Ubuntu16.04中caffe-ssd(GPU版)训练自己的数据并测试模型
注意:首先你安装了ssd(GPU),并测试了VOC数据。
一、labelImg的安装
目标检测中,原始图片的标注过程是非常重要的,它的作用是在原始图像中标注目标物体位置并对每张图片生成相应的xml文件表示目标标准框的位置。labelImg 是一种能够标注多类别并能直接生成xml文件的标注工具。
1、下载LabelImg
下载地址:https://github.com/tzutalin/labelImg
下载后将labelImg-master.zip移动至home主文件夹下解压,得到LabelImg-master文件,打开后如下图所示。
2、安装
$ sudo apt-get install pyqt4-dev-tools # 安装PyQt4
$ sudo pip install lxml # 安装lxml,如果报错,可以试试下面语句
$ sudo apt-get install python-lxml
然后打开终端,进入labelImg_master目录后使用make编译
cd labelImg-master
make all
![]()
3、使用
在labelImg-master目录下使用终端执行
python labelImg.py
 最后进行数据的标记,生成XML文件。
最后进行数据的标记,生成XML文件。
二、数据准备
1.在/home/$你的服务器命/data/VOCdevkit下建立自己的数据集名称(以我的为例,我建立的是MyDataSet)
在MyDataSet目录下需包含Annotations、ImageSets、JPEGImages三个文件夹。
Annotations 目录下存放第二步生成的xml格式数据文件。
JPEGImages 目录下存放所有的数据图片。
ImageSet 目录下包含Main文件下,在ImageSets\Main里有四个txt文件:test.txt train.txt trainval.txt val.txt;
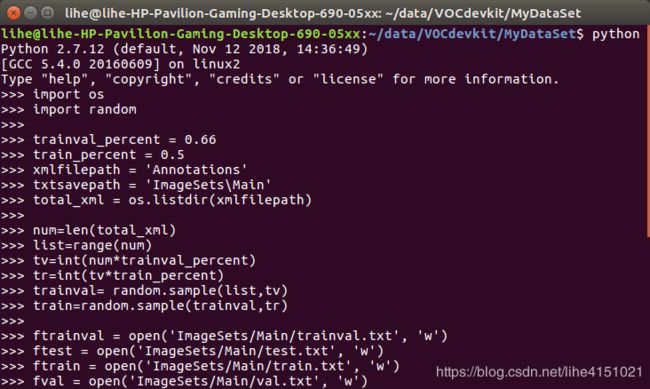
生成这四个txt文件的代码如下(Python)(注意路径):
![]()
import os
import random
trainval_percent = 0.66
train_percent = 0.5
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
2.在caffe-ssd/data目录下创建一个自己的文件夹MyDataSet(以我的为例):
cd data
mkdir MyDataSet
把data/VOC0712目录下的create_list.sh 、create_data.sh、labelmap_voc.prototxt 这三个文件拷贝到MyDataSet下(以我的为例):
cp VOC0712/create_list.sh MyDataSet/
cp VOC0712/create_data.sh MyDataSet/
cp VOC0712/labelmap_voc.prototxt MyDataSet/
3.在caffe-ssd/examples下创建MyDataSet文件夹:
mkdir MyDateSet
用于存放后续生成的lmdb文件;
4.修改labelmap_voc.prototxt文件(改成自己的类别),以及create_list.sh和create_data.sh文件中的相关路径;
labelmap_voc.prototxt需修改:
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
item {
name: "wheel"
label: 1
display_name: "wheel"
}
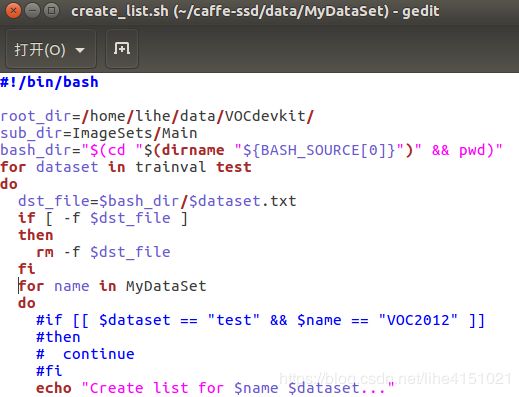
create_list.sh需修改:
root_dir=/home/lihe/data/VOCdevkit/
...
for name in MyDataSet
...
#if [[ $dataset == "test" && $name == "VOC2012" ]]
# then
# continue
# fi
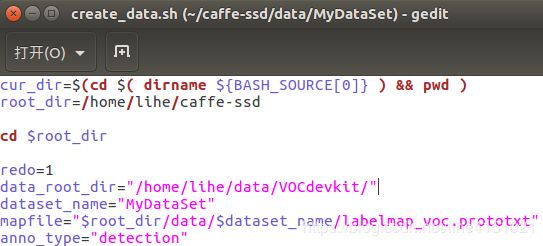
create_data.sh需修改:
root_dir=/home/lihe/caffe-ssd
data_root_dir="/home/lihe/data/VOCdevkit/"
dataset_name="MydataSet"
5.在caffe(ssd)根目录下运行命令:
./data/MyDataSet/create_list.sh
./data/MyDataSet/create_data.sh

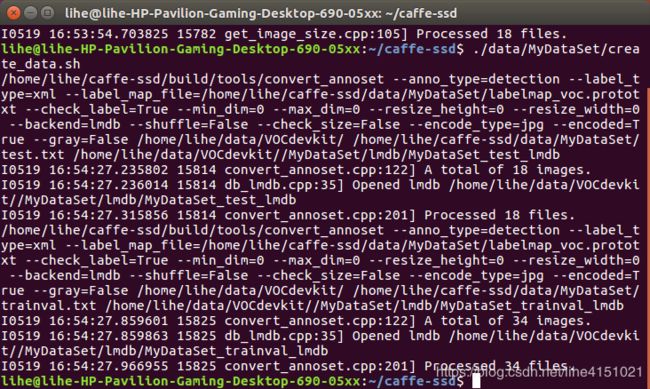
此时,在examples/MyDataSet/文件夹下可以看到两个子文件夹, MyDataSet_test_lmdb, MyDataSet_trainval_lmdb;里面均包含data.dmb和lock.dmb;
到此为止,我们的数据集就做好了。
三、数据训练
1.训练时使用ssd demo中提供的预训练好的VGGnet model
链接下载地址:https://pan.baidu.com/s/1X7gkyHnd87nv5TTqWfaR2Q 提取密码:45tm
将该模型保存到 : caffe-ssd/models/VGGNet下(没有VGGNet,就新建一个)。
2.训练程序为/examples/ssd/ssd_pascal.py,运行之前,我们需要修改相关路径代码,ssd_pascal.py作如下修改:
82行:train_data路径:
将train_data = "examples/VOC0712/VOC0712_trainval_lmdb"
修改为 :train_data = "examples/MyDataSet/MyDataSet_trainval_lmdb"
84行:test_data路径:
将test_data = "examples/VOC0712/VOC0712_test_lmdb"
修改为 :test_data = "examples/MyDataSet/MyDataSet_test_lmdb"
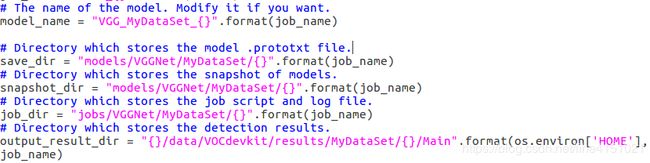
237-246行:model_name、save_dir、snapshot_dir、job_dir、output_result_dir路径:
259-263行:name_size_file、label_map_file路径;

266行:num_classes修改为1 + 类别数;
num_classes = 2
360行:num_test_image:测试集图片数目

另外, 如果你只有一个GPU, 需要修改285行: gpus=”0,1,2,3” ===> 改为”0” ,如果出现 out of memory,则将batch size 相应改小一些。
可以修改训练以及测试过程中的参数,由于我只是检测框架是否搭建成功,用到的数据集很小很小,所以参数也调的很小(不具有参考性),后期可根据自己需要调整。

3.上述修改完成后,在caffe(ssd)根目录下运行:
python ./examples/ssd/ssd_pascal.py
开始训练
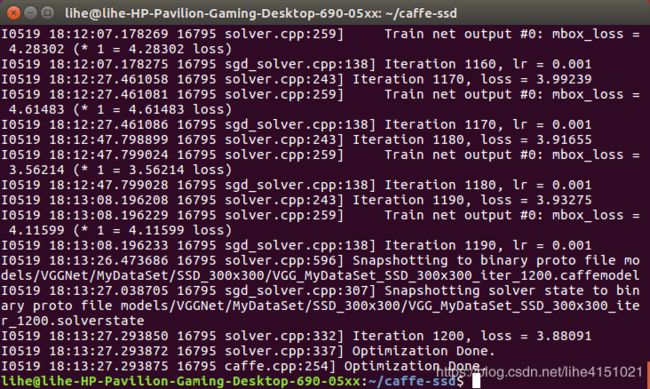
四、测试
1.测试单张图片
测试程序为/examples/ssd/ssd_detect.py,运行之前,我们需要修改相关路径代码,ssd_detect.py作如下修改:
原始路径代码:
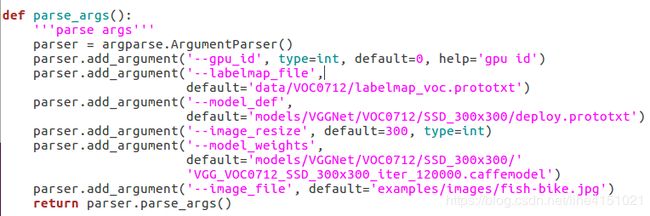
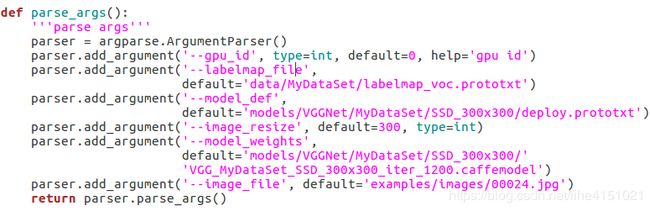
修改后路径代码:
注意:需要将待检测图片拷贝到examples/images路径下,我用到的图片为00024.jpg。
上述修改完成后,在caffe(ssd)根目录下运行:
python ./examples/ssd/ssd_detect.py
在caffe根目录下会生成检测结果图像。
2.批量检测多张图片
修改ssd_detect.py的代码(加个for循环),代码链接:https://download.csdn.net/download/yu734390853/10275197