动手实践bert+BiLstm+crf
网上大部分都是使用ChinaPeoplesDailyNerCorpus语料做的,真正应用到自已的语料和需求中还是有一些坑,这里整理记录一下
首先明确语料需要处理成什么格式,贴图理解一下
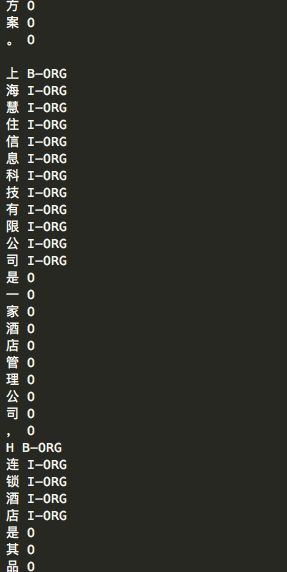
这里面需要搞清楚几点,我们的语料最小粒度是字级别的,然后每句话结束会有一个空行(当年踩过的坑),后面的标记简单科普一下,专业人士直接跳过,大O表示非实体,B-ORD表示机构开头第一个字,I-ORD表示中间,有些预料可能会有结束标记,这里只使用了开头和中间,当然你可能还需要识别人名(B-PER, I-PER),地名(B-LOC, I-LOC),同理。
接下来就要考虑如何将一段话或者一篇文章处理成这种格式了
这里参考了一篇文章https://www.cnblogs.com/combfish/p/7830807.html其中的代码直接贴在下面了,不想看的可以直接跳过看后面分析
import re
# txt2ner_train_data turn label str into ner trainable data
# s :labeled str eg.'我来到[@1999年#YEAR*]的[@上海#LOC*]的[@东华大学#SCHOOL*]'
# save_path: ner_trainable_txt name
def str2ner_train_data(s,save_path):
ner_data = []
result_1 = re.finditer(r'\[\@', s)
result_2 = re.finditer(r'\*\]', s)
begin = []
end = []
for each in result_1:
begin.append(each.start())
for each in result_2:
end.append(each.end())
assert len(begin) == len(end)
i = 0
j = 0
while i < len(s):
if i not in begin:
ner_data.append([s[i], 0])
i = i + 1
else:
ann = s[i + 2:end[j] - 2]
entity, ner = ann.rsplit('#')
if (len(entity) == 1):
ner_data.append([entity, 'S-' + ner])
else:
if (len(entity) == 2):
ner_data.append([entity[0], 'B-' + ner])
ner_data.append([entity[1], 'E-' + ner])
else:
ner_data.append([entity[0], 'B-' + ner])
for n in range(1, len(entity) - 1):
ner_data.append([entity[n], 'I-' + ner])
ner_data.append([entity[-1], 'E-' + ner])
i = end[j]
j = j + 1
f = open(save_path, 'w', encoding='utf-8')
for each in ner_data:
f.write(each[0] + ' ' + str(each[1]))
f.write('\n')
f.close()
# txt2ner_train_data turn label str into ner trainable data
# file_path :labeled multi lines' txt eg.'我来到[@1999年#YEAR*]的[@上海#LOC*]的[@东华大学#SCHOOL*]'
# save_path: ner_trainable_txt name
def txt2ner_train_data(file_path,save_path):
fr=open(file_path,'r',encoding='utf-8')
lines=fr.readlines()
s=''
for line in lines:
line=line.replace('\n','')
line=line.replace(' ','')
s=s+line
fr.close()
str2ner_train_data(s, save_path)
if(__name__=='__main__'):
s = '我来到[@1999年#YEAR*]的[@上海#LOC*]的[@东华大学#SCHOOL*]'
save_path = 's.txt'
str2ner_train_data(s, save_path)
file_path='D:\\codes\\python_codes\\SUTDAnnotator-master\\demotext\\ChineseDemo.txt.ann'
txt2ner_train_data(file_path,'s1.txt')
通过观察可以发现,我们需要将语料处理成下面这种格式
''我来到[@1999年#YEAR*]的[@上海#LOC*]的[@东华大学#SCHOOL*]''
抽象一下就是实体部分需要是[@实体部分#实名类别*]
那么接下来只需要将一段话或者一篇文章中的实体部分处理上述格式,任务很明确,直接上代码分析
# coding=utf-8
from config import *
from pymysql import *
def label_data():
'''通过查询数据库数据,然后处理'''
conn = connect(host=HOST, port=3306, database=DATABASE, user=USER,
password=PASSWORD, charset='utf8')
cs1 = conn.cursor()
sql1 = 'SELECT deal_name, company_name, introduce from dw_deals_qmp ORDER BY id limit 100'
cs1.execute(sql1)
pnlist = []
alldata = cs1.fetchall()
for s in alldata:
pnlist.append([s[0], s[1], s[2]])
cs1.close()
conn.close()
for s_li in pnlist:
deal_name = s_li[0]
company_name = s_li[1]
introduce = s_li[2]
new_intro = ''
# 处理deal_name
if deal_name in introduce:
new_intro = introduce.replace(deal_name, '[@{}#PRO*]'.format(deal_name))
# 处理company_name
if deal_name != company_name:
if company_name in introduce:
new_intro = new_intro.replace(company_name, '[@{}#COMP*]'.format(company_name))
else:
if company_name in introduce:
new_intro = introduce.replace(company_name, '[@{}#COMP*]'.format(company_name))
# 写入到chinesedemo.txt.ann
with open('/Users/Devintern/Documents/pachong/Ner/middle_corpus.txt', 'a') as f:
f.write(new_intro + '\r\n')
def custom_corpus():
deal_name = '汇盈环保'
company_name = '江西汇盈环保科技有限公司'
introduce = '金圆股份(000546)(000546.SZ)公布,公司控股子公司江西新金叶实业有限公司(“新金叶”)于2019年05月20日在浙江省兰溪市与上饶县星灿环保科技研发中心(有限合伙)及陈奇峰签订股权收购协议,以1.415亿元的价格收购江西汇盈环保科技有限公司(“江西汇盈”)100%股权。江西汇盈为资源化综合利用企业,地处江西省上饶市铅山县,已于2019年4月18日取得危险废物经营许可证(赣环危废临证字(2019)07号),核准经营规模为13.2667万吨/年。此次通过控股子公司新金叶收购江西汇盈100%股权,新增13.2667万吨/年的危险废物处置产能。江西汇盈投产后将与新金叶实现优势互补、协同发展,提高公司在资源化综合利用领域的竞争力及盈利能力,力争成为江西省资源化综合利用业务区域龙头,进一步深化落实公司环保发展战略,符合公司整体发展战略规划'
new_intro = ''
# 处理deal_name
if deal_name in introduce:
new_intro = introduce.replace(deal_name, '[@{}#ORG*]'.format(deal_name))
# 处理company_name
if deal_name != company_name:
if company_name in introduce:
new_intro = new_intro.replace(company_name, '[@{}#ORG*]'.format(company_name))
else:
if company_name in introduce:
new_intro = introduce.replace(company_name, '[@{}#ORG*]'.format(company_name))
# 写入到middle_corpus.txt
with open('/Users/Devintern/Documents/pachong/Ner/middle_corpus.txt', 'a') as f:
f.write(new_intro + '\r\n')
def main():
# 处理数据库数据
label_data()
# 处理自定义预料
# custom_corpus()
if __name__ == '__main__':
main()
简单解释一下,因为这里我的需求只是需要标记出项目名(PRO)和公司名(COMP),别的不关注,一个项目名和公司名对应一句话,所以只需要处理出这句话中的项目名和公司名就可以,需求很简单,上述有两个方法,一个是读取数据库数据然后处理,另一个方法是直接输入语料处理,选择其一就可以。简单看一下处理后的效果

接下来就直接使用上述参考的方法,这里有一些改动,我将最新的代码贴上来
import re
# txt2ner_train_data turn label str into ner trainable data
# s :labeled str eg.'我来到[@1999年#YEAR*]的[@上海#LOC*]的[@东华大学#SCHOOL*]'
# save_path: ner_trainable_txt name
def str2ner_train_data(s, save_path):
ner_data = []
result_1 = re.finditer(r'\[\@', s)
result_2 = re.finditer(r'\*\]', s)
begin = []
end = []
for each in result_1:
begin.append(each.start())
for each in result_2:
end.append(each.end())
assert len(begin) == len(end)
i = 0
j = 0
while i < len(s):
if i not in begin:
ner_data.append([s[i], 'O'])
i = i + 1
else:
ann = s[i + 2:end[j] - 2]
entity, ner = ann.rsplit('#')
if (len(entity) == 1):
ner_data.append([entity, 'B-' + ner])
# ner_data.append([entity, 'S-' + ner])
else:
if (len(entity) == 2):
ner_data.append([entity[0], 'B-' + ner])
ner_data.append([entity[1], 'I-' + ner])
# ner_data.append([entity[1], 'E-' + ner])
else:
ner_data.append([entity[0], 'B-' + ner])
for n in range(1, len(entity)):
ner_data.append([entity[n], 'I-' + ner])
# ner_data.append([entity[-1], 'E-' + ner])
i = end[j]
j = j + 1
f = open(save_path, 'a', encoding='utf-8')
for each in ner_data:
f.write(each[0] + ' ' + str(each[1]))
if each[0] == '。' or each[0] == '?' or each[0] == '!':
f.write('\n')
f.write('\n')
else:
f.write('\n')
f.close()
# txt2ner_train_data turn label str into ner trainable data
# file_path :labeled multi lines' txt eg.'我来到[@1999年#YEAR*]的[@上海#LOC*]的[@东华大学#SCHOOL*]'
# save_path: ner_trainable_txt name
def txt2ner_train_data(file_path, save_path):
fr = open(file_path, 'r', encoding='utf-8')
lines = fr.readlines()
s = ''
for line in lines:
line = line.replace('\n', '')
line = line.replace(' ', '')
s = s + line
fr.close()
str2ner_train_data(s, save_path)
if (__name__ == '__main__'):
save_path = '/Users/Devintern/Documents/pachong/Ner/train.txt'
file_path = '/Users/Devintern/Documents/pachong/Ner/middle_corpus.txt'
txt2ner_train_data(file_path, save_path)
好的,运行看看结果
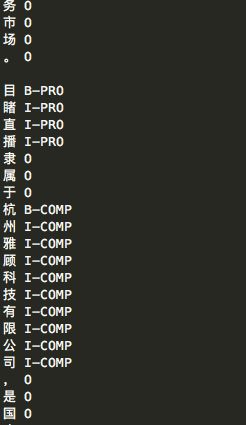
好的,训练数据处理好了,同理得到测试数据
接下来就是最核心的部分了,这里使用的是kashgari库,通过使用bert预训练模型进行字编码,然后使用Bi-Lstm获得每个类别得分,最后通过crf筛选得到最终结果。
首先你需要下载安装kashgari,很简单,执行下面命令
pip install kashgari
接下来读取上面处理好的预料
# 读取自己的预料’
train_path = '/Users/Devintern/Documents/pachong/Ner/train.txt'
test_path = '/Users/Devintern/Documents/pachong/Ner/test.txt'
def get_sequenct_tagging_data(file_path):
data_x, data_y = [], []
with open(file_path, 'r', encoding='utf-8') as f:
lines = f.read().splitlines()
x, y = [], []
for line in lines:
rows = line.split(' ')
if len(rows) == 1:
data_x.append(x)
data_y.append(y)
x = []
y = []
else:
x.append(rows[0])
y.append(rows[1])
return data_x, data_y
train_x, train_y = get_sequenct_tagging_data(train_path)
validate_x, validate_y = get_sequenct_tagging_data(test_path)
这里面的get_sequenct_tagging_data方法借鉴了ChinaPeoplesDailyNerCorpus.get_sequence_tagging_data的实现方法
接下来加载bert预训练模型,并设置句子最大长度为128,注意bert预训练模型需要自己下载,找度娘
from kashgari.embeddings import BERTEmbedding
embedding = BERTEmbedding('/Users/Devintern/Documents/BERT/bert/chinese_L-12_H-768_A-12', 128)
接着就是训练验证阶段了
from kashgari.tasks.seq_labeling import BLSTMCRFModel
# 还可以选择 `BLSTMModel` 和 `CNNLSTMModel`
model = BLSTMCRFModel(embedding)
model.fit(train_x,
train_y,
x_validate=validate_x,
y_validate=validate_y,
epochs=20,
batch_size=10)
cpu跑的,运行太慢就不等了, 看看前两轮的结果,还是很不错的

参考文章
https://github.com/BrikerMan/Kashgari