LeNet-5 经典卷积网络模型浅析
基本的一些卷积基础可以参考:CNN基础知识(2),这里不再介绍
1. LeNet-5 卷积模型
LeNet-5 卷积模型可以达到大约99.2%的正确率,LeNet-5 模型总共有7层
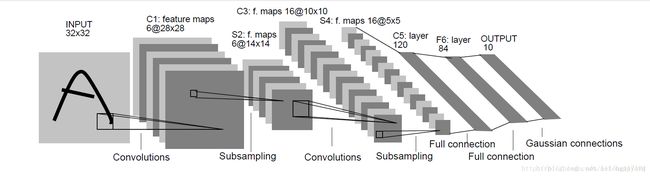
下面详细介绍LeNet-5 模型每一层的结构。
第一层,卷积层
这一层的输入是原始的图像像素,LeNet-5 模型接受的输入层大小是32x32x1。第一卷积层的过滤器的尺寸是5x5,深度(卷积核种类)为6,不使用全0填充,步长为1。因为没有使用全0填充,所以这一层的输出的尺寸为32-5+1=28,深度为6。这一层卷积层参数个数是5x5x1x6+6=156个参数(可训练参数),其中6个为偏置项参数。因为下一层的节点矩阵有有28x28x6=4704个节点(神经元数量),每个节点和5x5=25个当前层节点相连,所以本层卷积层总共有28x28x6x(5x5+1)个连接。
第二层,池化层
这一层的输入是第一层的输出,是一个28x28x6=4704的节点矩阵。本层采用的过滤器为2x2的大小,长和宽的步长均为2,所以本层的输出矩阵大小为14x14x6。原始的LeNet-5 模型中使用的过滤器和这里将用到的过滤器有些许的差别,这里不过多介绍。
第三层,卷积层
本层的输入矩阵大小为14x14x6,使用的过滤器大小为5x5,深度为16。本层不使用全0填充,步长为1。本层的输出矩阵大小为10x10x16。按照标准卷积层本层应该有5x5x6x16+16=2416个参数(可训练参数),10x10x16x(5x5+1)=41600个连接。
第四层,池化层
本层的输入矩阵大小是10x10x16,采用的过滤器大小是2x2,步长为2,本层的输出矩阵大小为5x5x16。
第五层,全连接层
本层的输入矩阵大小为5x5x16。如果将此矩阵中的节点拉成一个向量,那么这就和全连接层的输入一样了。本层的输出节点个数为120,总共有5x5x16x120+120=48120个参数。
第六层,全连接层
本层的输入节点个数为120个,输出节点个数为84个,总共参数为120x84+84=10164个。
第七层,全连接层
LeNet-5 模型中最后一层输出层的结构和全连接层的结构有区别,但这里我们用全连接层近似的表示。本层的输入节点为84个,输出节点个数为10个,总共有参数84x10+10=850个。
2.Tensorflow训练类似LeNet-5 模型的卷积网络来解决MNIST数字识别问题
(1)前向传播过程:LeNet5_infernece.py
# coding: utf-8
# In[2]:
import tensorflow as tf
# #### 1. 设定神经网络的参数
# In[ ]:
INPUT_NODE = 784 #输入层的节点数,这里是图片的像素
OUTPUT_NODE = 10 # 输出层的节点数,这里是类别的数目
IMAGE_SIZE = 28 # 图片大小
NUM_CHANNELS = 1 # 数字通道
NUM_LABELS = 10 # 数字类别
# 第一层卷积层的尺寸和深度
CONV1_DEEP = 32
CONV1_SIZE = 5
# 第二层卷积层的尺寸和深度
CONV2_DEEP = 64
CONV2_SIZE = 5
# 全连接层的节点个数
FC_SIZE = 512
# #### 2. 定义前向传播的过程
# In[ ]:
# 这里添加了一个新的参数train,用于区分训练过程和测试过程。在这个过程中将用到dropout方法,该方法可以进一步提升
# 模型的可靠性并防止过拟合,dropout过程只在训练过程中使用。
def inference(input_tensor, train, regularizer):
# 声明第一层卷积层的变量并实现前向传播过程。通过使用不同的命名空间来隔离不同层的变量,这可以让每一层中的
# 变量命名只需要考虑在当前层的作用,而不用担心重名的问题。和标准的LeNet-5模型不大一样,这里定义的卷积层输入
# 为28x28x1的原始MNIST图片像素。因为卷积层中使用了全0填充,所以输出为28x28x32的矩阵。
with tf.variable_scope('layer1-conv1'): # 在名字为layer1-conv1的命名空间内创建名字为weight的变量
conv1_weights = tf.get_variable(
"weight", [CONV1_SIZE, CONV1_SIZE, NUM_CHANNELS, CONV1_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1)) # 初始化满足正太分布的截随机数
conv1_biases = tf.get_variable("bias", [CONV1_DEEP], initializer=tf.constant_initializer(0.0))
# 使用边长为5,深度为32的过滤器,过滤器移动的步长为1,且使用全0填充。tf.nn.conv2d函数的第一个输入为当前
# 层的节点矩阵(这个矩阵是四维矩阵,第一维对应的是输入一个batch,后面三维对应一个节点矩阵)。第二个参数
# 提供了卷积层的权重,第三个参数为不同维度上的步长(虽然提供的是一个长度为4的数组,但第一维和最后一维的数字一定要是1
# 这是因为卷积层的步长只对矩阵的长和宽有效)。最后一个参数是填充,其中'SAME'表示全0填充,'VALLD'表示不添加。
conv1 = tf.nn.conv2d(input_tensor, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
# tf.nn.bias_add提供了一个方便的函数给每一个节点加上偏置项,注意这里不能直接使用加法,因为矩阵上的不同位置
# 上的节点都需要加上同样的偏置项。然后再通过RELU激活函数完成去线性化。
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
# 实现第二层池化层的前向层的传播过程。这里用的是最大池化层,池化层过滤器的边长为2,使用全0填充,并且移动的步长
# 为2.这一层的输入是上一层的输出。也就是输入为28x28x32的矩阵,输出为14x14x32的矩阵。
with tf.name_scope("layer2-pool1"):
pool1 = tf.nn.max_pool(relu1, ksize = [1,2,2,1],strides=[1,2,2,1],padding="SAME")
# 声明第三层卷积层的变量并实现前向传播过程。这一层的输入为14x14x32的矩阵,输出为14x14x64的矩阵。
with tf.variable_scope("layer3-conv2"):
conv2_weights = tf.get_variable(
"weight", [CONV2_SIZE, CONV2_SIZE, CONV1_DEEP, CONV2_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable("bias", [CONV2_DEEP], initializer=tf.constant_initializer(0.0))
# 使用边长为5,深度为64的过滤器,过滤器移动的步长为1,且使用全0填充。
conv2 = tf.nn.conv2d(pool1, conv2_weights, strides=[1, 1, 1, 1], padding='SAME')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
# 实现第四层池化层的前向传播过程。这一层和第二层的结构是一样的。这一层的输入为14x14x64的矩阵,输出为7x7x64
# 的矩阵。
with tf.name_scope("layer4-pool2"):
pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 将第四层池化层的输出转化为第五层全连接层的输入格式。第四层的输出为7x7x64的矩阵,然而第五层全连接层的
# 需要的输入格式为向量,所以这里需要将这个7x7x64的矩阵拉直成一个向量。pool2.get_shape函数可以得到第四层
# 输出矩阵的维度而不需要自己去计算,注意因为每一层神经网络的输入输出都为一个batch的矩阵,所以这里得到的维度
# 也包含了一个batch中数据的个数。
pool_shape = pool2.get_shape().as_list()
# 计算将矩阵拉直成向量之后的长度,这个长度就是矩阵长宽及深度的乘积。注意这里pool_shape[0]
# 为一个batch中数据的个数。
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
# 通过tf.reshape函数将第四层的输出变成一个batch的向量。
reshaped = tf.reshape(pool2, [pool_shape[0], nodes])
# 声明第五层全连接层的变量并实现前向传播过程。这一层的输入是拉直的一组向量,向量长度为3136,输出是一组长度为
# 512的向量。这里引入dropout的概念。dropout在训练时会随机将部分节点的输出改为0,dropout可以避免过拟合问题从而
# 可以使得模型在测试数据上的效果更好。dropout一般只在全连接层使用而不是卷积层或者池化层使用。
with tf.variable_scope('layer5-fc1'):
fc1_weights = tf.get_variable("weight", [nodes, FC_SIZE],
initializer=tf.truncated_normal_initializer(stddev=0.1))
# 只有全连接层的权重需要加入正则化
if regularizer != None:
tf.add_to_collection('losses', regularizer(fc1_weights))
fc1_biases = tf.get_variable("bias", [FC_SIZE], initializer=tf.constant_initializer(0.1))
# 通过RELU激活函数完成去线性化。其中tf.matmul实现的是矩阵乘法
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_weights) + fc1_biases)
if train:
fc1 = tf.nn.dropout(fc1, 0.5)
# 声明第六层全连接层的变量并实现前向传播过程。这一层的输入为一组长为512的向量,输出为一组长为10的向量。
# 这一层的输出通过softmax之后就得到了最后的分类结果。
with tf.variable_scope('layer6-fc2'):
fc2_weights = tf.get_variable("weight", [FC_SIZE, NUM_LABELS],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc2_weights))
fc2_biases = tf.get_variable("bias", [NUM_LABELS], initializer=tf.constant_initializer(0.1))
logit = tf.matmul(fc1, fc2_weights) + fc2_biases
# 返回第六层的输出
return logit
(2)训练过程
# coding: utf-8
# In[ ]:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import LeNet5_infernece
import os
import numpy as np
# #### 1. 定义神经网络相关的参数
# In[ ]:
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.01
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 6000
MOVING_AVERAGE_DECAY = 0.99
# #### 2. 定义训练过程
# In[ ]:
# 调整输入数据placeholder的格式,输入为一个四维的矩阵
def train(mnist):
# 定义输入为4维矩阵的placeholder
x = tf.placeholder(tf.float32,
[ BATCH_SIZE, # 第一维表示一个batch中样例的个数
LeNet5_infernece.IMAGE_SIZE, # 第二维和第三维表示图片的尺寸
LeNet5_infernece.IMAGE_SIZE,
LeNet5_infernece.NUM_CHANNELS], # 第四维表示图片的深度,对于RGB格式的图片深度是5
name='x-input')
# 定义输出的placeholder
y_ = tf.placeholder(tf.float32, [None, LeNet5_infernece.OUTPUT_NODE], name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
# 直接使用LeNet5_infernece.py中定义的前向传播过程
y = LeNet5_infernece.inference(x,False,regularizer)
global_step = tf.Variable(0, trainable=False)
# 定义损失函数、学习率、滑动平均操作以及训练过程。
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY,
staircase=True)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name='train')
# 初始化TensorFlow持久化类。
saver = tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
# 在训练过程中不再测试模型在验证数据上的表现,验证和测试的过程将会有一个独立的程序来完成。
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
reshaped_xs = np.reshape(xs, (
BATCH_SIZE,
LeNet5_infernece.IMAGE_SIZE,
LeNet5_infernece.IMAGE_SIZE,
LeNet5_infernece.NUM_CHANNELS))
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: reshaped_xs, y_: ys})
# 每1000轮输出一次当前的训练情况
if i % 100 == 0:
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
# #### 3. 主程序入口
# In[ ]:
def main(argv=None):
mnist = input_data.read_data_sets(r"C:\Users\LiLong\Desktop\MNIST_datasets", one_hot=True)
train(mnist)
if __name__ == '__main__':
main()
(3)运行结果:
Extracting C:\Users\LiLong\Desktop\MNIST_datasets\train-images-idx3-ubyte.gz
Extracting C:\Users\LiLong\Desktop\MNIST_datasets\train-labels-idx1-ubyte.gz
Extracting C:\Users\LiLong\Desktop\MNIST_datasets\t10k-images-idx3-ubyte.gz
Extracting C:\Users\LiLong\Desktop\MNIST_datasets\t10k-labels-idx1-ubyte.gz
After 1 training step(s), loss on training batch is 3.83871.
After 101 training step(s), loss on training batch is 0.869112.
After 201 training step(s), loss on training batch is 0.876754.
After 301 training step(s), loss on training batch is 0.804194.
After 401 training step(s), loss on training batch is 0.890419.
After 501 training step(s), loss on training batch is 0.774354.
After 601 training step(s), loss on training batch is 0.815839.
After 701 training step(s), loss on training batch is 0.689843.
After 801 training step(s), loss on training batch is 0.772164.
After 901 training step(s), loss on training batch is 0.776492.
After 1001 training step(s), loss on training batch is 0.699668.
After 1101 training step(s), loss on training batch is 0.8183.
After 1201 training step(s), loss on training batch is 0.751548.
After 1301 training step(s), loss on training batch is 0.688748.
After 1401 training step(s), loss on training batch is 0.653208.
After 1501 training step(s), loss on training batch is 0.678878.
...由于程序运行太慢,我把打印输出改成了100次打印一次训练的损失结果。这里只是训练模型,没有在MNIST上测试,但有实验表明该模型的效果很好,可达到99.4%的正确率。
3. 总结
然而每一总网络都不可能解决所有的问题。但有一个通用的用于图片分类的卷积神经网络架构:输入层—>(卷积层+—>池化层?)+—>全连接层+
其中“+”表示一个或多个,“?”表示没有或者一个。
有了卷积网络的架构,那么每一层卷积层或者池化层中的配置需要如何设置呢?其实是没有一个标准的,经验总结是这样的:
- 卷积层的过滤器边长不会超过5,一般为3或者1,但也有些卷积神经网络中处理输入的卷积层中使用了边长为7,甚至为11的过滤器。
- 过滤器的深度大部分卷积神经网络都采用逐层递增的方式。卷积层的步长一般为1,但是在有些模型中也会使用2,或者3作为步长。
- 池化层的配置相对简单些,用的最多的是最大池化层,池化层的过滤器边长一般为2或者3,步长也一般为2或者3。
参考:《Tensorflow实战Google深度学习框架》