轻量级网络 - PVANet & SuffleNet
一. PVANet
论文:PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection 【点击下载】
Caffe代码:【Github】
设计了一种轻量级的网络,取名叫 PVANet,特点是 Channel少、Layer多,在 VOC2007 和 VOC2012 精确度分别达到了 84.9% 和 84.2%,但计算量不到采用 ResNet-101 网络的 10%。
论文的核心要点:
1)改进的 C.ReLU
前面几层 用到了 CReLU,Concatenated Rectified Linear Units。
CReLU 来源于在 AlexNet 上的一个有趣的实验(参考论文【CReLU】):低层的卷积层中的一些滤波器核存在着负相关程度很高的滤波器核,而层次越高的卷积层,这一现象越不明显。作者把这一现象称为 pairing phenomenon。
根据这种特性,通过 Negation 实现 Concatenation,在不损失精度的情况下可以减少一半计算量。
作者基于 CReLU 进行了改进,添加了 Scale/Bias 层(见下图左),允许每个channel(通道)的斜率和激活阈值与其相反的 Channel 不同。

2)使用 Inception Net
“Inception 没有广泛应用在现有网络中”,目前来看使用的确实也不少了,不纠结这个,Inception 的优点是通过不同尺度的卷积核 对应不同大小的感受野,从而适应不同大小的目标。
上图右侧是 Inception 的网络结构,作者用两个 3*3 的 Conv 替代 5*5 的 Conv,其中 1*1 的 Conv保留特征尺度,直接连接定义 残差。
3)深度网络训练
a)使用了 Residual Net 和 BN(Batch Norm),ResNet 与 Inception Layer 连接;
b)通过自定义策略 “Plateu” 动态调整学习率,如果 moving average of loss 在迭代周期内低于一个预设值,触发 “on-plateau”,将学习率动态减少一个常量。
从一般意义上来说,动态调整学习率 可以有效避免震荡,提高训练精度。
4)整体设计
以表的形式给出各层的 Detail:
5)Hyper-feature concatenation
多尺度的特征组合在很多文献中都有大量应用,文中用在目标检测上,能够对多尺度的目标进行有效检测。
如下图所示,采用了三个不同 Scale 进行 Feature 联合。


PVA 是个轻量级网络,基本能够达到实时(Titan X),对于实时系统应用的童鞋可以考虑。
【训练过程】
1)安装 Caffe 依赖库
必要的 caffe 依赖库:
安装 CUDA 和 cuDNN (请参考其他教程,这里不再展开)sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler sudo apt-get install --no-install-recommends libboost-all-dev sudo apt-get install libatlas-base-dev # sudo apt-get install libopenblas-dev sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev
2)下载 PVANet
> 下载 Github 源码,直接下载或 命令行:
Git clone --recursive https://github.com/sanghoon/pva-faster-rcnn.git> 根据自己的配置修改 Makefile.config 文件:
需要修改的几个地方:cd $pva-faster-rcnn/caffe-fast-rcnn cp Makefile.config.example Makefile.configUSE_CUDNN := 1 CUSTOM_CXX := g++ CUDA_ARCH := -gencode arch=compute_52,code=sm_52 BLAS := atlas PYTHON_INCLUDE := /usr/include/python2.7 \ /usr/lib/python2.7/dist-packages/numpy/core/include PYTHON_LIB := /usr/lib WITH_PYTHON_LAYER := 1 INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial/MakeFile:
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_serial_hl hdf5_serialpva-faster-rcnn/lib/setup.py:
> 编译 Cython:extra_compile_args={'gcc': ["-Wno-unused-function"], 'nvcc': ['-arch=sm_52',> 编译 caffe 和 pycaffe:cd $pva-faster-rcnn/lib makecd $pva-faster-rcnn/caffe-fast-rcnn make –j8 & make pycaffe & make distributefatal error: caffe/proto/caffe.pb.h: No such file or directory
$ protoc src/caffe/proto/caffe.proto --cpp_out=. $ mkdir include/caffe/proto $ mv src/caffe/proto/caffe.pb.h include/caffe/proto执行完后修改bashrc文件,添加python path
sudo gedit ~/.bashrc export PYTHONPATH=${HOME}/caffe/distribute/python:$PYTHONPATH export LD_LIBRARY_PATH=${HOME}/caffe/build/lib:$LD_LIBRARY_PATH使得python能够找到caffe的依赖。
3)下载VOC数据
按照顺序执行下载及解压(否则解压不到一个文件夹)
将得到的 VOCdevkit,建立软链接(命名为 VOCdevkit2007),并Copy到 $pva-faster-rcnn/data/ 目录下。wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar tar xvf VOCtrainval_06-Nov-2007.tar tar xvf VOCtest_06-Nov-2007.tar tar xvf VOCdevkit_08-Jun-2007.tar4)测试预训练模型
进入根目录,按如下脚本测试:
测试 demo:# Download PVANet detection model for VOC2007 . ./models/pvanet/download_voc2007.sh # Download PVANet detection model for VOC2012 (published model) . ./models/pvanet/download_voc_best.sh # (Optional) Download all available models (including pre-trained and compressed models) . ./models/pvanet/download_all_models.sh # (Optional) Download ILSVRC2012 (ImageNet) classification model . ./models/pvanet/download_imagenet_model.shpython ./tools/test_pvanet.py5)自定义训练
> 修改训练 类别(num_classes)
打开文件 /models/pvanet/example_finetune/train.prototxt
修改 input、cls_score、bbox_pred、roi-data 中的 num_classes(如果只检测1类的话,改为2)
> 修改 lib/datasets/pascal_voc.py
self._classes = ('__background__', # always index 0
'people')(只有这一类)
> 修改 lib/datasets/imdb.py
在代码行 boxes[:, 2] = widths[i] - oldx1 - 1 下面加入代码:
for b in range(len(boxes)): if boxes[b][2]< boxes[b][0]: boxes[b][0] = 04)> 编译修改脚本
进入 lib/datasets 目录,删除原来的 pascal_voc.pyc 和 imdb.pyc 文件(.pyc 是Python编译后的文件),重新编译:
python >>>import py_compile >>>py_compile.compile(r'pascal_voc.py') >>>py_compile.compile(r'imdb.py')> 训练及测试数据
测试模型cd $pva-faster-rcnn ./tools/train_net.py --gpu 0 --solver models/pvanet/example_finetune/solver.prototxt --weights models/pvanet/full/test.model --iters 100000 --cfg models/pvanet/cfgs/train.yml --imdb voc_2007_trainval
./tools/test_net.py --gpu 0 --def models/pvanet/example_finetune/test.prototxt --net output/faster_rcnn_pavnet/voc_2007_trainval/pvanet_frcnn_iter_100000.caffemodel --cfg models/pvanet/cfgs/submit_160715.yml6)类别设置
(cudaSuccess 8 vs. 0)一般情况下都是因为显卡的计算能力不同而导致的,修改 py-faster-rcnn/lib/setup.py 的第135行,将arch改为与你显卡相匹配的数值,(GTX1080,计算能力是6.1,就将sm_35改成了sm_61)然后删除utils/bbox.c,nms/cpu_nms.c ,nms/gpu_nms.cpp 重新编译即可.
二. SuffleNet
论文:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices 【点击下载】
这篇文章出自 Face++ 的孙剑大神组,主要目的是通过减少网络计算量,达到在移动端应用的目的。文章比较 MobileNet (State-of-the-art),在同样计算量的情况下有 6.7% 的提升。
SuffleNet 是属于模型优化的范畴,对于模型优化有很多种方法,这里先大致列一下,后面会有专门的总结介绍。
> Efficient Model Designs(高效的模型设计)
这里主要强调两种加速计算的方法,Group Convolution 和 Depthwise Convolution,也正是本文所采用的模型优化设计思路。
Group Convolution 最早来自于 AlexNet,经典的拓扑图展示了把 Channel 划分到不同 Group 进行卷积,原文是为了在两个 GPU 计算,这是最早的通道拆分概念;
Depthwise Separable Convolution 将 标准的Conv操作 分解成一个 Depthwise Conv(独立通道) 和一个 PointWise Conv(1*1的卷积),以此减少计算量;
Depthwise 每个卷积核(Filter)只对一个 Channel 进行卷积计算,Pointwise Conv 执行通道合并,可以理解为:
Depthwise Separable Convolution = Depthwise Convolution + Pointwise Convolution
基于该思路设计的框架如 Xception,ResNeXt,我傻傻的分不太清, MobileNet 也是这个思路。
> Model Acceleration(模型加速)
Pruning(剪枝) 是最直观的一种加速方法,思路比较简单,即去除权值较小的 Connection,或者减少 Channel 数量,得到稀疏的网络连接。
Quantization(量化) 用于参数压缩,包括下面两个方向:
a)将 Float32 量化为 8bit 定点数或更少,减少模型计算量 和 参数存储大小(缺点是精度下降),同时借助 SIMD 等策略实现批量计算;二值化网络是参数量化的一个极端情况,比较典型的是 BinaryNet 和 Xnor-net。
b)权值共享 -通过对权值进行压缩来得到共享权值,共享信息一般通过聚类来得到。
Factorization(因式分解) 主要用于降低全连接层的计算。
Distilling(知识迁移)将大模型训练的知识 迁移到 小模型。可以看一下 Hinton 的蒸馏模型 - Distilling the knowledge in a neural network。
● Channel Shuffle
Shuffle 是本文的核心概念,引入 Shuffle 是为了解决 Group Convolution 的问题:
(a)只用 GConv 来做的话,卷积只在 Group Channel 内部计算,Group 之间(下图颜色区分)相互独立;
问题在于不同 Group 之间没有信息Flow,缺乏 inter 信息,模型精度会比较差。
(b)不同 Group 之间的 Channel 重新分配,增加 Group 之间的信息 Flow;
重新分配与 原始的 Conv 一样,都加入了 inter 信息,但计算量降低很多。
(c)作者加入的 Channel Shuffle,实现与(b)一样的功能;
专门提到通过 Shuffle 方式,两个 GConv(GConv1 & GConv2) 之间的 Group 是可以不同的。

● ShuffleNet Unit
ShuffleNet 单元引入了上面的 Shuffle 层,先来看图:
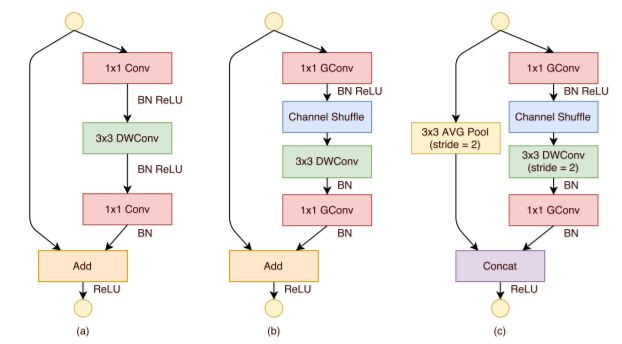
图(a)是原始的 Bottle Neck Units,引入了 3*3 的 DepthWise Conv(比较重要),这里 Depthwise 是指在每个独立的通道进行计算,通道之间不交叠,Depthwise Conv 最大层度上减少计算量。前面讲过,采用这总结构的网络包括:ResNet、Xception 和 MobileNet。
可以看到,图(a)中的 1x1 Conv 并未做优化,可以认为全部计算的(full connection),根据作者统计这部分计算量占比达到 93.4%,这个比例相当惊人,不优化不足以平民愤,于是该 Channel Shuffle 出场了,参考上图(b)来看作者的改进包括哪些:
1)通过 1x1 的 GConv+Shuffle 替代原来的 1x1部分,在不降低计算精度的情况下大大减少计算量;
2)去掉了 DWConv后面的 ReLU部分,这个可以自己看论证;
上图(c)给出了另一种结构:
1)在 ShortCut 添加了 Avg Pool 实现降采样,同时将 DWConv Stride 改为2,与之匹配;
2)用 Concat 替换原来的 Add,增加 Channel 数量;
● 网络架构
ShuffleNet 网络结构也比较清晰,如下图:

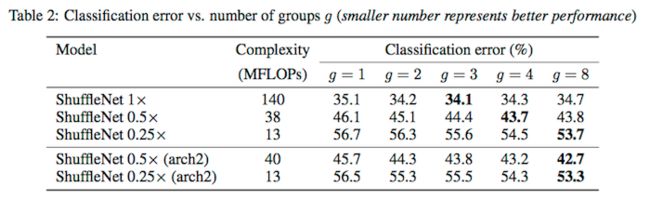
另外 Group 的 size 数量影响分类误差,对于固定计算量的情况,Group越多,对应的channel 通过也就越多,通常精度会提升,当然不会无限提升,在和 Filter 数量达到一定比例的情况下(可以理解为混淆比较均匀),精度最高。
作者通过 Scale 来控制 Filter 数量,Filter越少,计算量相应也就越少。
来看下图:
● 实验对比
采用ResNeXt 的方法进行训练,只做了两个小的改动:
1)将权值衰减从1e-4 减少为 4e-5;
2)只用了简单的 Scale 做数据增强;
这样做的依据是 小网络通常容易欠拟合 而不是过拟合,类似的 MobileNet 也采用了同样的策略进行训练。
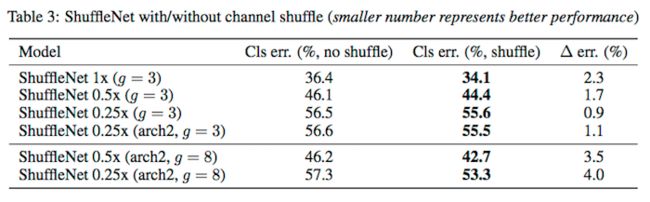
Table3 对比了 Channel Shuffle 带来的作用:
下面给出了 ShuffleNet 与 经典网络、轻量级MobileNet 之间的对比:

与经典网络的复杂度比较(在同样准确度的情况下):

在 MS COCO 上测试 ShuffleNet 的泛化性能:

最后给出实测数据,相对于 AlexNet 有 13倍的提高:
