session-based recommendation有关的论文阅读记录
最近要做关于session-based recommendation有关的东西,看了一些论文,写一点阅读笔记记录一下。
督促自己快看快看!!!
用来进行session-based recommendation的算法可以如下分类:
- 不用深度学习的算法:
- item-to-item recommendation
- 马尔科夫链
- 用到深度学习的算法
- 没有用到RNN的
1) STAMP Short-Term Attention/Memory Priority Model for Session-based Recommendation - 用到RNN的
1) Session-based recommendations with recurrent neural networks
2) Personalizing session-based recommendations with hierarchical recurrent neural networks
3) Parallel recurrent neural network architectures for feature-rich session-based recommendations
4) Incorporating dwell time in session-based recommendations with recurrent Neural networks
- 没有用到RNN的
item-to-item recommendation approach
这一类主要有两篇论文,Amazon. com recommendations: Item-to-item collaborative filtering 和 Item-based collaborative filtering recommendation algorithms。这两篇文章的想法就是普通的CF想法,采用session最后一个click到的item,通过item间的相似性预测下一个item。缺点就是忽视了前面的的clicks,没有考虑整个序列信息。
Markov decision Processes
An MDP-based recommender system这篇论文主要是用到了马尔科夫链来建模。用四元组
Session-based recommendations with recurrent neural networks
这篇论文首次将RNN运用于Session-based Recommendation,针对该任务设计了RNN的训练、评估方法及ranking loss。
它用到的RNN模型是一个GRU模型,思路非常清晰,就是利用了RNN允许信息的持久化的特性,将一个session内所发生的一系列点击行为当作一个序列,完成基于item的序列建模,实现在预测阶段,把已知的点击序列作为输入,用softmax预测该session下一个最有可能点击的item。
类似于NLP中的word2vec技术,GRU将所有的itemID进行one-hot编码后输入模型中,通过embedding层,从独立高纬特征空间压缩到一个低纬的空间中,再通过一定量的GRU层、前馈层完成该session中下每一个item作为一个item发生的可能性,最后的输出结果为最有可能发生的item。
下图是一个整体的结构示意图。

其中训练过程中巧妙的提出了一种叫mini-batch的方式,还有采用了一种比较灵活的样本采样方式来实现构建负样本,降低计算量提高效率。这篇文章算是整个session-based系列的开山之作。
- mini-batch:这种构造训练样本输入模型的训练方式可以解决每个session的长度不一的问题——将不同的session横向拼接起来,然后将拼接后的数据纵向输入模型中。
第i次以拼接的batch中第i个item作为输入,拼接的batch中的第i+1个item作为目标输出;第i+1次以拼接的batch中第i+1个item作为输入,拼接的batch中的第i+2个item作为目标输出;……当一个session结束了,就重置GRU中的参数进行下一个session的训练。如下图:
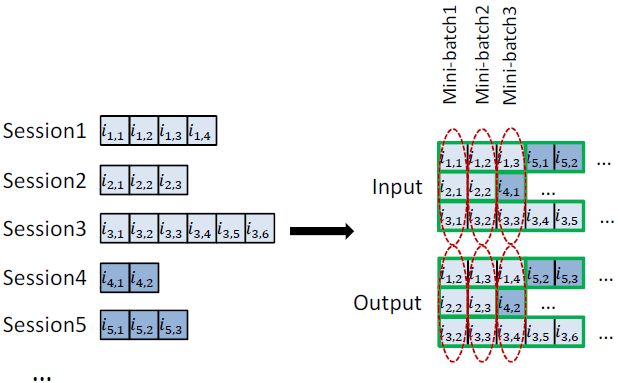
- 采样工作:首先先根据目标item所在的样本中根据热门程度进行采样,采样完成之后将同一个mini-batch中但是是其他session的next-item作为负样本,用这些正负样本来训练整个神经网络。可以参考下图:

L s = 1 N ∑ j = 1 N s σ ( r ^ s , j − r ^ s , i ) + σ ( r ^ s , j 2 ) L_s = \frac{1}{N}\sum_{j=1}^{N_s}\sigma(\hat{r}_{s,j} - \hat{r}_{s,i}) + \sigma(\hat{r}_{s,j}^{2}) Ls=N1j=1∑Nsσ(r^s,j−r^s,i)+σ(r^s,j2)
缺点:一个GRU只针对了一个session,即使是同一个用户,他的不同的session都是独立进行的建模,因此可以理解为GRUses实质上是没有考虑用户偏好的不同只对item层面进行建模。从user层面上来看每个用户的偏好不同,即使当前处于对同一个item有交互作用,但是在他们的session中下一个item就不一定相同,因此应该还需要从user层面上进行建模。因此有了后面的Personalizing session-based recommendations with hierarchical recurrent neural networks。
Personalizing session-based recommendations with hierarchical recurrent neural networks
提出一种层次化的RNN模型,在前面的Session-based recommendations with recurrent neural networks的基础上,添加了一个GRU结构来刻画session中用户个人的兴趣变化,弥补了前面模型的缺陷。
在这个算法中有两个GRU模型,一个是item-level的GRUses,一个是user-level的GRUuser。GRUses就是前面Session-based recommendations with recurrent neural networks中构建的模型,只是在这里变成了只针对同一个用户来进行的建模。
GRUses是低层级结构,GRUuser是高层级结构,每一个低层级的GRUses输出当前session中的预测结果,与此同时同一个user的不同的session的GRUses的多个输入就构成了GRUuser的输入序列,GRUuser完成user层面上的建模。下图是一个大概的结构:
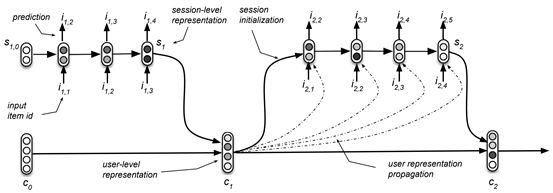
在前面的模型提出的loss function和sample上面都没有修改,只是针对前面的mini-batch进行了一些修改,提出了user parallel mini-batch——
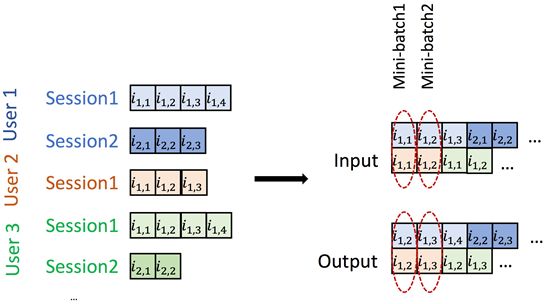
- 先根据user对session进行分组,然后将每个user下的session根据时间进行排序,再将user进行随机排序。
然后在每个user中的session中进行mini-batch: - 在一个user内,将不同的session横向拼接起来送入GRUses中(第i次以拼接的batch中第i个item作为输入,拼接的batch中的第i+1个item作为目标输出;第i+1次以拼接的batch中第i+1个item作为输入,拼接的batch中的第i+2个item作为目标输出;……),如图。当一个session结束,另一个session开始时,就将该session的最后输出输入GRUuser中进行user层面上的训练输入,同时将GRUses中的向量参数给重新初始化掉。
缺点:只用到了序列信息,其实没有考虑到用户画像和item画像对整个交互效应的影响。
Parallel recurrent neural network architectures for feature-rich session-based recommendations
将session与物品画像进行结合的算法,具体来说是将物品的一些属性信息,如文本和图像加入到RNN 框架中。
挖个坑,待填
Incorporating dwell time in session-based recommendations with recurrent Neural networks
将用户在session中item上的停留时间长短考虑进模型中进行建模。
挖个坑,待填
STAMP Short-Term Attention/Memory Priority Model for Session-based Recommendation
用MLP(没有用到RNN)构造了一个能够从当前行为中学习到用户意图的模型。
【模型思想】
从历史的点击(包括最后一次点击)信息中提取用户的general interests,对应为external memory
将attention mechanism建立在最后一次的点击的embedding向量上(提取跨session之间的信息),来代表用户的current interest,也就是short-time memory
论文先后建立了两个模型——
- STMP
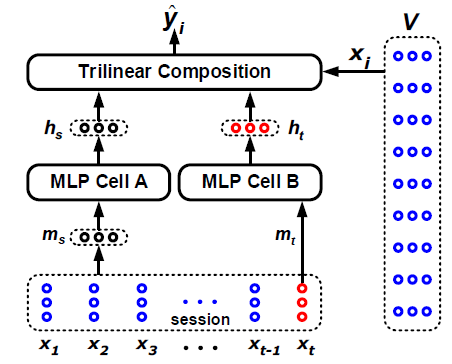
在右边的V矩阵中每一个x_i表示第i个item对应的embedding向量。
下面的session中的每一个x_t表示在这个点击的session中第t次被点击的itme。
模型中用到了两个MLP模型:
第一个MLP进行提取general interest——先用session中 [ x 1 , x 2 , . . . . . . , x t − 1 , x t ] [x_1, x_2,......, x_{t-1}, x_t] [x1,x2,......,xt−1,xt]对应的embedding向量来构建general interest,然后计算均值得到 m s = 1 t ∑ i = 1 t x i m_s = \frac{1}{t}\sum_{i=1}{t}x_i ms=t1∑i=1txi,接着通过MLP,得到 h s = f ( W s + m s + b s ) h_s = f(W_s + m_s + b_s) hs=f(Ws+ms+bs),表示general interest的输出状态;
第二个MLP进行提取current interest——直接使用session中的最后一次点击 x t x_t xt对应的embedding向量来表示当前的偏好,然后计算 m t = x t m_t = x_t mt=xt,接着通过MLP得到 h t = f ( W t + m t + b t ) h_t = f(W_t + m_t + b_t) ht=f(Wt+mt+bt),表示current interest 的输出状态。
最后为了衡量每一个item作为下一个点击对象的概率,先用一个函数计算每一个item作为下一个点击对象的输出状态值 z ^ i = σ ( ⟨ h s , h t , x i ⟩ ) = σ ( ∑ j = 1 d h s j h t j x i j ) \hat{z}_{i} = \sigma(\left\langle h_s, h_t, x_i \right\rangle) = \sigma(\sum_{j=1}^{d} h_{s_j} h_{t_j} x_{i_j} ) z^i=σ(⟨hs,ht,xi⟩)=σ(∑j=1dhsjhtjxij)
(表示的是在进行embedding的时候压缩到的维度数量。我的理解:在隐因子空间中计算每个维度上 x i x_i xi发生的一个可能性的和来最后表示用每个 x i x_i xi发生的可能),最后用softmax函数计算每个item发生的概率作为最后模型的输出 y = s o f t m a x ( z ) y=softmax(z) y=softmax(z)。
损失函数为L(y ̂ )=-∑_(i=1)^|V|▒〖y_i log(y ̂_i )+(1-y_i)log(1-y ̂_i)〗
L ( y ^ ) = − ∑ i = 1 ∣ V ∣ y i l o g ( y ^ i ) + ( 1 − y ^ i l o g ( 1 − y ^ i ) ) L (\hat{y}) = - \sum_{i=1}^{|V|}y_i log(\hat{y}_i) + (1- \hat{y}_i log(1- \hat{y}_i)) L(y^)=−i=1∑∣V∣yilog(y^i)+(1−y^ilog(1−y^i))
- STAMP
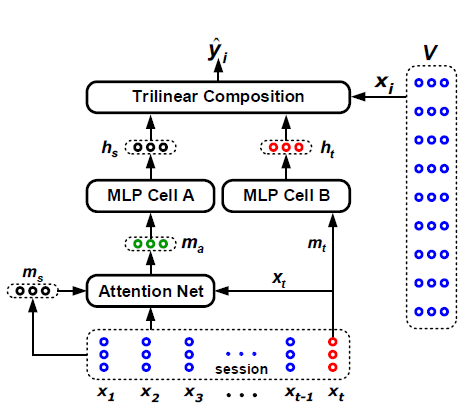
STAMP在STMP模型的基础上增加了一个attention net的结构来提取每一个item在计算general interest的时候的权重,在attention net中的实现方式如下:
每个一个itemi的权重为 α i = W 0 σ ( W 1 ) x i + W 2 x t + W 3 m s + b a \alpha_i = W_0 \sigma(W_1) x_i + W_2 x_t + W_3 m_s + b_a αi=W0σ(W1)xi+W2xt+W3ms+ba,然后通过 m a = ∑ i = 1 t α i x i m_a = \sum_{i=1} ^{t} \alpha_i x_i ma=∑i=1tαixi来计算得到根据attention加权之后的general interest。