【若泽大数据实战第九天】hdfs三个进程以机器名启动的设置
1.生产上hdfs三个进程要以hadoop002(机器名)启动
上篇文章中,namenode、datanode是以localhost启动的,secondarynamenode是以0.0.0.0启动的,而实际生产中,这三个都是以机器名启动的。所以现在修改一下。
进入/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop目录
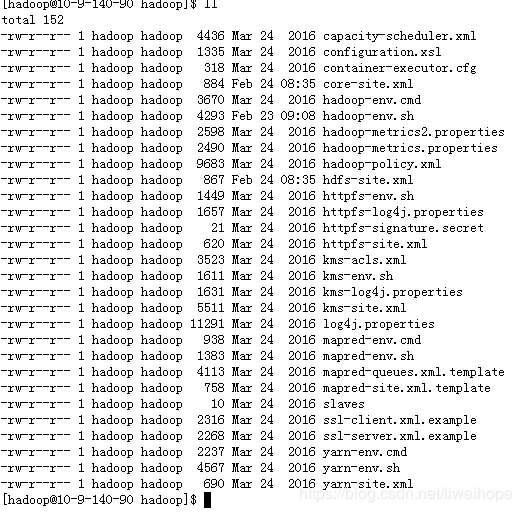
可以看到这里面有很多配置文件,其中常用的有:
core-site.xml 这个是把hdfs、mapreduce、yarn核心的共有的提供出来,配置在这里面。特有的在它们自己的配置文件里面配。
hadoop-env.sh 这个是配置 JDK目录 hadoop家目录
hdfs-site.xml
log4j.properties
mapred-site.xml.template
slaves
yarn-site.xml
hdfs在这里面配置:hdfs-site.xml,yarn在这里面配置:yarn-site.xml,mapreduce不需要配置。
生产 学习: 不用ip部署,统一机器名称hostname部署。因为有时候会要求ip变更,机器名是不会变更的,如果用ip部署,会出现问题。
修改ip,只需要/etc/hosts 修改即可(第一行 第二行不要删除)

修改namenode进程:
vi core-site.xml 这个文件,把里面的localhost修改为机器名(机器名用hostname查看)
datanode进程:
vi slaves
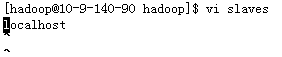 把localhost修改成机器名,如果以后有多个datanode,以逗号分隔即可。
把localhost修改成机器名,如果以后有多个datanode,以逗号分隔即可。
secondarynamenode进程:
vi hdfs-site.xml 添加和下面一样:

在官网可以找到下图的配置文件的默认值:点击进去可以查看各个参数默认值。

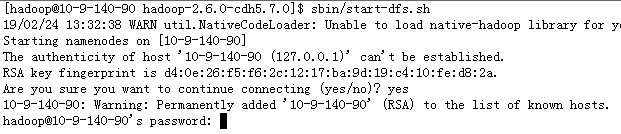
上面配置完机器名之后,再sbin/start-dfs.sh 启动haooop(之前已经停止掉了)

这个时候出现了ssh信任关系问题了,因为之前配置的ssh信任关系是localhost,现在修改成了机器名。所以还要重新来一遍ssh信任关系。(其实上面直接输入yes也是可以的)
重新构建ssh信任关系 之前的配置也是可以的,但是我们为了统一 重新再来一次配置

[hadoop@10-9-140-90 ~]$ rm -rf .ssh
[hadoop@10-9-140-90 ~]$ ssh-keygen
[hadoop@10-9-140-90 ~]$cd .ssh
[hadoop@10-9-140-90 .ssh]$ cat id_rsa.pub >> authorized_keys
[hadoop@10-9-140-90 .ssh]$ ll
total 12
-rw-rw-r-- 1 hadoop hadoop 400 Feb 24 13:30 authorized_keys
-rw------- 1 hadoop hadoop 1675 Feb 24 13:28 id_rsa
-rw-r--r-- 1 hadoop hadoop 400 Feb 24 13:28 id_rsa.pub
然后再启动hadoop
这又是之前讲的权限问题了,需要chmod 600 authorized_keys一下:
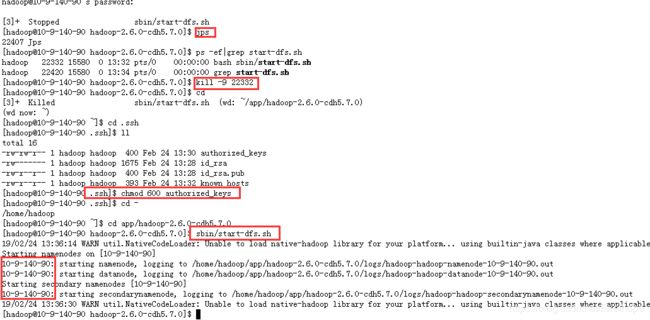
通过上面的步骤,就可以启动三个进程了,而且可以发现三个进程都是通过机器名启动了。