hive udtf 输入一列返回多行多列
之前说到了hive udf,见https://blog.csdn.net/liu82327114/article/details/80670415
UDTF(User-Defined Table-Generating Functions) 用来解决 输入一行输出多行(On-to-many maping) 的需求。
继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,实现initialize, process, close三个方法。
UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。
初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每一次forward()调用产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。
最后close()方法调用,对需要清理的方法进行清理。
1.创建maven工程
file->project structure->modules->点击+号->new module->选择maven
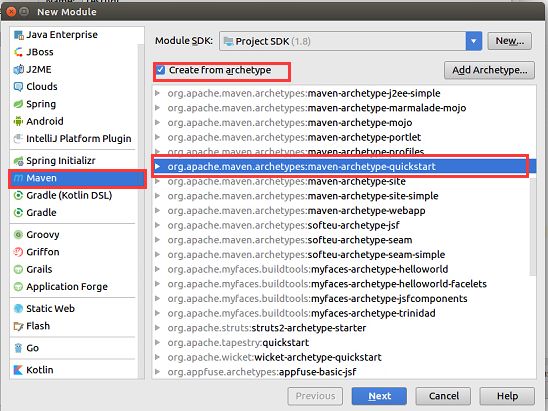
点击next,填写groupid(对应包结构)、artifactid(maven仓库对应的坐标)
source java 代码,操作如下图file->project structure,
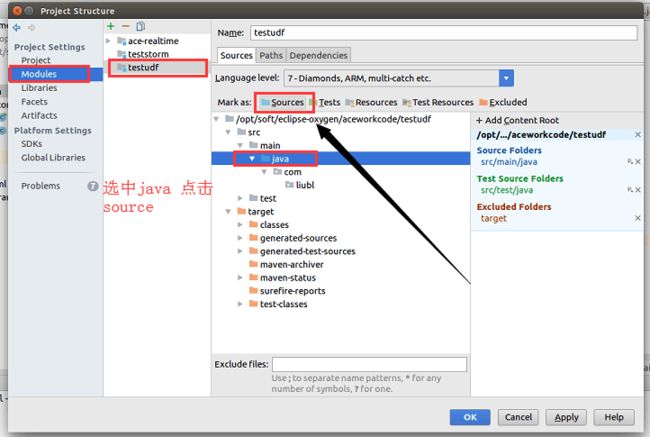
点击apply,
2.开始写java代码
添加maven依赖
代码如下
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.json.JSONArray;
import java.util.ArrayList;
public class helloudtf extends GenericUDTF {
@Override
// 可接收参数数组
public void process(Object[] objects) throws HiveException {String input = objects[0].toString();
String[] result = new String[2];
result[0] = input;
result[1] = input+input;
String[] result1 = new String[2];
result1[0] = input+"a";
result1[1] = input+"a"+input;
forward(result);//一个forward 代表一行
forward(result1);
}
@Override
public StructObjectInspector initialize(ObjectInspector[] args)
throws UDFArgumentException {
if (args.length != 1) {
throw new UDFArgumentLengthException("ExplodeMap takes only one argument");
}
if (args[0].getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentException("ExplodeMap takes string as a parameter");
}
ArrayList
ArrayList
fieldNames.add("col1");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("col2");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
//定义了行的列数和类型
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs);
}
@Override
public void close() throws HiveException {
}
}
3.编包上传到hdfs
在此项目pom文件的路径下执行mvn clean install
将target文件中生成的jar文件上传到hdfs上,路径自己自定义,我直接上传到/。
sudo -u hdfs hdfs dfs -put testudf-1.0-SNAPSHOT.jar /
4.使用hivesql或者sparksql加载自定义函数
beeline -u jdbc:hive2://node113.leap.com:10000 -n hive
create function test.iptonum as 'com.liubl.helloudtf' using jar 'hdfs:///testudf-1.0-SNAPSHOT.jar';
(com.liubl.HelloUdf为代码类的全路径自己去粘贴一下)
(测试sql见图)

UDTF的使用:
UDTF有两种使用方法,一种直接放到select后面,一种和lateral view一起使用。
1:直接select中使用:select explode_map(properties) as (col1,col2) from src;
- 不可以添加其他字段使用:select a, explode_map(properties) as (col1,col2) from src
- 不可以嵌套调用:select explode_map(explode_map(properties)) from src
- 不可以和group by/cluster by/distribute by/sort by一起使用:select explode_map(properties) as (col1,col2) from src group by col1, col2
2:和lateral view一起使用:select src.id, mytable.col1, mytable.col2 from src lateral view explode_map(properties) mytable as col1, col2;
- 此方法更为方便日常使用。执行过程相当于单独执行了两次抽取,然后union到一个表里。