斯坦福大学机器学习——EM算法求解高斯混合模型
EM算法(Expection-Maximizationalgorithm,EM)是一种迭代算法,通过E步和M步两大迭代步骤,每次迭代都使极大似然函数增加。但是,由于初始值的不同,可能会使似然函数陷入局部最优。辜丽川老师和其夫人发表的论文:基于分裂EM算法的GMM参数估计(提取码:77c0)改进了这一缺陷。下面来谈谈EM算法以及其在求解高斯混合模型中的作用。
一、 高斯混合模型(Gaussian MixtureModel, GMM)
之前写过高斯判别分析模型,利用参数估计的方法用于解决二分类问题。下面介绍GMM,它是对高斯判别模型的一个推广,也能借此引入EM算法。
假设样本集为![]() 并且样本和标签满足联合分布
并且样本和标签满足联合分布![]() 。这里:
。这里:![]() 服从多项式分布,即
服从多项式分布,即![]() (
(![]() ,
,![]() ,
, ),且
),且![]() ;在
;在![]() 给定的情况下,
给定的情况下,![]() 服从正态分布,即
服从正态分布,即![]() 。这样的模型称为高斯混合模型。
。这样的模型称为高斯混合模型。
该模型的似然函数为:
如果直接令![]() 的各变量偏导为0,试图分别求出各参数,我们会发现根本无法求解。但如果变量
的各变量偏导为0,试图分别求出各参数,我们会发现根本无法求解。但如果变量![]() 是已知的,求解便容易许多,上面的似然函数可以表示为:
是已知的,求解便容易许多,上面的似然函数可以表示为:
=\underset{i=1}{\overset{m}{\sum}}log\;p(x^{(i)}|z^{(i)};\mu,\Sigma)+log\;p(z^{(i)};\phi)")
利用偏导求解上述式,可分别得到参数![]() 的值:
的值:
}=j\}")
}=j\}x^{(i)}}{\underset{i=1}{\overset{m}{\sum}}\#\{z^{(i)}=j\}}")
}=j\}(x^{(i)}-\mu_{j})(x^{(i)}-\mu_{j})^T}{\underset{i=1}{\overset{m}{\sum}}\#\{z^{(i)}=j\}}")
其中,#{ }为指示函数,表示满足括号内条件的数目。
那么,变量![]() 无法通过观察直接得到,
无法通过观察直接得到,![]() 就称为隐变量,就需要通过EM算法,求解GMM了。下面从Jensen不等式开始,介绍下EM算法:
就称为隐变量,就需要通过EM算法,求解GMM了。下面从Jensen不等式开始,介绍下EM算法:
二、 Jensen不等式(Jensen’s inequality)
引理:如果函数f的定义域为整个实数集,并且对于任意x或![]() 存在
存在![]() 或函数的Hessian矩阵
或函数的Hessian矩阵![]() ,那么函数f称为凹函数。
,那么函数f称为凹函数。![]() 或函数的Hessian矩阵H>0,那么函数f为严格凹函数。
或函数的Hessian矩阵H>0,那么函数f为严格凹函数。
(存在![]() 或函数的Hessian矩阵
或函数的Hessian矩阵![]() ,那么函数f称为凸函数;如果
,那么函数f称为凸函数;如果![]() 或函数的Hessian矩阵 H<0,那么函数f为严格凸函数。)
或函数的Hessian矩阵 H<0,那么函数f为严格凸函数。)
定理:如果函数f是凹函数,X为随机变量,那么:
![]()
不幸的是很多人都会讲Jensen不等式记混,我们可以通过图形的方式帮助记忆。下图中,横纵坐标轴分别为X和f(X),f(x)为一个凹函数,a、b分别为变量X的定义域,E[X]为定义域X的期望。图中清楚的看到各个量的位置和他们间的大小关系。反之,如果函数f是凸函数,X为随机变量,那么:
![]()
Jensen不等式等号成立的条件为:![]() ,即X为一常数。
,即X为一常数。

三、 EM算法
假设训练集![]() 是由m个独立的样本构成。我们的目的是要对
是由m个独立的样本构成。我们的目的是要对![]() 概率密度函数进行参数估计。它的似然函数为:
概率密度函数进行参数估计。它的似然函数为:
&=\underset{i=1}{\overset{m}{\sum}}log\;p(x,\theta)\\ &=\underset{i=1}{\overset{m}{\sum}}log\underset{z}{\sum}p(x,z;\theta) \end{aligned}")
然而仅仅凭借似然函数,无法对参数进行求解。因为这里的随机变量![]() 是未知的。
是未知的。
EM算法提供了一种巧妙的方式,可以通过逐步迭代逼近最大似然值。下面就来介绍下EM算法:
假设对于所有i,![]() 皆为随机变量
皆为随机变量![]() 的分布函数。即:
的分布函数。即:![]() 。那么:
。那么:
其中第(2)步至第(3)步的推导就使用了Jensen不等式。其中:f(x)=log x,![]() ,因此为凸函数;
,因此为凸函数;}}{\sum}Q_{i}(z^{(i)})\frac{p(x^{(i)},z^{(i)};\theta)}{Q_{i}(z^{(i)})}") 表示随机变量为
表示随机变量为![]() 概率分布函数为
概率分布函数为![]() 的期望。因此有:
的期望。因此有:
![]()
这样,对于任意分布![]() ,(3)都给出了
,(3)都给出了![]() 的一个下界。如果我们现在通过猜测初始化了一个
的一个下界。如果我们现在通过猜测初始化了一个![]() 的值,我们希望得到在这个特定的
的值,我们希望得到在这个特定的![]() 下,更紧密的下界,也就是使等号成立。根据Jensen不等式等号成立的条件,当
下,更紧密的下界,也就是使等号成立。根据Jensen不等式等号成立的条件,当![]() 为一常数时,等号成立。即:
为一常数时,等号成立。即:
![]()
由上式可得![]() ,又
,又![]() ,因此
,因此![]() 。再由上式可得:
。再由上式可得:
})&=\frac{p(x^{(i)},z^{(i)};\theta)}{\sum_{z}{p(x^{(i)},z;\theta)}}\\&=\frac{p(x^{(i)},z^{(i)};\theta)}{{p(x^{(i)};\theta)}}\\&=p(z^{(i)}|x^{(i)};\theta) \end{aligned}")
上述等式最后一步使用了贝叶斯公示。
EM算法有两个步骤:
(1)通过设置初始化![]() 值,求出使似然方程最大的
值,求出使似然方程最大的![]() 值,此步骤称为E-步(E-step)
值,此步骤称为E-步(E-step)
(2)利用求出的![]() 值,更新
值,更新![]() 。此步骤称为M-步(M-step)。过程如下:
。此步骤称为M-步(M-step)。过程如下:
repeat until convergence{
(E-step) for each i, set
![]()
![]()
(M-step) set
}}{\sum}Q_{i}(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\theta)}{Q_{i}(z^{(i)})}")
}
那么,如何保证EM算法是收敛的呢?下面给予证明:
假设![]() 和
和![]() 是EM算法第t次和第t+1次迭代所得到的参数
是EM算法第t次和第t+1次迭代所得到的参数![]() 的值,如果有
的值,如果有![]() ,即每次迭代后似然方程的值都会增大,通过逐步迭代,最终达到最大值。以下是证明:
,即每次迭代后似然方程的值都会增大,通过逐步迭代,最终达到最大值。以下是证明:
不等式(4)是由不等式(3)得到,对于任意![]() 和
和![]() 值都成立;得到不等式(5)是因为我们需要选择特定的
值都成立;得到不等式(5)是因为我们需要选择特定的![]() 使得方程
使得方程}}{\sum}Q_{i}(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\theta)}{Q_{i}(z^{(i)})}") 在
在![]() 处的值大于在
处的值大于在![]() 处的值;等式(6)是找到特定的
处的值;等式(6)是找到特定的![]() 的值,使得等号成立。
的值,使得等号成立。
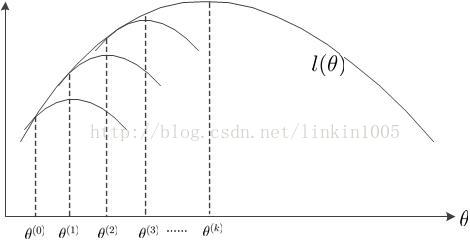
最后我们通过图形的方式再更加深入细致的理解EM算法的特点:
=\underset{i}{\sum}\underset{z^{(i)}}{\sum}Q_{i}(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\theta)}{Q_{i}(z^{(i)})}")
由上文我们知道有这样的关系:![]() ,EM算法就是不断最大化这个下界,逐步得到似然函数的最大值。如下图所示:
,EM算法就是不断最大化这个下界,逐步得到似然函数的最大值。如下图所示:
首先,初始化![]() ,调整
,调整![]() 使得
使得![]() 与
与![]() 相等,然后求出
相等,然后求出![]() 使得到最大值的
使得到最大值的![]() ;固定
;固定![]() ,调整
,调整![]() ,使得
,使得![]() 与
与![]() 相等,然后求出使
相等,然后求出使![]() 得到最大值的
得到最大值的![]() ;……;如此循环,使得
;……;如此循环,使得![]() 的值不断上升,直到k次循环后,求出了
的值不断上升,直到k次循环后,求出了![]() 的最大值
的最大值![]() 。
。
四、 EM算法应用于混合高斯模型(GMM)
再回到GMM:上文提到由于隐变量E-Step:
(1)参数![]()
对期望![]() 的每个分量
的每个分量![]() 求偏导:
求偏导:
令上式为0,得:
}x^{(i)}}{\sum_{i=1}^{m}{\omega_{l}^{(i)}}}")
观察M-Step,可以看到,跟![]() 相关的变量仅仅有
相关的变量仅仅有![]() 。因此,我们仅仅需要最大化下面的目标函数:
。因此,我们仅仅需要最大化下面的目标函数:
}log\phi_{j}")
又由于 ,为约束条件。因此,可以构造拉格朗日算子求目标函数:
,为约束条件。因此,可以构造拉格朗日算子求目标函数:
=\underset{i=1}{\overset{m}{\sum}}\underset{j=1}{\overset{k}{\sum}}\omega_{j}^{(i)}log\phi_{j}+\beta(\underset{j=1}{\overset{k}{\sum}}\phi_{j}-1)")
求偏导:
=\underset{i=1}{\overset{m}{\sum}}\frac{\omega_{j}{(i)}}{\phi_{j}}+1")
令![]() 得:
得:
}}{-\beta}")
将带入上式得:
} &= \sum_{i=1}^{m}1 &=m\end{aligned}")
最后将![]() 带入得:
带入得:
}}{m}")
(3)参数![]()
令上式为零,解得:
} (x^{(i)}-\mu_{j})(x^{(i)}-\mu_{j})^{T} }{ \sum_{i=1}^{m}\omega_{j}^{(i)} }")
五、 总结
EM算法利用不完全的数据,进行极大似然估计。通过两步迭代,逐渐逼近最大似然值。而GMM可以利用EM算法进行参数估计。
最后提下辜老师论文的思路:EM模型容易收敛到局部最大值,并且严重依赖初试值。传统的方法即上文中使用的方法是每次迭代过程中,同时更新高斯分布中所有参数,而辜老师的方法是把K个高斯分布中的一个分量,利用奇异值分解的方法将其分裂为两个高斯分布,并保持其他分量不变的情况下,对共这K+1个高斯分布的权值进行更新,直到符合一定的收敛条件。这样一来,虽然算法复杂度没有降低,但每轮只需要更新两个参数,大大降低了每轮迭代的计算量。