机器学习推导合集01-霍夫丁不等式的推导 Hoeffding Inequality
1.0 引言
笔者第一次接触霍夫丁不等式(Hoeffding Inequality)是在林轩田先生的机器学习基石课程(还是在b站上看的hh)上。可以说,当时没有系统学过概率论与数理统计(probability and statistics)的我,对于不等式的推导是感到相当头疼。后来,我本科课程优化与机器学习课程引用了伦斯勒理工学院(RPI)的slide。乍看之下,发现竟与林轩田先生的课十分相似。后来,我才发现该课程参考书目Learning from data中作者之一就是林轩田先生。我在这一次成功理解了霍夫丁不等式的推导。接下来,我将详细基础介绍一下霍夫丁不等式,希望对概率论基础较为薄弱的自学读者们有所帮助。
1.1 需要补充的概率论知识
以下知识是需要读者自学的:
- 随机变量(random variable)的概念
- 期望(expectation)的概念与定义
- 伯努利分布(bernouli distribution)
- 二项式分布(binomial distribution)
- 泰勒展开(Talyor expansion)
介绍一下Indicator,指示随机变量。国内教材对其介绍甚少:

2 霍夫丁不等式理解
2.1霍夫丁不等式与机器学习的关系

我们数学定义的经验风险的期望和分类器错误率相等。这一定义符合直觉。注意到,实际抽样过程后,经验风险具现(crystalized)成数据(data)后与错误率是极大概率不同的(在连续情况下,二者相同的准确概率应为0)。例如:我扔三次骰子之后,取的平均数不一定为3。虽然我们理论建模分析后,其期望应该是3。
在实际机器学习的情况里,当我们无法通过解析方式准确判断分类器的错误率时,我们必须考虑通过上述定义的经验风险来进行估计。例如:我们有一基于MNIST数据集的手写数字CNN分类器,计算确定分类器准确率是不切实际的。我们实际评估其性能的做法是:输入数字图像,进行重复试验n次,获得如上述定义的经验风险。现在出现新的问题,我们企图知晓期望风险和实际模型错误率是否接近。这个时候,霍夫丁不等式揭示了二者是如何随着样本容量N的增加而相互接近的。
2.2 霍夫丁不等式数学公式
接下来展示一些霍夫丁不等式的结论,证明过程在第三部分。首先展示其特殊形式,是承接2.1中所阐述的问题的
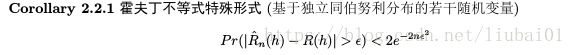
这个式子是更一般霍夫丁不等式的推论,其一般形式为:

3 霍夫丁不等式的推导
有了前面的了解,现在大致清楚霍夫丁不等式的作用,接下来我们通过“三驾马车”(马尔科夫、切比雪夫、切尔诺夫)三位的工作,逐步通过数理推出我们的重头戏,霍夫丁不等式。
3.1 马尔科夫不等式的推导

3.2 切比雪夫不等式的推导

为了建立起切比雪夫不等式给定的上限和霍夫丁不等式给定上限的联系,我用蒙特卡洛方法获得左边概率近似值(算是间接用了不等式的结论),同时绘制出两个上限以做比较:

我们可以看出,这个两个上限在n不够大和e太小的情况下,实际上发挥不了作用。但无论如何,他们给了我们定性的直觉:更多的采样带来更好的精度。模拟程序语言是python,在附录5.A中
3.3 切尔诺夫界的推导

3.4 霍夫丁不等式的推导
我们在这里重提一遍霍夫丁不等式的一般形式

接下来开始证明,首先证明引理


证明定理:

4 参考文献
- EECS 598: Statistical Learning Theory, Winter 2014 Topic 3Joseph
- Joseph K._ Hwang, Jessica-Introduction to Probability-CRC Press (2014)
5 附录
5.A 模拟程序(python)
概率随N变化:
from scipy import stats
import numpy as np
import matplotlib.pyplot as plt
if __name__ == "__main__":
N = np.array(np.power(10, np.arange(3, 8, 0.02)), dtype=np.int32)
p = 0.3
epsilon = 0.001
Pr = np.zeros(N.shape)
size = 80000
i = 0
for n in N:
print(n)
X = stats.binom.rvs(n, p, size=size)
Pr[i] = np.count_nonzero(np.abs(X / n - p) > epsilon) / size
i += 1
chebysheve_bounding = 1 / (4 * N * epsilon * epsilon)
hoeffding_bounding = 2 * np.exp(-2 * N * epsilon * epsilon)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(N, Pr, label="Monte-Carlo simulation")
ax.plot(N, chebysheve_bounding, label="chebysheve bounding")
ax.plot(N, hoeffding_bounding, label="hoeffding_bounding")
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles[::-1], labels[::-1])
plt.xscale('log')
plt.xlim(10 ** 3, 10 ** 8)
plt.ylim(0, 1)
plt.xlabel("N")
plt.ylabel("Pr")
plt.show()概率随精度(e)变化
from scipy import stats
import numpy as np
import matplotlib.pyplot as plt
if __name__ == "__main__":
n = 10000
p = 0.4
epsilon = np.power(10, np.arange(-3, -1, 0.001))
Pr = np.zeros(epsilon.shape)
size = 5000
i = 0
for e in epsilon:
print(e)
X = stats.binom.rvs(n, p, size=size)
Pr[i] = np.count_nonzero(np.abs(X / n - p) > e) / size
i += 1
chebysheve_bounding = 1 / (4 * n * epsilon * epsilon)
hoeffding_bounding = 2 * np.exp(-2 * n * epsilon * epsilon)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(epsilon, Pr, label="Monte-Carlo simulation")
ax.plot(epsilon, chebysheve_bounding, label="chebysheve bounding")
ax.plot(epsilon, hoeffding_bounding, label="hoeffding_bounding")
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles[::-1], labels[::-1])
plt.xscale('log')
plt.xlim(10 ** -1, 10 ** -3)
plt.ylim(0, 1)
plt.xlabel("epsilon")
plt.ylabel("Pr")
plt.show()