安装配置Hadoop2.6.0(完全分布式)
我的环境是:Ubuntu14.04+Hadoop2.6.0+JDK1.8.0_25
官网2.6.0的安装教程:http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-common/SingleCluster.html
为了方面配置,我在每台机器上都使用了hadoop用户来操作,这样做的确够方便。
结点信息:(分布式集群架构:master为主节点,其余为从节点)
| 机器名 |
IP |
作用 |
| master |
122.205.135.254 |
NameNode and JobTracker |
| slave1 |
122.205.135.212 |
DataNode and TaskTracker |
1.JDK的安装
首先Hadoop运行需要Java的支持,所以必须在集群中所有的节点安装JDK,
jdk1.8.0_25的详细安装见我的另一篇文章:http://www.linuxidc.com/Linux/2015-01/112030.htm 注意:最好将集群中的JDK都安装在同一目录下,便于配置。实践中,笔者一般将JDK安装在/usr/java这个目录,但并不是必须的。
2.配置hosts文件
修改集群中所有机器的/etc/hosts,打开该文件的命令如下:
sudo gedit /etc/hosts
添加:
122.205.135.254 master
122.205.135.212 slave1
如图所示:
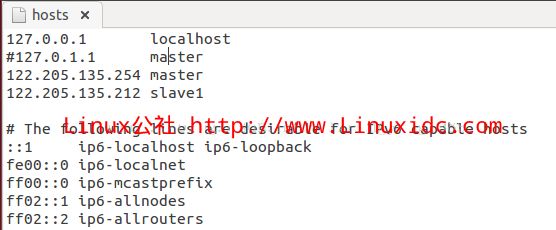
注意:这里的master、slave1、slave2等等,指的是机器的机器名(使用命令hostname可以查看本机的机器名),切记,如果不是机器名的话会出问题的,并且集群中所有结点的机器名都应该不一样。
3.SSH无密码登录
Hadoop主从节点无密码登录的安装配置详细见我的另一篇章:点击打开链接
4.Hadoop的安装与配置
(1).下载解压Hadoop稳定版
我用的是hadoop-2.6.0,下载地址:http://mirrors.hust.edu.cn/apache/hadoop/common/stable/
将下载后的Hadoop 拷贝到hadoop目录下,解压到master服务器的/hadoop目录下(配置好master结点后再将其复制到其它的服务器上,一般来说,群集中所有的hadoop都安装在同一目录下):
解压命令如下:
tar xzfv hadoop-2.6.0.tar.gz
(2).配置Hadoop
1.修改hadoop-2.6.0/etc/hadoop/hadoop-env.sh,添加JDK支持:
export JAVA_HOME=/usr/java/jdk1.8.0_25
如果不知道你的JDK目录,使用命令echo $JAVA_HOME查看。
2.修改hadoop-2.6.0/etc/hadoop/core-site.xml
注意:必须加在
3.修改hadoop-2.6.0/etc/hadoop/hdfs-site.xml
4.修改hadoop-2.6.0/etc/hadoop/mapred-site.xml
5. 修改hadoop-2.6.0/etc/hadoop/masters
列出所有的master节点:
master
6.修改hadoop-2.6.0/etc/hadoop/slaves
这个是所有datanode的机器,例如:
slave1
slave2
slave3
slave4
7.将master结点上配置好的hadoop文件夹拷贝到所有的slave结点上
以slave1为例:命令如下:
scp -r ~/hadoop-2.6.0 hadoop@slave1:~/
安装完成后,我们要格式化HDFS然后启动集群所有节点。
5.启动Hadoop
1.格式化HDFS文件系统的namenode
(这里要进入hadoop-2.6.0目录来格式化好些):
cd hadoop-2.6.0 //进入hadoop-2.6.0目录
bin/hdfs namenode -format //格式化
2.启动Hadoop集群
启动hdrs命令如下:
sbin/start-dfs.sh //开启进程
成功的话输入jps会出现如下界面:
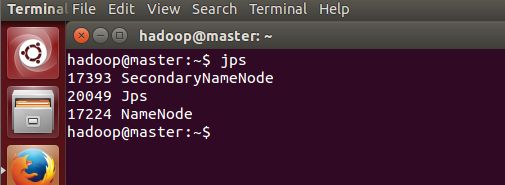
补充,关闭hdfs集群的命令如下:
sbin/stop-dfs.sh
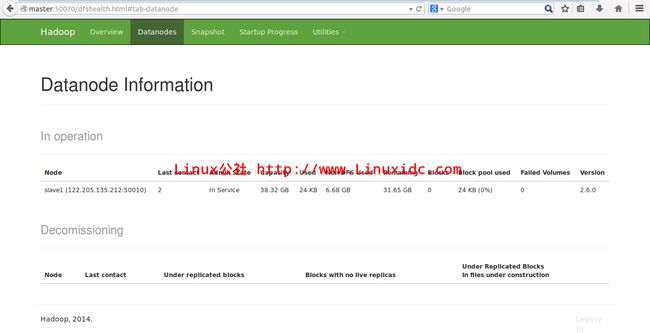
我们也可以通过网页来看是否正常安装与配置,地址如下:http://master:50070/
CentOS安装和配置Hadoop2.2.0 http://www.linuxidc.com/Linux/2014-01/94685.htm
Ubuntu 13.04上搭建Hadoop环境 http://www.linuxidc.com/Linux/2013-06/86106.htm
Ubuntu 12.10 +Hadoop 1.2.1版本集群配置 http://www.linuxidc.com/Linux/2013-09/90600.htm
Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) http://www.linuxidc.com/Linux/2013-01/77681.htm
Ubuntu下Hadoop环境的配置 http://www.linuxidc.com/Linux/2012-11/74539.htm
单机版搭建Hadoop环境图文教程详解 http://www.linuxidc.com/Linux/2012-02/53927.htm
搭建Hadoop环境(在Winodws环境下用虚拟机虚拟两个Ubuntu系统进行搭建) http://www.linuxidc.com/Linux/2011-12/48894.htm
http://www.linuxidc.com/Linux/2015-01/112029.htm