常用损失函数和评价指标总结
文章目录
- 1. 损失函数:
- 1.1 回归问题:
- 1. 平方损失函数(最小二乘法):
- 2 平均绝对值误差(L1)-- MAE:
- 3 MAE(L1) VS MSE(L2):
- 4. Huber损失:
- 1.2 分类问题:
- 1. LogLoss:
- 2. 指数损失函数:
- 2.评价指标:
- 2.1 回归问题:
- 2.2 分类问题:
- 1. Accuracy(准确率):
- 2. Precision(精准率):
- 3. Recall(召回率):
- 4. P-R曲线:
- 5. $F_{\beta }$(加权调和平均)和 $F_1$(调和平均):
- 6. ROC-AUC:
- 7. 代码实现:
- 参考资料:
1. 损失函数:
1.1 回归问题:
1. 平方损失函数(最小二乘法):
L ( Y , f ( x ) ) = ∑ i = 1 n ( Y − f ( X ) ) 2 L(Y,f(x)) = \sum_{i=1}^n(Y-f(X))^2 L(Y,f(x))=i=1∑n(Y−f(X))2
回归问题中常用的损失函数,在线性回归中,可以通过极大似然估计(MLE)推导。计算的是预测值与真实值之间距离的平方和。实际更常用的是均方误差(MSE):
L ( Y , f ( x ) ) = 1 m ∑ i = 1 n ( Y − f ( X ) ) 2 L(Y,f(x)) = \frac{1}{m}\sum_{i=1}^n(Y-f(X))^2 L(Y,f(x))=m1i=1∑n(Y−f(X))2
2 平均绝对值误差(L1)-- MAE:
L ( Y , f ( x ) ) = ∑ i = 1 n ∣ Y − f ( X ) ∣ L(Y,f(x)) = \sum_{i=1}^n|Y-f(X)| L(Y,f(x))=i=1∑n∣Y−f(X)∣
MAE是目标值和预测值之差的绝对值之和。
3 MAE(L1) VS MSE(L2):
- MSE计算简便,但MAE对异常点有更好的鲁棒性:
当数据中存在异常点时,用RMSE计算损失的模型会以牺牲了其他样本的误差为代价,朝着减小异常点误差的方向更新。然而这就会降低模型的整体性能。
直观上可以这样理解:如果我们最小化MSE来对所有的样本点只给出一个预测值,那么这个值一定是所有目标值的平均值。但如果是最小化MAE,那么这个值,则会是所有样本点目标值的中位数。众所周知,对异常值而言,中位数比均值更加鲁棒,因此MAE对于异常值也比MSE更稳定。
-
NN中MAE更新梯度始终相同,而MSE则不同:
MSE损失的梯度随损失增大而增大,而损失趋于0时则会减小。 -
Loss选择建议:
- MSE: 如果异常点代表在商业中很重要的异常情况,并且需要被检测出来
- MAE: 如果只把异常值当作受损数据
详细建议参考[6]。
4. Huber损失:
L δ ( y , f ( x ) ) = { 1 2 ( y − f ( x ) ) 2 for ∣ y − f ( x ) ∣ ≤ δ δ ∣ y − f ( x ) ∣ − 1 2 δ 2 otherwise L_{\delta}(y, f(x))=\left\{\begin{array}{ll}{\frac{1}{2}(y-f(x))^{2}} & {\text { for }|y-f(x)| \leq \delta} \\ {\delta|y-f(x)|-\frac{1}{2} \delta^{2}} & {\text { otherwise }}\end{array}\right. Lδ(y,f(x))={21(y−f(x))2δ∣y−f(x)∣−21δ2 for ∣y−f(x)∣≤δ otherwise
Huber损失是绝对误差,只是在误差很小时,就变为平方误差。当Huber损失在 [ 0 − δ , 0 + δ ] [0-\delta,0+\delta] [0−δ,0+δ]之间时,等价为MSE,而在 [ − ∞ , δ ] [-∞,\delta] [−∞,δ]和 [ δ , + ∞ ] [\delta,+∞] [δ,+∞]时为MAE。
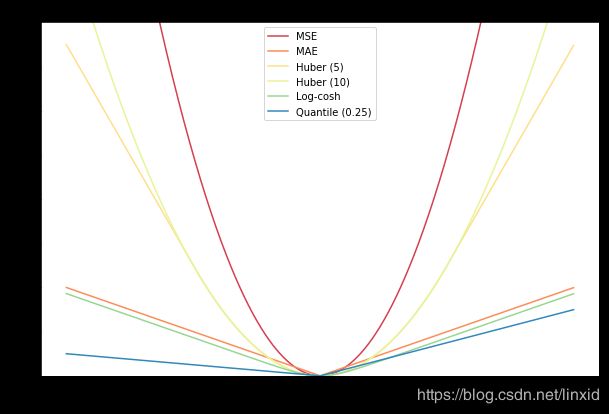
1.2 分类问题:
1. LogLoss:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) log h θ ( x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] J(\theta)=-\frac{1}{m} \sum_{i=1}^{m}\left[y^{(i)} \log h_{\theta}\left(x^{(i)}\right)+\left(1-y^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)\right)\right] J(θ)=−m1i=1∑m[y(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]
二分类任务中常用的损失函数,在LR中,通过对似然函数取对数得到。也就是交叉熵损失函数。
2. 指数损失函数:
L ( y , f ( x ) ) = 1 m ∑ i = 1 n e x p [ − y i f ( x i ) ] L(y,f(x)) = \frac{1}{m} \sum_{i=1}^n{exp[-y_if(x_i)]} L(y,f(x))=m1i=1∑nexp[−yif(xi)]
在AdaBoost中用到的损失函数。
2.评价指标:
2.1 回归问题:
1. MSE: 均方误差(Mean Square Error),范围 [ 0 , + ∞ ) [0,+∞) [0,+∞)
M S E = 1 n ∑ i = 1 n ( y ^ i − y i ) 2 MSE=\frac{1}{n} \sum_{i=1}^{n}\left(\hat{y}_{i}-y_{i}\right)^{2} MSE=n1i=1∑n(y^i−yi)2
2. RMSE: 根均方误差(Root Mean Square Error),范围 [ 0 , + ∞ ) [0,+∞) [0,+∞)
R M S E = 1 n ∑ i = 1 n ( y ^ i − y i ) 2 RMSE =\sqrt{\frac{1}{n} \sum_{i=1}^{n}\left(\hat{y}_{i}-y_{i}\right)^{2}} RMSE=n1i=1∑n(y^i−yi)2
3. MAE: 平均绝对误差(Mean Absolute Error),范围 [ 0 , + ∞ ) [0,+∞) [0,+∞)
M A E = 1 n ∑ i = 1 n ∣ y ^ i − y i ∣ MAE=\frac{1}{n} \sum_{i=1}^{n}\left|\hat{y}_{i}-y_{i}\right| MAE=n1i=1∑n∣y^i−yi∣
4. MAPE: 平均绝对百分比误差(Mean Absolute Percentage Error)
M A P E = 100 % n ∑ i = 1 n ∣ y ^ i − y i y i ∣ MAPE=\frac{100 \%}{n} \sum_{i=1}^{n}\left|\frac{\hat{y}_{i}-y_{i}}{y_{i}}\right| MAPE=n100%i=1∑n∣∣∣∣yiy^i−yi∣∣∣∣
注意点:当真实值有数据等于0时,存在分母0除问题,该公式不可用!
5. SMAPE: 对称平均绝对百分比误差(Symmetric Mean Absolute Percentage Error)
S M A P E = 100 % n ∑ i = 1 n ∣ y ^ i − y i ∣ ( ∣ y ^ i ∣ + ∣ y i ∣ ) / 2 SMAPE=\frac{100 \%}{n} \sum_{i=1}^{n} \frac{\left|\hat{y}_{i}-y_{i}\right|}{\left(\left|\hat{y}_{i}\right|+\left|y_{i}\right|\right) / 2} SMAPE=n100%i=1∑n(∣y^i∣+∣yi∣)/2∣y^i−yi∣
注意点: 真实值、预测值均等于0时,存在分母为0,该公式不可用!
6. 代码实现:
# coding=utf-8
import numpy as np
from sklearn import metrics
# MAPE和SMAPE需要自己实现
def mape(y_true, y_pred):
return np.mean(np.abs((y_pred - y_true) / y_true)) * 100
def smape(y_true, y_pred):
return 2.0 * np.mean(np.abs(y_pred - y_true) / (np.abs(y_pred) + np.abs(y_true))) * 100
y_true = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, -3.0])
y_pred = np.array([1.0, 4.5, 3.5, 5.0, 8.0, 4.5, 1.0])
# MSE
print(metrics.mean_squared_error(y_true, y_pred)) # 8.107142857142858
# RMSE
print(np.sqrt(metrics.mean_squared_error(y_true, y_pred))) # 2.847304489713536
# MAE
print(metrics.mean_absolute_error(y_true, y_pred)) # 1.9285714285714286
# MAPE
print(mape(y_true, y_pred)) # 76.07142857142858
# SMAPE
print(smape(y_true, y_pred)) # 57.76942355889724
2.2 分类问题:
以下为二分类的混淆矩阵,多分类的混淆矩阵和这个类似。
| 预测正例 | 预测反例 | |
|---|---|---|
| 真实正例 | TP(真正例) | FN(假反例) |
| 真实反例 | FP(假正例) | TN(真反例) |
1. Accuracy(准确率):
A c c = T P + T N T P + T N + F P + F N Acc=\frac{T P+T N}{T P+T N+F P+F N} Acc=TP+TN+FP+FNTP+TN
准确率在样本不平衡的情况下,产生效果较差。
2. Precision(精准率):
P = T P T P + F P P=\frac{T P}{T P+F P} P=TP+FPTP
含义: 预测为正例的样本中有多少实际为正;
3. Recall(召回率):
R = T P T P + F N R=\frac{T P}{T P+F N} R=TP+FNTP
含义: 实际为正例的样本有多少被预测为正;
4. P-R曲线:
通过选择不同的阈值,得到Recall和Precision,以Recall为横坐标,Precision为纵坐标得到的曲线图。

PR曲线性质:
- 如果一个学习器的P-R曲线被另一个学习器的曲线完全包住,后者性能优于前者;
- 如果两个学习器的曲线相交,可以通过平衡点的来度量性能,它是“查准率=查全率”时的取值;
- 阈值为0时: T P = 0 = > P r e c i s i o n = 0 , R e c a l l = 0 TP=0 => Precision=0,Recall=0 TP=0=>Precision=0,Recall=0 所以PR 曲线经过 (0,0)点;
- 阈值上升:
- Recall:不断增加,因为越来越多的样本被划分为正例;
- Precision: 震荡下降,不是严格递减;
- 如果有个划分点可以把正负样本完全区分开,那么P-R曲线面积是1*1;
5. F β F_{\beta } Fβ(加权调和平均)和 F 1 F_1 F1(调和平均):
F β = ( 1 + β 2 ) ∗ P ∗ R ( β 2 ∗ P ) + R F_{\beta }=\frac{(1+\beta ^{2})*P*R}{(\beta ^{2}*P)+R} Fβ=(β2∗P)+R(1+β2)∗P∗R
- β > 1 \beta >1 β>1:召回率(Recall)影响更大,eg. F 2 F_2 F2
- β < 1 \beta <1 β<1:精确率(Precision)影响更大,eg. F 0.5 F_{0.5} F0.5
β \beta β为1的时候得到 F 1 F_1 F1:
F 1 = 2 ∗ P ∗ R P + R F_{1}=\frac{2*P*R}{P+R} F1=P+R2∗P∗R
调和平均亦可推出:
1 F 1 = 1 2 ∗ ( 1 R + 1 P ) \frac{1}{F_{1}}=\frac{1}{2}*(\frac{1}{R}+\frac{1}{P}) F11=21∗(R1+P1)
6. ROC-AUC:
横轴-假正例率: 实际为负的样本多少被预测为正;
F P R = F P T N + F P FPR=\frac{FP}{TN+FP} FPR=TN+FPFP
纵轴-真正例率: 实际为正的样本多少被预测为正;
T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP
通过选择不同的阈值得到TPR和FPR,然后绘制ROC曲线。

曲线性质:
- 阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1);
- ROC曲线越靠近左上角,该分类器的性能越好;
- 对角线表示一个随机猜测分类器;
- 若一个学习器的ROC曲线被另一个学习器的曲线完全包住,后者性能优于前者;
AUC: ROC曲线下的面积为AUC值。
本质: 一个正例,一个负例,预测为正的概率值比预测为负的概率值还要大的可能性。
7. 代码实现:
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,fbeta_score
y_test = [1,1,1,1,0,0,1,1,1,0,0]
y_pred = [1,1,1,0,1,1,0,1,1,1,0]
print("准确率为:{0:%}".format(accuracy_score(y_test, y_pred)))
print("精确率为:{0:%}".format(precision_score(y_test, y_pred)))
print("召回率为:{0:%}".format(recall_score(y_test, y_pred)))
print("F1分数为:{0:%}".format(f1_score(y_test, y_pred)))
print("Fbeta为:{0:%}".format(fbeta_score(y_test, y_pred,beta =1.2)))
参考资料:
1. 分类问题性能评价指标详述
2.AUC,ROC我看到的最透彻的讲解
3.机器学习大牛最常用的5个回归损失函数,你知道几个?
4.机器学习-损失函数
5.损失函数jupyter notebook
6.L1 vs. L2 Loss function
7. P-R曲线深入理解