隐性反馈行为数据的协同过滤推荐算法
本文是我阅读《CollaborativeFiltering for Implicit Feedback Datasets》论文的笔记,介绍的是对于隐性反馈行为数据协同过滤算法,采取的是隐语义模型(LFM),求解方式是ALS。
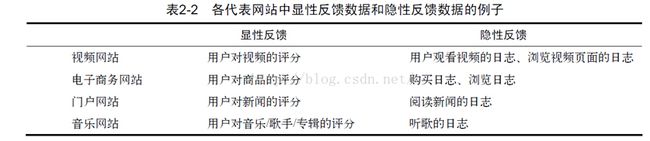
显性反馈行为包括用户明确表示对物品喜好的行为
隐性反馈行为指的是那些不能明确反应用户喜好
的行为。最具代表性的隐性反馈行为就是页面浏览行为。
考虑隐性反馈的必要性:
很多应用场景,并没有显性反馈的存在。因为大部分用户是沉默的用户,并不会明确给系统反馈“我对这个物品的偏好值是多少”。因此,推荐系统可以根据大量的隐性反馈来推断用户的偏好值。
However,explicit feedback is not always available.
Thus, recommenders can infer user preferences from the more abundant
implicit feedback, which indirectly reflect opinion through
observing userbehavior
隐性反馈的特性:
1 没有负反馈。隐性反馈无法判断是否不喜欢。而显性反馈,明显能区分是喜欢还是不喜欢。
2 先天性具有噪声。用户购买了某物品,并不代表他喜欢,也许是送礼,也许买了之后发现不喜欢。
3 显性反馈数值代表偏好程度,隐性反馈数值代表置信度。隐性反馈的数值通常是动作的频次,频次越多,并不代表偏好值越大。比如一个用户经常看某部连续剧,可能该用户对该连续剧的喜好值一般,只是因为每周都播,所以动作频次很大,假如该用户对某部电影超级喜欢,但可能就看过一次,因此动作频次大并不反应偏好值大。从这个用户经常看这部连续剧这个行为,只能推断出该用户喜欢这连续剧有很大的置信度,但这个用户对这个连续剧的偏好值是多少我们无法评估。
4 隐性行为需要近似评估。
显性反馈中,用rui表示偏好值。这里,我们用rui表示隐性反馈的动作频次。
We reserve special indexing letters for distinguishing
users fromitems: for users u, v, and for items i, j. The input
data associate users and items throughrui values, which we
henceforth call observations. For explicit feedback datasets,
those values would be ratings that indicate the preference
by user u of item i, where high values mean stronger preference.
For implicit feedback datasets, those values would
indicate observations for user actions. Forexample,ruican
indicate the number of times upurchased item ior thetime
u spent on webpage i.
偏好值的推断
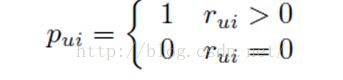
这表达的意思是,用户u对物品i的隐性反馈动作超过一次,我们就认为u喜欢i,动作频次越多,这个假设的置信度就越高。如果没有动作,则认为u对i的偏好值为0,当然因为动作次数为0,所以“u对i的偏好值为0”这个假设的置信度就很低。因为没有动作,除了不喜欢和不感兴趣之外,还有其他很多原因,比如u不知道i的存在。
置信度的衡量
cui = 1 + αrui
论文中提到α = 40效果比较好。
当然,置信度的衡量还有其他方式,总的来说,动作频次越大,置信度就越高。
In general, as rui grows, we have a stronger indication
that the userindeed likes the item.
优化的目标函数:
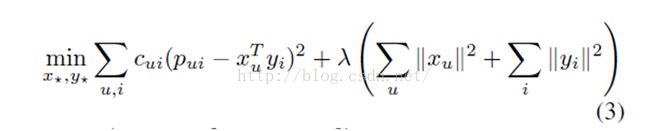
这个跟显性反馈的矩阵分解优化的目标函数类似,但有两个不同点:
1 我们需要考虑置信度
2 优化的目标应该针对所有可能的u,i的键值对,而不只是可观察到的数据。显性反馈的矩阵分解优化时,对于missing data(未知评分),是不会当做训练数据输入到模型的,优化时针对已知评分数据优化。而这里隐性反馈,是利用所有可能的u,i键值对,所以总的数据是m*n,其中m是用户数量,n是物品数量。这里没有所谓的missing data,因为假如u对i没有任何动作,我们就认为偏好值为0,只不过置信度较低而已。
This is similar to matrix factorization techniques
which are popular for explicit feedback data, with two important
distinctions: (1)We need to account for the varying
confidence levels, (2) Optimization should account for all
possible u, i pairs, rather than only those corresponding to
observed data.
优化这个目标函数时,这里还是跟显性的ALS矩阵分解的做法一样。
固定物品特征,对用户特征求偏导数,令偏导数等于0,
更新用户特征
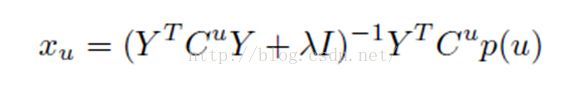
固定用户特征,对物品特征求偏导数,令偏导数等于0,
更新物品特征
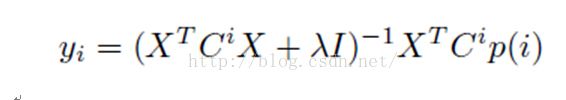
这种做法叫做交替最小二乘法。
论文中,还介绍了一些可以加快上面矩阵计算速度的技巧,详细可以参看论文。
《Collaborative Filteringfor Implicit Feedback Datasets》
《推荐系统实践》
http://mahout.apache.org/users/recommender/intro-als-hadoop.html
本文作者:linger
本文链接:http://blog.csdn.net/lingerlanlan/article/details/46917601