大小上文本对角线的长度为24pixels,16pixels和12pixels。只要我们预测的文本其对角线为anchor的0.7~1.4倍就被判定为正样本。
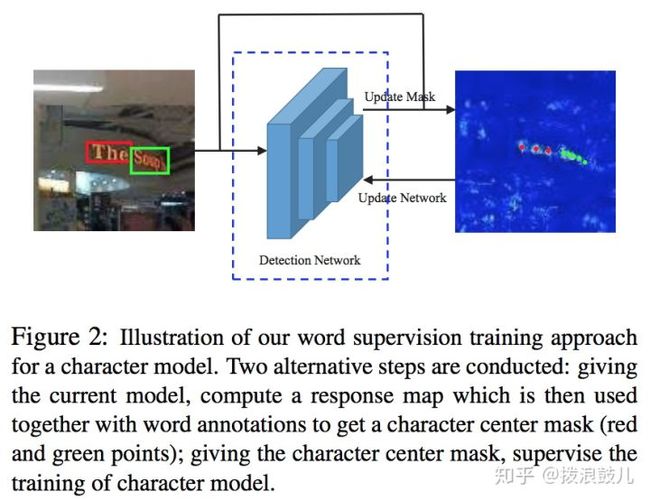
在下图中,wordsup弱监督训练框架中,两个训练步骤交替进行:给定当前字符检测模型,并结合单词级标注数据,计算出字符中心点掩码图。给定字符中心点掩码图,有监督地训练字符级检测模型。
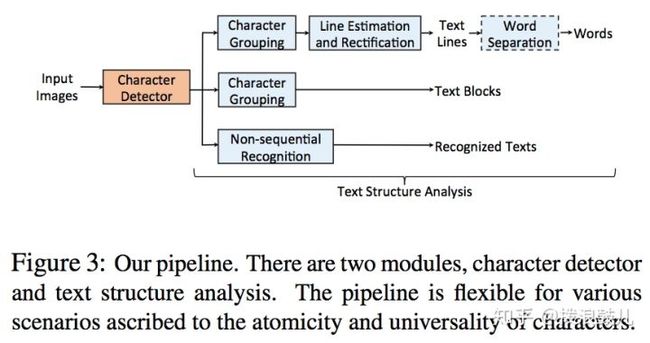
在训练好字符检测器后,可以在数据流水线中加入合适的文本结构分析模块,以输出符合应用场景要求的文本内容。这里作者列举了多种文本结构分析模块的实现方式。
总结:
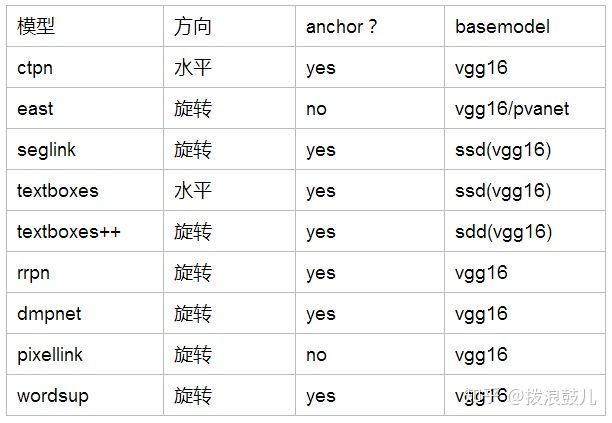
上文中除了pixellink是采用分割的思想外,剩下的所有模型都是魔改anchor-base的方式。另外华科的三篇文章seglink,textboxes,textboxes++都是在ssd的基础上进行的修改。考虑到ssd的base model也是vgg16,因此所有的模型都采用vgg16作为base model,如果将vgg16换成resnet或者densenet这种结构,也许每篇文章都能有一定程度的涨点。在预测方向上,ctpn和textboxes只能预测水平的文本框,而剩下的所有模型都能预测带有一定角度的文本框。下面以一个表格来结束整篇综述:
Ps: 这篇博客是在https://zhuanlan.zhihu.com/p/38655369?utm_source=qq&utm_medium=social基础上进行了修改和扩展,后续会推出一篇文本识别的综述。
参考文献:
https://arxiv.org/pdf/1609.03605.pdf
https://arxiv.org/pdf/1704.03155.pdf
https://arxiv.org/pdf/1703.06520.pdf
https://arxiv.org/pdf/1611.06779v1.pdf
https://arxiv.org/pdf/1801.02765.pdf
https://arxiv.org/pdf/1705.10447.pdf
https://arxiv.org/pdf/1703.01425.pdf
https://arxiv.org/pdf/1801.01315.pdf
https://arxiv.org/pdf/1708.06720v1.pdf
https://zhuanlan.zhihu.com/p/38655369?utm_source=qq&utm_medium=social
https://blog.csdn.net/zchang81/article/details/78873347
https://blog.csdn.net/qq_14845119/article/details/78986449
https://blog.csdn.net/sparkexpert/article/details/77987654
https://blog.csdn.net/xxiaozr/article/details/77451277
https://blog.csdn.net/u013102349/article/details/79524233
https://www.jianshu.com/p/b3c1a2f27dec
https://blog.csdn.net/w5688414/article/details/77986955
https://blog.csdn.net/hx921123/article/details/56845256
https://blog.csdn.net/w5688414/article/details/77986955
https://blog.csdn.net/ChuiGeDaQiQiu/article/details/79821576
https://blog.csdn.net/yaoqi_isee/article/details/73432759
编辑于 2018-09-26
OCR(光学字符识别)
深度学习(Deep Learning)
计算机视觉
赞同 5415 条评论
分享
收藏
文章被以下专栏收录

ocr
进入专栏
推荐阅读
文字识别OCR方法整理
白裳
超强合集:OCR 文本检测干货汇总(含论文、源码、demo 等资源)
极市平台发表于极市平台
Fast-OCNet: 更快更好的OCNet.
RainBowSecret
最新的Anchor-Free目标检测模型FCOS,现已开源!
Amusi发表于计算机视觉...
15 条评论
切换为时间排序
写下你的评论...
发布
-
SpartacusIn2111 个月前
膜拜大佬
赞回复踩举报
-
王哲11 个月前
学习了!
赞回复踩举报
-
村夫11 个月前写的太好了,准备花一年时间研究研究大神的总结
1回复踩举报
-
zhouyx10 个月前已阅
赞回复踩举报
-
黄裳10 个月前
果然是符合no free lunch theorem,如果是直线文字,看起来还是ctpn效果最好。
赞回复踩举报
展开其他 1 条回复
-
希尔伯特空间9 个月前
anchor是直接预测举行和角度,没有anchor
赞回复踩举报
-
拨浪鼓儿 (作者) 回复希尔伯特空间9 个月前嗯,后面仔细看了,确实没有anchor,应该归为分割类里
赞回复踩举报
-
gavin回复拨浪鼓儿 (作者)7 个月前你这里说的是哪个分为分割?
赞回复踩举报
-
小马4 个月前
请问文字检测方向现在的难点主要是什么问题?现在有什么可以改进的地方
赞回复踩举报
-
小马回复小马4 个月前补充一下: 因为现在基于anchor的方法其实不太适合在文本检测上,不适宜解决多方向检测的问题,所以之后的工作或许在直接回归坐标点(不基于anchor) 或者利用keypoint detection的思路去做,是否可以是个方向?
赞回复踩举报
-
拨浪鼓儿 (作者) 回复小马4 个月前现在更多的是基于分割的方式来做文本检测
赞回复踩举报
-
程洁1 个月前
哇这总结也太棒了吧!!!请问答主就是chineseocr那个github里有的项目里说是用了yolo v3+crnn 进行的检测和定位 但是我看了好像是ctpn的原理呀
赞回复踩举报
-
拨浪鼓儿 (作者) 回复程洁1 个月前我没有用那个,用那个也可以。那个就是把ctpn的原理,用yolo来检测小块
赞回复踩举报
- GYxiaOH19 天前
为什么textboxes平移能解决稀疏的问题啊,是平移前后的框都保留吗
赞回复踩举报