hbase常用命令,留存
hbase shell命令
描述
alter
修改列族(column family)模式
count
统计表中行的数量
create
创建表
describe
显示表相关的详细信息
delete
删除指定对象的值(可以为表,行,列对应的值,另外也可以指定时间戳的值)
deleteall
删除指定行的所有元素值
disable
使表无效
drop
删除表
enable
使表有效
exists
测试表是否存在
exit
退出hbase shell
get
获取行或单元(cell)的值
incr
增加指定表,行或列的值
list
列出hbase中存在的所有表
put
向指向的表单元添加值
tools
列出hbase所支持的工具
scan
通过对表的扫描来获取对用的值
status
返回hbase集群的状态信息
shutdown
关闭hbase集群(与exit不同)
truncate
重新创建指定表
version
返回hbase版本信息
要注意shutdown与exit之间的不同:shutdown表示关闭hbase服务,必须重新启动hbase才可以恢复,exit只是退出hbase shell,退出之后完全可以重新进入。
hbase使用坐标来定位表中的数据,行健是第一个坐标,下一个坐标是列族。
hbase是一个在线系统,和hadoop mapreduce的紧密结合又赋予它离线访问的功能。
hbase接到命令后存下变化信息或者写入失败异常的抛出,默认情况下。执行写入时会写到两个地方:预写式日志(write-ahead log,也称hlog)和memstore,以保证数据持久化 。memstore 是内存 里的写入缓冲区。客户端在写的过程中不会与底层的hfile直接交互,当menstore写满时,会刷新到硬盘,生成一个新的hfile.hfile是hbase使用的底层存储格式。menstore的大小由hbase-si te.xml 文件里的系统级属性 hbase.hregion.memstore.flush.size 来定义 。
hbase在读操作上使用了lru缓存机制(blockcache),blockcache设计用来保存从hfile里读入内存的频繁访问的数据,避免硬盘读。每个列族都有自己的blockcache。blockcache中的block是hbase从硬盘完成一次读取的数据单位。block是建立索引的最小数据单位,也是从硬盘读取的最小数据单位。如果主要用于随机查询,小一点的block会好一些,但是会导致索引变大,消耗更多内存,如果主要执行顺序扫描,大一点的block会好一些,block变大索引项变小,因此节省内存。
LRU是Least Recently Used 近期最少使用算法。内存管理的一种页面置换算法,对于在内存中但又不用的数据块(内存块)叫做LRU,操作系统会根据哪些数据属于LRU而将其移出内存而腾出空间来加载另外的数据。
数据模型概括:
表(table) ---------hbase用表来组织数据。表名是字符串(string),由可以在文件系统路径里使用的字符组成。
行(row) ---------在表里,数据按行存储。行由行健(rowkey)唯一标识。行健没有数据类型,总是视为字节数组byte[].
列族(column family) -----------行里的数据按照列族分组,列族也影响到hbase数据的物理存放。因此,它们必须事前定义并且不轻易修改。表中每行拥有相同列族,尽管行不需要在每个列族里存储数据。列族名字是字符串,由可以在文件系统路径里使用的字符组成。(HBase建表是可以添加列族,alter 't1', {NAME => 'f1', VERSIONS => 5} 把表disable后alter,然后enable)
列限定符(column qualifier) --------列族里的数据通过列限定符或列来定位。列限定符不必事前定义。列限定符不必在不同行之间保持一致,就像行健一样,列限定符没有数据类型,总是视为字节数组byte[].
单元(cell)-------行健,列族和列限定符一起确定一个单元。存储在单元里的数据称为单元值(value),值也没有数据类型,总是视为字节数组byte[].
时间版本(version)--------单元值有时间版本,时间版本用时间戳标识,是一个long。没有指定时间版本时,当前时间戳作为操作的基本。hbase保留单元值时间版本的数量基于列族进行配置。默认数量是3个 。
hbase在表里存储数据使用的是四维坐标系统,依次是:行健,列族,列限定符和时间版本 。 hbase按照时间戳降序排列各时间版本,其他映射建按照升序排序。
hbase把数据存放在一个提供单一命名空间的分布式文件系统上。一张表由多个小一点的region组成,托管region的服务器叫做regionserver.单个region大小由配置参数hbase.hregion.max.filesize决定,当一个region大小变得大于该值时,会切分成2个region.
hbase是一种搭建在hadoop上的数据库。依靠hadoop来实现数据访问和数据可靠性。hbase是一种以低延迟为目标的在线系统,而hadoop是一种为吞吐量优化的离线系统。互补可以搭建水平扩展的数据应用。
HBASE中的表示按column family来存储的
hbase表设计:
hbase表很灵活,可以用字符数组形式存储任何东西。在同一列族里存储相似访问模式的所有东西。
索引建立在keyvalue对象的key部分上,key由行健,列限定符和时间戳按次序组成。高表可能支持你把运算复杂度降到o(1),但是要在原子性上付出代价。
hbase不支持跨行事务,列限定符可以用来存储数据,列族名字的长度影响了通过网络传回客户端的数据大小(在keyvalue对象里),所以尽量简练。
散列支持定长键和更好的数据分布,但是失去排序的好处。设计hbase模式时进行反规范化处理是一种可行的办法。从性能观点看,规范化为写做优化,而反规范化为读做优化。
进入hbase shell console
hbase(main)> whoami
表的管理
hbase(main)> list
2)创建表,其中t1是表名,f1、f2是t1的列族。hbase中的表至少有一个列族.它们之中,列族直接影响hbase数据存储的物理特性。create , {NAME => , VERSIONS => }hbase(main)> create 't1',{NAME => 'f1', VERSIONS => 2},{NAME => 'f2', VERSIONS => 2}
3)删除表
hbase(main)> drop 't1'
4)查看表的结构
(可以看到这个表的所有默认参数)hbase(main)> describe 't1' / desc 't1'
5)修改表结构
hbase(main)> enable 'test1'
权限管理
1)分配权限
# 语法 : grant 参数后面用逗号分隔
# 权限用五个字母表示: "RWXCA".
# READ('R'), WRITE('W'), EXEC('X'), CREATE('C'), ADMIN('A')
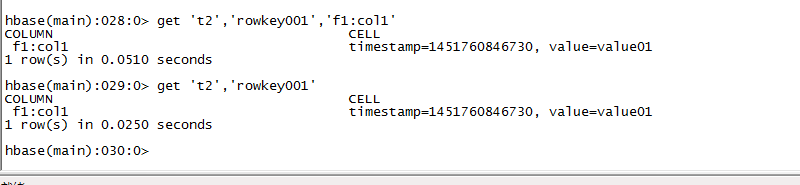
,,,,hbase(main)> put 't1','rowkey001','f1:col1','value01'
用法比较单一。
,,[,....]hbase(main)> get 't1','rowkey001'
b)扫描表
, {COLUMNS => [ ,.... ], LIMIT => num}, {INTERVAL => intervalNum, CACHE => cacheNum}, , , ,必须指定列名, , , ,可以不指定列名,删除整行数据
示例如下
此表有两个列族,CF1和CF2,其中CF1和CF2下分别有两个列name和gender,Chinese和Math
hbase(main):041:0> create 'hbase_1102', {NAME=>'cf1'}, {NAME=>'cf2'}2,向表中添加数据,在想HBase的表中添加数据的时候,只能一列一列的添加,不能同时添加多列。
hbase(main):042:0> put'hbase_1102', '001','cf1:name','Tom'
hbase(main):043:0> put'hbase_1102', '001','cf1:gender','man'
hbase(main):044:0> put'hbase_1102', '001','cf2:chinese','90'
hbase(main):045:0> put'hbase_1102', '001','cf2:math','91'
这样表结构就起来了,其实比较自由,列族里边可以自由添加子列很方便。如果列族下没有子列,加不加冒号都是可以的。
如果在添加数据的时候,需要手动的设置时间戳,则在put命令的最后加上相应的时间戳,时间戳是long类型的,所以不需要加引号
hbase(main):045:0> put'hbase_1102', '001','cf2:math','91',14780538324593,查看表中的所有数据
hbase(main):046:0> scan 'hbase_1102'
ROW COLUMN+CELL
001 column=cf1:gender, timestamp=1478053832459, value=man
001 column=cf1:name, timestamp=1478053787178, value=Tom
001 column=cf2:chinese, timestamp=1478053848225, value=90
001 column=cf2:math, timestamp=1478053858144, value=911
row(s) in0.0140seconds4,查看其中某一个Key的数据
hbase(main):048:0> get'hbase_1102','001'
COLUMN CELL
cf1:gender timestamp=1478053832459, value=man
cf1:name timestamp=1478053787178, value=Tom
cf2:chinese timestamp=1478053848225, value=90
cf2:math timestamp=1478053858144, value=914 row(s) in0.0290seconds转自:http://my.oschina.net/u/189445/blog/595232
你可能感兴趣的:(Hbase)
nosql数据库技术与应用知识点
皆过客,揽星河
NoSQL nosql 数据库 大数据 数据分析 数据结构 非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
浅谈MapReduce
Android路上的人
Hadoop 分布式计算 mapreduce 分布式 框架 hadoop
从今天开始,本人将会开始对另一项技术的学习,就是当下炙手可热的Hadoop分布式就算技术。目前国内外的诸多公司因为业务发展的需要,都纷纷用了此平台。国内的比如BAT啦,国外的在这方面走的更加的前面,就不一一列举了。但是Hadoop作为Apache的一个开源项目,在下面有非常多的子项目,比如HDFS,HBase,Hive,Pig,等等,要先彻底学习整个Hadoop,仅仅凭借一个的力量,是远远不够的。
hbase介绍
CrazyL-
云计算+大数据 hbase
hbase是一个分布式的、多版本的、面向列的开源数据库hbase利用hadoophdfs作为其文件存储系统,提供高可靠性、高性能、列存储、可伸缩、实时读写、适用于非结构化数据存储的数据库系统hbase利用hadoopmapreduce来处理hbase、中的海量数据hbase利用zookeeper作为分布式系统服务特点:数据量大:一个表可以有上亿行,上百万列(列多时,插入变慢)面向列:面向列(族)的
Apache HBase基础(基本概述,物理架构,逻辑架构,数据管理,架构特点,HBase Shell)
May--J--Oldhu
HBase HBase shell hbase物理架构 hbase逻辑架构 hbase
NoSQL综述及ApacheHBase基础一.HBase1.HBase概述2.HBase发展历史3.HBase应用场景3.1增量数据-时间序列数据3.2信息交换-消息传递3.3内容服务-Web后端应用程序3.4HBase应用场景示例4.ApacheHBase生态圈5.HBase物理架构5.1HMaster5.2RegionServer5.3Region和Table6.HBase逻辑架构-Row7.
HBase(一)——HBase介绍
weixin_30595035
大数据 数据库 数据结构与算法
HBase介绍1、关系型数据库与非关系型数据库(1)关系型数据库关系型数据库最典型的数据机构是表,由二维表及其之间的联系所组成的一个数据组织优点:1、易于维护:都是使用表结构,格式一致2、使用方便:SQL语言通用,可用于复杂查询3、复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询缺点:1、读写性能比较差,尤其是海量数据的高效率读写2、固定的表结构,灵活度稍欠3、高并发读写需求,传统关
HBase介绍
mingyu1016
数据库
概述HBase是一个分布式的、面向列的开源数据库,源于google的一篇论文《bigtable:一个结构化数据的分布式存储系统》。HBase是GoogleBigtable的开源实现,它利用HadoopHDFS作为其文件存储系统,利用HadoopMapReduce来处理HBase中的海量数据,利用Zookeeper作为协同服务。HBase的表结构HBase以表的形式存储数据。表有行和列组成。列划分为
Hbase - 迁移数据[导出,导入]
kikiki5
>有没有这样一样情况,把一个集群中的某个表导到另一个群集中,或者hbase的表结构发生了更改,但是数据还要,比如预分区没做,导致某台RegionServer很吃紧,Hbase的导出导出都可以很快的完成这些操作。-LOOKING_UP_SERVER>>>KdcAccessibility:removestorm1.starsriver.cnatsun.security.krb5.KrbTg
kvm 虚拟机命令行虚拟机操作、制作快照和恢复快照以及工作常用总结
西京刀客
云原生(Cloud Native) 云计算 虚拟化 Linux C/C++ 服务器 linux kvm
文章目录kvm虚拟机命令行虚拟机操作、制作快照和恢复快照一、kvm虚拟机命令行虚拟机操作(创建和删除)查看虚拟机virt-install创建一个虚拟机关闭虚拟机重启虚拟机销毁虚拟机二、kvm制作快照和恢复快照**创建快照**工作常见问题创建快照报错::internalsnapshotsofaVMwithpflashbasedfirmwarearenotsupported检查虚拟机是否包含pflas
hadoop 0.22.0 部署笔记
weixin_33701564
大数据 java 运维
为什么80%的码农都做不了架构师?>>>因为需要使用hbase,所以开始对hbase进行学习。hbase是部署在hadoop平台上的NOSql数据库,因此在部署hbase之前需要先部署hadoop。环境:redhat5、hadoop-0.22.0.tar.gz、jdk-6u13-linux-i586.zipip192.168.1.128hostname:localhost.localdomain(
实时数仓之实时数仓架构(Hudi)(1),2024年最新熬夜整理华为最新大数据开发笔试题
2401_84181221
程序员 架构 大数据
+Hudi:湖仓一体数据管理框架,用来管理模型数据,包括ODS/DWD/DWS/DIM/ADS等;+Doris:OLAP引擎,同步数仓结果模型,对外提供数据服务支持;+Hbase:用来存储维表信息,维表数据来源一部分有Flink加工实时写入,另一部分是从Spark任务生产,其主要作用用来支持FlinkETL处理过程中的LookupJoin功能。这里选用Hbase原因主要因为Table的HbaseC
HBase 源码阅读(一)
Such Devotion
hbase 数据库 大数据
1.HMastermain方法在上文中MacosM1IDEA本地调试HBase2.2.2,我们使用HMaster的主函数使用"start"作为入参,启动了HMaster进程这里我们再深入了解下HMaster的运行机理publicstaticvoidmain(String[]args){LOG.info("STARTINGservice"+HMaster.class.getSimpleName())
HBase 源码阅读(四)HBase 关于LSM Tree的实现- MemStore
Such Devotion
hbase lsm-tree 数据库
4.MemStore接口Memstore的函数不能并行的被调用。调用者需要持有读写锁,这个的实现在HStore中我们放弃对MemStore中的诸多函数进行查看直接看MemStore的实现类AbstractMemStoreCompactingMemStoreDefaultMemStore4.1三个实现类的使用场景1.AbstractMemStore角色:基础抽象类作用:AbstractMemStor
大数据(Hbase简单示例)
BL小二
hbase 大数据 hadoop
importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.hbase.HBaseConfiguration;importorg.apache.hadoop.hbase.TableName;importorg.apache.hadoop.hbase.client.*;importorg.apache.hadoop.hbase
Hbase的简单使用示例
傲雪凌霜,松柏长青
后端 大数据 hbase 数据库 大数据
HBase是基于HadoopHDFS构建的分布式、列式存储的NoSQL数据库,适用于存储和检索超大规模的非结构化数据。它支持随机读写,并且能够处理PB级数据。HBase通常用于实时数据存取场景,与Hadoop生态紧密集成。使用HBase的Java示例前置条件HBase集群:确保HBase集群已经安装并启动。如果没有,你可以通过本地伪分布模式或Docker来运行HBase。Hadoop配置:HBas
快手HBase在千亿级用户特征数据分析中的应用与实践
王知无
声明:本文的原文是来自Hbase技术社区的一个PPT分享,个人做了整理和提炼。大家注意哈,这种会议PPT类的东西能学习到的更多的是技术方案和他人在实践过程中的经验。希望对大家有帮助。背景快手每天产生数百亿用户特征数据,分析师需要在跨30-90天的数千亿特征数据中,任意选择多维度组合(如:城市=北京&性别=男),秒级分析用户行为。针对这一需求,快手基于HBase自主研发了支持bitmap转化、存储、
ClickHouse与其他数据库的对比
九州Pro
ClickHouse 数据库 clickhouse 数据仓库 大数据 sql
目录1与传统关系型数据库的对比1.1性能差异1.2数据模型差异1.3适用场景差异2与其他列式存储数据库的对比2.1ApacheCassandra2.2HBase3与分布式数据库的对比3.1GoogleBigQuery3.2AmazonRedshift3.3Snowflake4ClickHouse的缺点5ClickHouse的其他优点1与传统关系型数据库的对比1.1性能差异ClickHouse是一种
Hbase、hive以及ClickHouse的介绍和区别?
damokelisijian866
hbase hive clickhouse
一、Hbase介绍:HBase是一个分布式的、面向列的开源数据库,由ApacheSoftwareFoundation开发,是Hadoop生态系统中的一个重要组件。HBase的设计灵感来源于Google的Bigtable论文,它通过提供类似于Bigtable的能力,在Hadoop之上构建了一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。HBase主要用于存储大量结构化数据,并支持随机读写访问,
Hive和Hbase的区别
傲雪凌霜,松柏长青
大数据 后端 hive hbase hadoop
Hive和HBase都是Hadoop生态系统中的重要组件,它们都能处理大规模数据,但各自有不同的适用场景和设计理念。以下是两者的主要区别:1.数据模型Hive:Hive类似于传统的关系型数据库(RDBMS),以表格形式存储数据。它使用SQL-like语言HiveQL来查询和处理数据,数据通常是结构化或半结构化的。HBase:HBase是一个NoSQL数据库,基于Google的BigTable模型。
HBase
傲雪凌霜,松柏长青
大数据 后端 hbase 数据库 大数据
ApacheHBase是一个基于Hadoop分布式文件系统(HDFS)构建的分布式、面向列的NoSQL数据库,主要用于处理大规模、稀疏的表结构数据。HBase的设计灵感来自Google的Bigtable,能够在海量数据中提供快速的随机读写操作,适合需要低延迟和高吞吐量的应用场景。HBase核心概念表(Table):HBase的数据存储在表中,与传统的关系型数据库不同,HBase的表是面向列族(Co
大数据面试题:说下为什么要使用Hive?Hive的优缺点?Hive的作用是什么?
蓦然_
大数据面试题 hive 大数据开发面试题 大数据面试
1、为什么要使用Hive?Hive是Hadoop生态系统中比不可少的一个工具,它提供了一种SQL(结构化查询语言)方言,可以查询存储在Hadoop分布式文件系统(HDFS)中的数据或其他和Hadoop集成的文件系统,如MapR-FS、Amazon的S3和像HBase(Hadoop数据仓库)和Cassandra这样的数据库中的数据。大多数数据仓库应用程序都是使用关系数据库进行实现的,并使用SQL作为
Hadoop组件
静听山水
Hadoop hadoop
这张图片展示了Hadoop生态系统的一些主要组件。Hadoop是一个开源的大数据处理框架,由Apache基金会维护。以下是每个组件的简短介绍:HBase:一个分布式、面向列的NoSQL数据库,基于GoogleBigTable的设计理念构建。HBase提供了实时读写访问大量结构化和半结构化数据的能力,非常适合大规模数据存储。Pig:一种高级数据流语言和执行引擎,用于编写MapReduce任务。Pig
Hbase BulkLoad用法
kikiki2
要导入大量数据,Hbase的BulkLoad是必不可少的,在导入历史数据的时候,我们一般会选择使用BulkLoad方式,我们还可以借助Spark的计算能力将数据快速地导入。使用方法导入依赖包compilegroup:'org.apache.spark',name:'spark-sql_2.11',version:'2.3.1.3.0.0.0-1634'compilegroup:'org.apach
EMR组件部署指南
ivwdcwso
运维 EMR 大数据 开源 运维
EMR(ElasticMapReduce)是一个大数据处理和分析平台,包含了多个开源组件。本文将详细介绍如何部署EMR的主要组件,包括:JDK1.8ElasticsearchKafkaFlinkZookeeperHBaseHadoopPhoenixScalaSparkHive准备工作所有操作都在/data目录下进行。首先安装JDK1.8:yuminstalljava-1.8.0-openjdk部署
Sublime text3+python3配置及插件安装
raysonfang
作者:方雷个人博客:http://blog.chargingbunk.cn/微信公众号:rayson_666(Rayson开发分享)个人专研技术方向:微服务方向:springboot,springCloud,Dubbo分布式/高并发:分布式锁,消息队列RabbitMQ大数据处理:Hadoop,spark,HBase等python方向:pythonweb开发一,前言在网上搜索了一些Python开发的
Spring Data:JPA与Querydsl
光图强
java
JPAJPA是java的一个规范,用于在java对象和数据库之间保存数据,充当面向对象领域模型和数据库之间的桥梁。它使用Hibernate、TopLink、IBatis等ORM框架实现持久性规范。SpringDataSpringData是Spring的一个子项目,用于简化数据库访问,支持NoSql数据和关系数据库。支持的NoSql数据库包括:Mongodb、redis、Hbase、Neo4j。Sp
HBase 源码阅读(二)
Such Devotion
hbase 数据库 大数据
衔接在上一篇文章中,HMasterCommandLine类中在startMaster();方法中//这里除了启动HMaster之外,还启动一个HRegionServerLocalHBaseClustercluster=newLocalHBaseCluster(conf,mastersCount,regionServersCount,LocalHMaster.class,HRegionServer.
大数据技术之HBase 与 Hive 集成(7)
大数据深度洞察
Hbase 大数据 hbase hive
目录使用场景HBase与Hive集成使用1)案例一2)案例二使用场景如果大量的数据已经存放在HBase上面,并且需要对已经存在的数据进行数据分析处理,那么Phoenix并不适合做特别复杂的SQL处理。此时,可以使用Hive映射HBase的表格,之后通过编写HQL进行分析处理。HBase与Hive集成使用Hive安装https://blog.csdn.net/qq_45115959/article/
【HBase之轨迹】(1)使用 Docker 搭建 HBase 集群
寒冰小澈IceClean
【大数据之轨迹】 【Docker之轨迹】 笔记 hbase docker hadoop
——目录——0.前置准备1.下载安装2.配置(重)3.启动与关闭4.搭建高可用HBase前言(贫穷使我见多识广)前边经历了Hadoop,Zookeeper,Kafka,他们的集群,全都是使用Docker搭建的一开始的我认为,把容器看成是一台台独立的服务器就好啦也确实是这样,但端口映射问题,让我一路以来磕碰了太多太多,直到现在的HBase,更是将Docker集群所附带的挑战性,放大到了极致(目前是如
深入浅出Java Annotation(元注解和自定义注解)
Josh_Persistence
Java Annotation 元注解 自定义注解
一、基本概述
Annontation是Java5开始引入的新特征。中文名称一般叫注解。它提供了一种安全的类似注释的机制,用来将任何的信息或元数据(metadata)与程序元素(类、方法、成员变量等)进行关联。
更通俗的意思是为程序的元素(类、方法、成员变量)加上更直观更明了的说明,这些说明信息是与程序的业务逻辑无关,并且是供指定的工具或
mysql优化特定类型的查询
annan211
java 工作 mysql
本节所介绍的查询优化的技巧都是和特定版本相关的,所以对于未来mysql的版本未必适用。
1 优化count查询
对于count这个函数的网上的大部分资料都是错误的或者是理解的都是一知半解的。在做优化之前我们先来看看
真正的count()函数的作用到底是什么。
count()是一个特殊的函数,有两种非常不同的作用,他可以统计某个列值的数量,也可以统计行数。
在统
MAC下安装多版本JDK和切换几种方式
棋子chessman
jdk
环境:
MAC AIR,OS X 10.10,64位
历史:
过去 Mac 上的 Java 都是由 Apple 自己提供,只支持到 Java 6,并且OS X 10.7 开始系统并不自带(而是可选安装)(原自带的是1.6)。
后来 Apple 加入 OpenJDK 继续支持 Java 6,而 Java 7 将由 Oracle 负责提供。
在终端中输入jav
javaScript (1)
Array_06
JavaScript java 浏览器
JavaScript
1、运算符
运算符就是完成操作的一系列符号,它有七类: 赋值运算符(=,+=,-=,*=,/=,%=,<<=,>>=,|=,&=)、算术运算符(+,-,*,/,++,--,%)、比较运算符(>,<,<=,>=,==,===,!=,!==)、逻辑运算符(||,&&,!)、条件运算(?:)、位
国内顶级代码分享网站
袁潇含
java jdk oracle .net PHP
现在国内很多开源网站感觉都是为了利益而做的
当然利益是肯定的,否则谁也不会免费的去做网站
&
Elasticsearch、MongoDB和Hadoop比较
随意而生
mongodb hadoop 搜索引擎
IT界在过去几年中出现了一个有趣的现象。很多新的技术出现并立即拥抱了“大数据”。稍微老一点的技术也会将大数据添进自己的特性,避免落大部队太远,我们看到了不同技术之间的边际的模糊化。假如你有诸如Elasticsearch或者Solr这样的搜索引擎,它们存储着JSON文档,MongoDB存着JSON文档,或者一堆JSON文档存放在一个Hadoop集群的HDFS中。你可以使用这三种配
mac os 系统科研软件总结
张亚雄
mac os
1.1 Microsoft Office for Mac 2011
大客户版,自行搜索。
1.2 Latex (MacTex):
系统环境:https://tug.org/mactex/
&nb
Maven实战(四)生命周期
AdyZhang
maven
1. 三套生命周期 Maven拥有三套相互独立的生命周期,它们分别为clean,default和site。 每个生命周期包含一些阶段,这些阶段是有顺序的,并且后面的阶段依赖于前面的阶段,用户和Maven最直接的交互方式就是调用这些生命周期阶段。 以clean生命周期为例,它包含的阶段有pre-clean, clean 和 post
Linux下Jenkins迁移
aijuans
Jenkins
1. 将Jenkins程序目录copy过去 源程序在/export/data/tomcatRoot/ofctest-jenkins.jd.com下面 tar -cvzf jenkins.tar.gz ofctest-jenkins.jd.com &
request.getInputStream()只能获取一次的问题
ayaoxinchao
request Inputstream
问题:在使用HTTP协议实现应用间接口通信时,服务端读取客户端请求过来的数据,会用到request.getInputStream(),第一次读取的时候可以读取到数据,但是接下来的读取操作都读取不到数据
原因: 1. 一个InputStream对象在被读取完成后,将无法被再次读取,始终返回-1; 2. InputStream并没有实现reset方法(可以重
数据库SQL优化大总结之 百万级数据库优化方案
BigBird2012
SQL优化
网上关于SQL优化的教程很多,但是比较杂乱。近日有空整理了一下,写出来跟大家分享一下,其中有错误和不足的地方,还请大家纠正补充。
这篇文章我花费了大量的时间查找资料、修改、排版,希望大家阅读之后,感觉好的话推荐给更多的人,让更多的人看到、纠正以及补充。
1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where
jsonObject的使用
bijian1013
java json
在项目中难免会用java处理json格式的数据,因此封装了一个JSONUtil工具类。
JSONUtil.java
package com.bijian.json.study;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
[Zookeeper学习笔记之六]Zookeeper源代码分析之Zookeeper.WatchRegistration
bit1129
zookeeper
Zookeeper类是Zookeeper提供给用户访问Zookeeper service的主要API,它包含了如下几个内部类
首先分析它的内部类,从WatchRegistration开始,为指定的znode path注册一个Watcher,
/**
* Register a watcher for a particular p
【Scala十三】Scala核心七:部分应用函数
bit1129
scala
何为部分应用函数?
Partially applied function: A function that’s used in an expression and that misses some of its arguments.For instance, if function f has type Int => Int => Int, then f and f(1) are p
Tomcat Error listenerStart 终极大法
ronin47
tomcat
Tomcat报的错太含糊了,什么错都没报出来,只提示了Error listenerStart。为了调试,我们要获得更详细的日志。可以在WEB-INF/classes目录下新建一个文件叫logging.properties,内容如下
Java代码
handlers = org.apache.juli.FileHandler, java.util.logging.ConsoleHa
不用加减符号实现加减法
BrokenDreams
实现
今天有群友发了一个问题,要求不用加减符号(包括负号)来实现加减法。
分析一下,先看最简单的情况,假设1+1,按二进制算的话结果是10,可以看到从右往左的第一位变为0,第二位由于进位变为1。
读《研磨设计模式》-代码笔记-状态模式-State
bylijinnan
java 设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/*
当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变了其类
状态模式主要解决的是当控制一个对象状态的条件表达式过于复杂时的情况
把状态的判断逻辑转移到表示不同状态的一系列类中,可以把复杂的判断逻辑简化
如果在
CUDA程序block和thread超出硬件允许值时的异常
cherishLC
CUDA
调用CUDA的核函数时指定block 和 thread大小,该大小可以是dim3类型的(三维数组),只用一维时可以是usigned int型的。
以下程序验证了当block或thread大小超出硬件允许值时会产生异常!!!GPU根本不会执行运算!!!
所以验证结果的正确性很重要!!!
在VS中创建CUDA项目会有一个模板,里面有更详细的状态验证。
以下程序在K5000GPU上跑的。
诡异的超长时间GC问题定位
chenchao051
jvm cms GC hbase swap
HBase的GC策略采用PawNew+CMS, 这是大众化的配置,ParNew经常会出现停顿时间特别长的情况,有时候甚至长到令人发指的地步,例如请看如下日志:
2012-10-17T05:54:54.293+0800: 739594.224: [GC 739606.508: [ParNew: 996800K->110720K(996800K), 178.8826900 secs] 3700
maven环境快速搭建
daizj
安装 mavne 环境配置
一 下载maven
安装maven之前,要先安装jdk及配置JAVA_HOME环境变量。这个安装和配置java环境不用多说。
maven下载地址:http://maven.apache.org/download.html,目前最新的是这个apache-maven-3.2.5-bin.zip,然后解压在任意位置,最好地址中不要带中文字符,这个做java 的都知道,地址中出现中文会出现很多
PHP网站安全,避免PHP网站受到攻击的方法
dcj3sjt126com
PHP
对于PHP网站安全主要存在这样几种攻击方式:1、命令注入(Command Injection)2、eval注入(Eval Injection)3、客户端脚本攻击(Script Insertion)4、跨网站脚本攻击(Cross Site Scripting, XSS)5、SQL注入攻击(SQL injection)6、跨网站请求伪造攻击(Cross Site Request Forgerie
yii中给CGridView设置默认的排序根据时间倒序的方法
dcj3sjt126com
GridView
public function searchWithRelated() {
$criteria = new CDbCriteria;
$criteria->together = true; //without th
Java集合对象和数组对象的转换
dyy_gusi
java集合
在开发中,我们经常需要将集合对象(List,Set)转换为数组对象,或者将数组对象转换为集合对象。Java提供了相互转换的工具,但是我们使用的时候需要注意,不能乱用滥用。
1、数组对象转换为集合对象
最暴力的方式是new一个集合对象,然后遍历数组,依次将数组中的元素放入到新的集合中,但是这样做显然过
nginx同一主机部署多个应用
geeksun
nginx
近日有一需求,需要在一台主机上用nginx部署2个php应用,分别是wordpress和wiki,探索了半天,终于部署好了,下面把过程记录下来。
1. 在nginx下创建vhosts目录,用以放置vhost文件。
mkdir vhosts
2. 修改nginx.conf的配置, 在http节点增加下面内容设置,用来包含vhosts里的配置文件
#
ubuntu添加admin权限的用户账号
hongtoushizi
ubuntu useradd
ubuntu创建账号的方式通常用到两种:useradd 和adduser . 本人尝试了useradd方法,步骤如下:
1:useradd
使用useradd时,如果后面不加任何参数的话,如:sudo useradd sysadm 创建出来的用户将是默认的三无用户:无home directory ,无密码,无系统shell。
顾应该如下操作:
第五章 常用Lua开发库2-JSON库、编码转换、字符串处理
jinnianshilongnian
nginx lua
JSON库
在进行数据传输时JSON格式目前应用广泛,因此从Lua对象与JSON字符串之间相互转换是一个非常常见的功能;目前Lua也有几个JSON库,本人用过cjson、dkjson。其中cjson的语法严格(比如unicode \u0020\u7eaf),要求符合规范否则会解析失败(如\u002),而dkjson相对宽松,当然也可以通过修改cjson的源码来完成
Spring定时器配置的两种实现方式OpenSymphony Quartz和java Timer详解
yaerfeng1989
timer quartz 定时器
原创整理不易,转载请注明出处:Spring定时器配置的两种实现方式OpenSymphony Quartz和java Timer详解
代码下载地址:http://www.zuidaima.com/share/1772648445103104.htm
有两种流行Spring定时器配置:Java的Timer类和OpenSymphony的Quartz。
1.Java Timer定时
首先继承jav
Linux下df与du两个命令的差别?
pda158
linux
一、df显示文件系统的使用情况,与du比較,就是更全盘化。 最经常使用的就是 df -T,显示文件系统的使用情况并显示文件系统的类型。 举比例如以下: [root@localhost ~]# df -T Filesystem Type &n
[转]SQLite的工具类 ---- 通过反射把Cursor封装到VO对象
ctfzh
VO android sqlite 反射 Cursor
在写DAO层时,觉得从Cursor里一个一个的取出字段值再装到VO(值对象)里太麻烦了,就写了一个工具类,用到了反射,可以把查询记录的值装到对应的VO里,也可以生成该VO的List。
使用时需要注意:
考虑到Android的性能问题,VO没有使用Setter和Getter,而是直接用public的属性。
表中的字段名需要和VO的属性名一样,要是不一样就得在查询的SQL中
该学习笔记用到的Employee表
vipbooks
oracle sql 工作
这是我在学习Oracle是用到的Employee表,在该笔记中用到的就是这张表,大家可以用它来学习和练习。
drop table Employee;
-- 员工信息表
create table Employee(
-- 员工编号
EmpNo number(3) primary key,
-- 姓