【tensorflow】conv2d/conv3d/maxpool2d/maxpool3d
近来需要做一个3DCNN的网络模型,就把tensorflow中2d和3d的卷积和最大池化的API整理了一下,以便加深印象。
1、2d卷积
1.1 原理
首先,上图说明卷积是如何操作的:






在第一幅图中,左边为原图,大小为5x5,右上边为卷积滤波器,大小为3x3,卷积操作就是在原图上滑动滤波器窗口,滑动步长可由stride设定,这里是[1,1],即高和宽都是每次滑动一个步长。每次原图和滤波器对应位置的像素值分别做乘法,最后将所有的乘积加起来得到的和即为新图(红色框的图)中对应位置的像素值。在这个例子中,最后得到3x3的新图。
1.2 tf.nn.conv2d函数介绍
官网说明文档
函数原型:
conv2d(input,
filter,
strides,
padding,
use_cudnn_on_gpu=None,
data_format=None,
name=None
)函数参数说明:
input:是需要做卷积的输入图像,要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一。
filter:相当于CNN中的卷积滤波器,要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同。注意,第三维in_channels,就是参数input的第四维。
strides:卷积时在图像每一维滑动的步长,这是一个一维的向量,长度4,一般是[1,x,x,1]的形式。
padding:string类型的量,取“SAME”或“VALID”,其中SAME表示需要在输入input高和宽维度的周围添加像素点,卷积率抱起会停留在原图边缘,保证得到的新图与原图的shape相同;VALID则表示不需要填充。
use_cudnn_on_gpu:可选,bool类型,是否使用cudnn加速,默认为true。
data_format:可选,string类型,取“NHWC”或“NCHW”,表示输入数据input的存储形式,“NHWC” the d表示[batch, height, width, channels],NCHW”表示[batch, channels, height, width]。
name:可选,表示操作的名字。
函数返回值:一个tensor,与input类型一致,维度顺序取决于data_format。
1.3 代码解释
参考于博客
1、操作一:
input:使用一张3×3、5通道的图像(对应的shape:[1,3,3,5])。filter:用一个1×1的卷积核(对应的shape:[1,1,5,1])。
padding:VALID。
strides:[1,1,1,1]。
返回tensor:是一张3×3、单通道的feature map(对应的shape:[1,3,3,1])。
这就相当于每一个像素点,卷积核都与该像素点的每一个通道做点积。
input = tf.Variable(tf.random_normal([1,3,3,5]))
filter = tf.Variable(tf.random_normal([1,1,5,1]))
op1 = tf.nn.conv2d(input, filter, strides=[1,1,1,1], padding='VALID')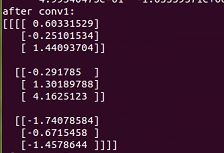
2、操作二:
input:使用一张3×3、5通道的图像(对应的shape:[1,3,3,5])。filter:用一个3×3的卷积核(对应的shape:[3,3,5,1])。
padding:VALID。
strides:[1,1,1,1]。
返回tensor:是一张1×1、单通道的feature map(对应的shape:[1,1,1,1])。
input = tf.Variable(tf.random_normal([1,3,3,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op2 = tf.nn.conv2d(input, filter, strides=[1,1,1,1], padding='VALID')![]()
3、操作三:
input:使用一张5×5、5通道的图像(对应的shape:[1,5,5,5])。filter:用一个3×3的卷积核(对应的shape:[3,3,5,1])。
padding:VALID。
strides:[1,1,1,1]。
返回tensor:是一张3×3、单通道的feature map(对应的shape:[1,3,3,1])。
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op3 = tf.nn.conv2d(input, filter, strides=[1,1,1,1], padding='VALID')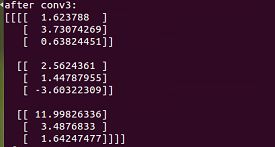
4、操作四:
input:使用一张5×5、5通道的图像(对应的shape:[1,5,5,5])。filter:用一个3×3的卷积核(对应的shape:[3,3,5,1])。
padding:SAME。
strides:[1,1,1,1]。
返回tensor:是一张5×5、单通道的feature map(对应的shape:[1,5,5,1])。
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op4 = tf.nn.conv2d(input, filter, strides=[1,1,1,1], padding='SAME')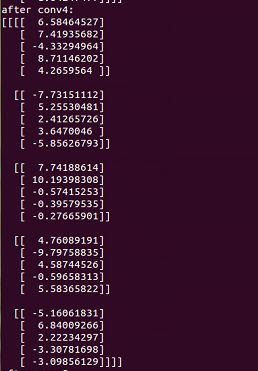
5、操作五:
input:使用一张5×5、5通道的图像(对应的shape:[1,5,5,5])。filter:用7个3×3的卷积核(对应的shape:[3,3,5,7])。
padding:SAME。
strides:[1,1,1,1]。
返回tensor:是一张5×5、7通道的feature map(对应的shape:[1,5,5,7])。
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op5 = tf.nn.conv2d(input, filter, strides=[1,1,1,1], padding='SAME')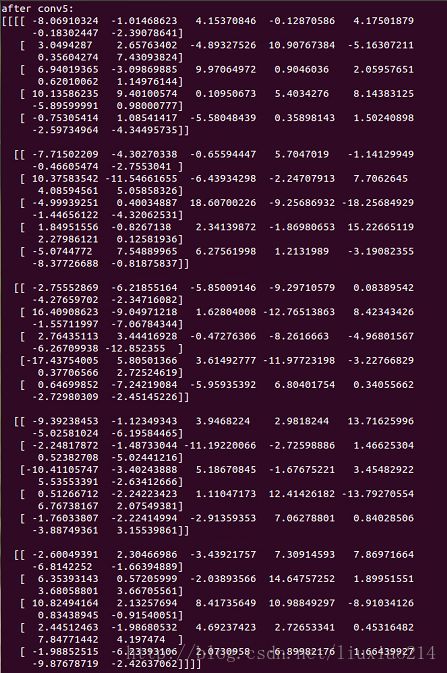
6、操作六:
input:使用一张5×5、5通道的图像(对应的shape:[1,5,5,5])。filter:用7个3×3的卷积核(对应的shape:[3,3,5,7])。
padding:SAME。
strides:[1,2,2,1]。
返回tensor:是一张3×3、7通道的feature map(对应的shape:[1,3,3,7])。
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op6 = tf.nn.conv2d(input, filter, strides=[1,2,2,1], padding='SAME')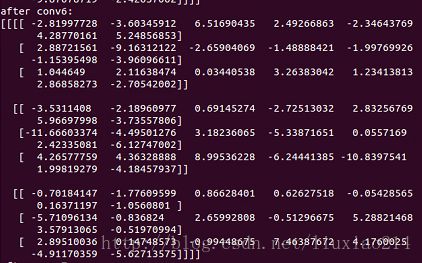
7、操作七:
input:使用10张5×5、5通道的图像(对应的shape:[10,5,5,5])。
filter:用7个3×3的卷积核(对应的shape:[3,3,5,7])。
padding:SAME。
strides:[1,2,2,1]。
返回tensor:是10张3×3、7通道的feature map(对应的shape:[10,3,3,7])。
input = tf.Variable(tf.random_normal([10,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op7 = tf.nn.conv2d(input, filter, strides=[1,2,2,1], padding='SAME')
结果太大,就截两张图的结果。
全部代码:
import tensorflow as tf
input = tf.Variable(tf.random_normal([1,3,3,5]))
filter = tf.Variable(tf.random_normal([1,1,5,1]))
op1 = tf.nn.conv2d(input, filter, strides=[1,1,1,1], padding='VALID')
input = tf.Variable(tf.random_normal([1,3,3,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op2 = tf.nn.conv2d(input, filter, strides=[1,1,1,1], padding='VALID')
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op3 = tf.nn.conv2d(input, filter, strides=[1,1,1,1], padding='VALID')
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op4 = tf.nn.conv2d(input, filter, strides=[1,1,1,1], padding='SAME')
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op5 = tf.nn.conv2d(input, filter, strides=[1,1,1,1], padding='SAME')
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op6 = tf.nn.conv2d(input, filter, strides=[1,2,2,1], padding='SAME')
input = tf.Variable(tf.random_normal([10,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op7 = tf.nn.conv2d(input, filter, strides=[1,2,2,1], padding='SAME')
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
print "images:"
print sess.run(input)
print "filter:"
print sess.run(filter)
print "after conv1:"
print sess.run(op1)
print "after conv2:"
print sess.run(op2)
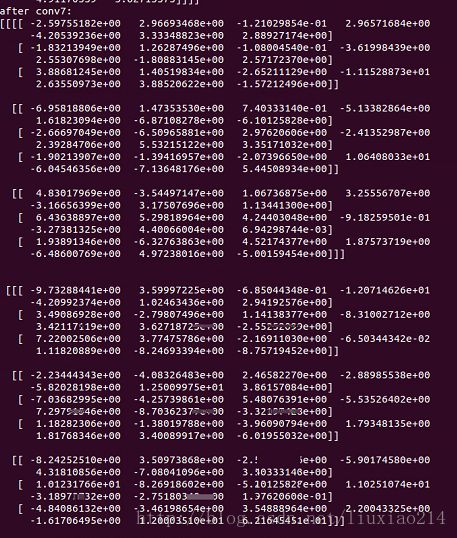
print "after conv3:"
print sess.run(op3)
print "after conv4:"
print sess.run(op4)
print "after conv5:"
print sess.run(op5)
print "after conv6:"
print sess.run(op6)
print "after conv7:"
print sess.run(op7)2、3d卷积
2.1 原理
首先,上图说明卷积是如何操作的:








在第一幅图中,左边为原输入视频(假设为单通道),一共8帧,大小为10x10,右上边为卷积滤波器,是三维的,大小为4x4x3,卷积操作就是在原输入帧上滑动滤波器窗口,滑动步长可由stride设定,这里是[2,2,1],即高和宽都是每次滑动2个步长,深度滑动1一个步长。每次原图和滤波器对应位置的像素值分别做乘法,最后将所有的乘积加起来得到的和即为新图中对应位置的像素值。最后宽和高滑动完成后,完成特征map深度上第一图,如图中绿色块。然后向后在深度上滑动一个窗口,继续做卷积,得到黄色块,依次滑动,得到紫色块,最终会得到6个图像。在这个例子中,如果采用SAME形式,最后返回的tensor是6个大小为10x10的特征map。
2.2 tf.nn.conv3d函数介绍
官网说明文档
函数原型:
conv3d(
input,
filter,
strides,
padding,
data_format=None,
name=None
)函数参数说明:
input:是需要做卷积的输入视频(连续多帧图像),要求是一个Tensor,具有[batch, in_depth, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 视频深度(几帧图像), 图片高度, 图片宽度, 图像通道数],注意这是一个5维的Tensor,要求类型为float32和float64其中之一。
filter:相当于CNN中的卷积滤波器,要求是一个Tensor,具有[filter_depth, filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的深度,卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同。注意,第四维in_channels,就是参数input的第五维。
strides:卷积时在图像每一维滑动的步长,这是一个一维的向量,长度4,一般是[1,x,x,x,1]的形式。
padding:string类型的量,取“SAME”或“VALID”,其中SAME表示需要在输入input高、宽、深维度的周围添加像素点,卷积率抱起会停留在原图边缘,保证得到的新图与原图的shape相同;VALID则表示不需要填充。
data_format:可选,string类型,取“NDHWC”或“NCDHW”,表示输入数据input的存储形式,“NDHWC” the d表示[batch, in_depth, in_height, in_width, in_channels],NCDHW”表示[batch, in_channels, in_depth, in_height, in_width]。
name:可选,表示操作的名字。
函数返回值:一个tensor,与input类型一致,维度顺序取决于data_format。
2.3 代码解释
1、操作一:
input:使用一个4帧图像,3×3、5通道的视频(对应的shape:[1,4,3,3,5])。
filter:用一个1×1×1的卷积核(对应的shape:[1,1,1,5,1])。
padding:VALID。
strides:[1,1,1,1,1]。
返回tensor:是4张3×3、单通道的feature map(对应的shape:[1,4,3,3,1])。
input = tf.Variable(tf.random_normal([1,4,3,3,5]))
filter = tf.Variable(tf.random_normal([1,1,1,5,1]))
op1 = tf.nn.conv3d(input, filter, strides=[1,1,1,1,1], padding='VALID')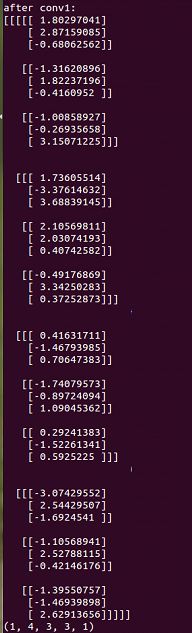
2、操作二:
input:使用一个4帧图像,3×3、5通道的视频(对应的shape:[1,4,3,3,5])。
filter:用一个2×3×3的卷积核(对应的shape:[2,3,3,5,1])。
padding:VALID。
strides:[1,1,1,1,1]。
返回tensor:是3张1×1、单通道的feature map(对应的shape:[1,3,1,1,1])。
input = tf.Variable(tf.random_normal([1,4,3,3,5]))
filter = tf.Variable(tf.random_normal([2,3,3,5,1]))
op2 = tf.nn.conv3d(input, filter, strides=[1,1,1,1,1], padding='VALID')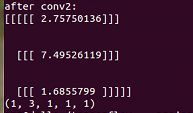
3、操作三:
input:使用一个4帧图像,5×5、5通道的视频(对应的shape:[1,4,5,5,5])。
filter:用一个2×3×3的卷积核(对应的shape:[2,3,3,5,1])。
padding:VALID。
strides:[1,1,1,1,1]。
返回tensor:是3张3×3、单通道的feature map(对应的shape:[1,3,3,3,1])。
input = tf.Variable(tf.random_normal([1,4,5,5,5]))
filter = tf.Variable(tf.random_normal([2,3,3,5,1]))
op3 = tf.nn.conv3d(input, filter, strides=[1,1,1,1,1], padding='VALID')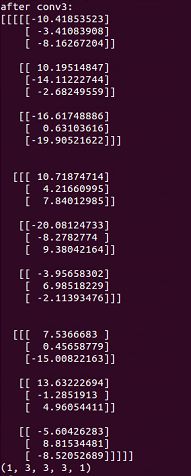
4、操作四:
input:使用一个4帧图像,5×5、5通道的视频(对应的shape:[1,4,5,5,5])。
filter:用一个2×3×3的卷积核(对应的shape:[2,3,3,5,1])。
padding:SAME。
strides:[1,1,1,1,1]。
返回tensor:是4张5×5、单通道的feature map(对应的shape:[1,4,5,5,1])。
input = tf.Variable(tf.random_normal([1,4,5,5,5]))
filter = tf.Variable(tf.random_normal([2,3,3,5,1]))
op4 = tf.nn.conv3d(input, filter, strides=[1,1,1,1,1], padding='SAME')只截取一部分:
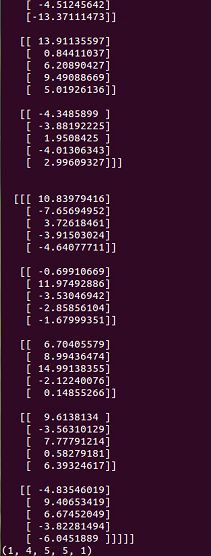
5、操作五:
input:使用一个4帧图像,5×5、5通道的视频(对应的shape:[1,4,5,5,5])。
filter:用7个2×3×3的卷积核(对应的shape:[2,3,3,5,7])。
padding:SAME。
strides:[1,1,1,1,1]。
返回tensor:是4张5×5、7通道的feature map(对应的shape:[1,4,5,5,7])。
input = tf.Variable(tf.random_normal([1,4,5,5,5]))
filter = tf.Variable(tf.random_normal([2,3,3,5,7]))
op5 = tf.nn.conv3d(input, filter, strides=[1,1,1,1,1], padding='SAME')只截取一部分:
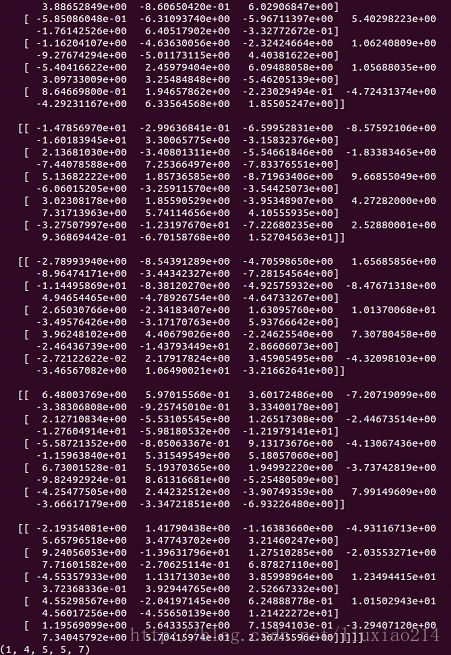
6、操作六:
input:使用一个4帧图像,5×5、5通道的视频(对应的shape:[1,4,5,5,5])。
filter:用7个2×3×3的卷积核(对应的shape:[2,3,3,5,7])。
padding:SAME。
strides:[1,2,2,2,1]。
返回tensor:是2张3×3、7通道的feature map(对应的shape:[1,2,3,3,7])。
input = tf.Variable(tf.random_normal([1,4,5,5,5]))
filter = tf.Variable(tf.random_normal([2,3,3,5,7]))
op6 = tf.nn.conv3d(input, filter, strides=[1,2,2,2,1], padding='SAME')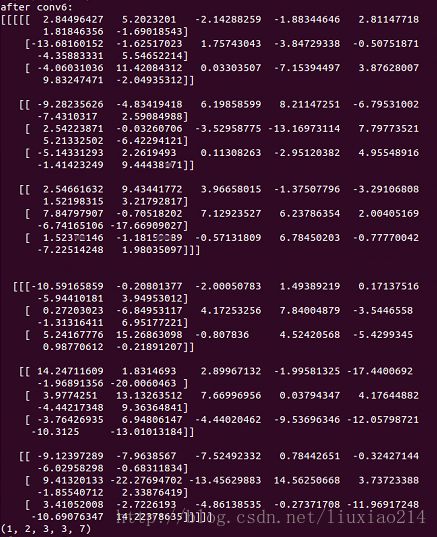
7、操作七:
input:使用10个4帧图像,5×5、5通道的视频(对应的shape:[10,4,5,5,5])。
filter:用7个2×3×3的卷积核(对应的shape:[2,3,3,5,7])。
padding:SAME。
strides:[1,2,2,2,1]。
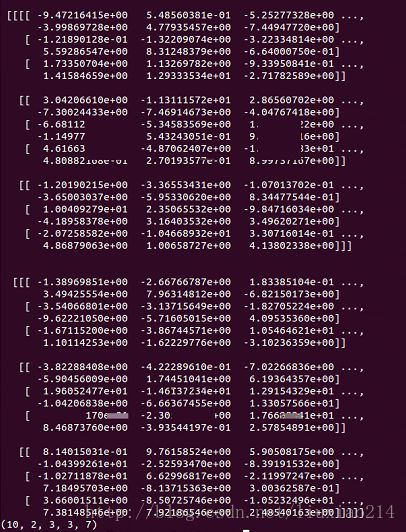
返回tensor:是2张3×3、7通道的feature map(对应的shape:[10,2,3,3,7])。
input = tf.Variable(tf.random_normal([10,4,5,5,5]))
filter = tf.Variable(tf.random_normal([2,3,3,5,7]))
op7 = tf.nn.conv3d(input, filter, strides=[1,2,2,2,1], padding='SAME')
只截取一部分:
全部代码:
import tensorflow as tf
input = tf.Variable(tf.random_normal([1,4,3,3,5]))
filter = tf.Variable(tf.random_normal([1,1,1,5,1]))
op1 = tf.nn.conv3d(input, filter, strides=[1,1,1,1,1], padding='VALID')
input = tf.Variable(tf.random_normal([1,4,3,3,5]))
filter = tf.Variable(tf.random_normal([2,3,3,5,1]))
op2 = tf.nn.conv3d(input, filter, strides=[1,1,1,1,1], padding='VALID')
input = tf.Variable(tf.random_normal([1,4,5,5,5]))
filter = tf.Variable(tf.random_normal([2,3,3,5,1]))
op3 = tf.nn.conv3d(input, filter, strides=[1,1,1,1,1], padding='VALID')
input = tf.Variable(tf.random_normal([1,4,5,5,5]))
filter = tf.Variable(tf.random_normal([2,3,3,5,1]))
op4 = tf.nn.conv3d(input, filter, strides=[1,1,1,1,1], padding='SAME')
input = tf.Variable(tf.random_normal([1,4,5,5,5]))
filter = tf.Variable(tf.random_normal([2,3,3,5,7]))
op5 = tf.nn.conv3d(input, filter, strides=[1,1,1,1,1], padding='SAME')
input = tf.Variable(tf.random_normal([1,4,5,5,5]))
filter = tf.Variable(tf.random_normal([2,3,3,5,7]))
op6 = tf.nn.conv3d(input, filter, strides=[1,2,2,2,1], padding='SAME')
input = tf.Variable(tf.random_normal([10,4,5,5,5]))
filter = tf.Variable(tf.random_normal([2,3,3,5,7]))
op7 = tf.nn.conv3d(input, filter, strides=[1,2,2,2,1], padding='SAME')
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
print "images:"
print sess.run(input)
print "filter:"
print sess.run(filter)
print "after conv1:"
print sess.run(op1)
print op1.shape
print "after conv2:"
print sess.run(op2)
print op2.shape
print "after conv3:"
print sess.run(op3)
print op3.shape
print "after conv4:"
print sess.run(op4)
print op4.shape
print "after conv5:"
print sess.run(op5)
print op5.shape
print "after conv6:"
print sess.run(op6)
print op6.shape
print "after conv7:"
print sess.run(op7)
print op7.shape
3、2d池化
3.1 原理
类似于2维卷积,只不过不做卷积操作,只取当前窗口最大值作为新图的像素值。
3.2 tf.nn.max_pool函数介绍
官网说明文档
函数原型:
max_pool(
value,
ksize,
strides,
padding,
data_format='NHWC',
name=None
)函数参数说明:
value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,要求是一个Tensor,具有[batch, height, width, channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32。
ksize:池化窗口的大小,要求是一个Tensor,具有[1, height, width, 1]这样的shape,具体含义是[1,池化窗口高度,池化窗口宽度,1]。
strides:在图像每一维滑动的步长,这是一个一维的向量,长度4,一般是[1,x,x,1]的形式。
padding:string类型的量,取“SAME”或“VALID”,其中SAME表示需要在输入input高和宽维度的周围添加像素点,池化窗口会停留在原图边缘,保证得到的新图与原图的shape相同;VALID则表示不需要填充。
data_format:可选,string类型,取“NHWC”或“NCHW”,表示输入数据input的存储形式,“NHWC” the d表示[batch, height, width, channels],NCHW”表示[batch, channels, height, width]。
name:可选,表示操作的名字。
函数返回值:一个tensor,与value类型一致,[batch, height, width, channels],维度顺序取决于data_format。
3.3 代码解释
1、操作一:
value:使用一张4×4、2通道的图像(对应的shape:[1,4,4,2])。
ksize:用一个2×2的池化窗口(对应的shape:[1,2,2,1])。
padding:VALID。
strides:[1,1,1,1]。
返回tensor:是一张3×3、2通道的feature map(对应的shape:[1,3,3,2])。
import tensorflow as tf
a=tf.constant([
[[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0],
[8.0,7.0,6.0,5.0],
[4.0,3.0,2.0,1.0]],
[[4.0,3.0,2.0,1.0],
[8.0,7.0,6.0,5.0],
[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0]]
])
a=tf.reshape(a,[1,4,4,2])
pooling=tf.nn.max_pool(a,[1,2,2,1],[1,1,1,1],padding='VALID')
with tf.Session() as sess:
print("image:")
image=sess.run(a)
print (image)
print image.shape
print("reslut:")
result=sess.run(pooling)
print (result)
print result.shape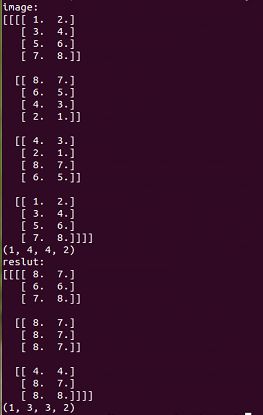
4、3d池化
4.1 原理
类似于3维卷积,只不过不做卷积操作,只取当前窗口最大值作为新图的像素值。然后深度上滑动,得到多个特征map。
4.2 tf.nn.max_pool3d函数介绍
官网说明文档
函数原型:
max_pool3d(
input,
ksize,
strides,
padding,
data_format=None,
name=None
)函数参数说明:
input:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,要求是一个Tensor,具有[batch, depth, rows, cols, channels]这样的shape,具体含义是[训练时一个batch的图片数量, 视频帧数,图片高度, 图片宽度, 图像通道数],注意这是一个5维的Tensor,要求类型为float32。
ksize:池化窗口的大小,要求是一个Tensor,具有[1, depth, height, width, 1]这样的shape,具体含义是[1,池化窗口深度,池化窗口高度,池化窗口宽度,1]。
strides:在视频每一维滑动的步长,这是一个一维的向量,长度5,一般是[1,x,x,x,1]的形式。
padding:string类型的量,取“SAME”或“VALID”,其中SAME表示需要在输入input高和宽、深维度的周围添加像素点,池化窗口会停留在原图边缘,保证得到的新视频帧与原视频帧的shape相同;VALID则表示不需要填充。
data_format:可选,string类型,取“NDHWC”或“NCDHW”,表示输入数据input的存储形式,“NDHWC” the d表示[batch, depth, height, width, channels],NCDHW”表示[batch, channels, depth, height, width]。
name:可选,表示操作的名字。
函数返回值:一个tensor,与input类型一致,[batch, depth, height, width, channels],维度顺序取决于data_format。
4.3 代码解释
1、操作一:
input:使用一个3帧图像,4×6、2通道的视频(对应的shape:[1,3,4,6,2])。
filter:用一个2×2×1的池化窗口(对应的shape:[1,2,2,1,1])。
padding:VALID。
strides:[1,1,2,2,1]。
返回tensor:是2张3×3、2通道的feature map(对应的shape:[1,2,2,3,2])。
# 3D CNN realize
import tensorflow as tf
a=tf.constant([
[
[[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0],
[8.0,7.0,6.0,5.0],
[4.0,3.0,2.0,1.0]],
[[4.0,3.0,2.0,1.0],
[8.0,7.0,6.0,5.0],
[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0]],
[[10.,9.,8.,7.],
[6.,7.,8.,9.],
[5.,6.,7.,8.],
[4.,5.,6.,7.]]
],
[
[[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0],
[8.0,7.0,6.0,5.0],
[4.0,3.0,2.0,1.0]],
[[4.0,3.0,2.0,1.0],
[8.0,7.0,6.0,5.0],
[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0]],
[[10.,9.,8.,7.],
[6.,7.,8.,9.],
[5.,6.,7.,8.],
[4.,5.,6.,7.]]
],
[
[[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0],
[8.0,7.0,6.0,5.0],
[4.0,3.0,2.0,1.0]],
[[4.0,3.0,2.0,1.0],
[8.0,7.0,6.0,5.0],
[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0]],
[[10.,9.,8.,7.],
[6.,7.,8.,9.],
[5.,6.,7.,8.],
[4.,5.,6.,7.]]
]
]
)
a=tf.reshape(a,[1,3,4,6,2])
pooling_3d=tf.nn.max_pool3d(a,[1,2,2,1,1],[1,1,2,2,1],padding='VALID')
with tf.Session() as sess:
image=sess.run(a)
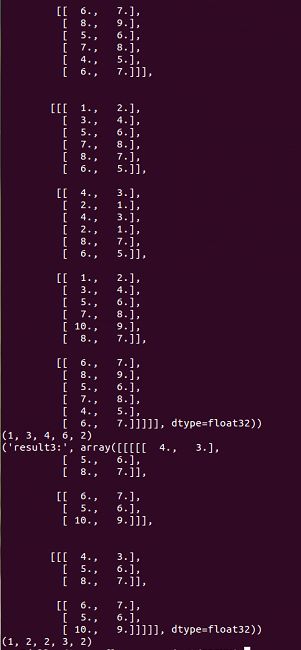
print("image:",image)
print image.shape
result3=sess.run(pooling_3d)
print("result3:",result3)
print result3.shape只截取一部分: