Hadoop学习(十六)——flume原理及案例
笔者是一个痴迷于挖掘数据中的价值的学习人,希望在平日的工作学习中,挖掘数据的价值,找寻数据的秘密,笔者认为,数据的价值不仅仅只体现在企业中,个人也可以体会到数据的魅力,用技术力量探索行为密码,让大数据助跑每一个人,欢迎直筒们关注我的公众号,大家一起讨论数据中的那些有趣的事情。
我的公众号为:livandata

在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集、结果数据导出、任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中都有便捷的开源框架,如图所示:

1. 日志采集框架Flume
1.1 Flume介绍
1.1.1 概述
u Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
u Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS、hbase、hive、kafka等众多外部存储系统中
u 一般的采集需求,通过对flume的简单配置即可实现
u Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
1.1.2 运行机制
1、 具体流程可以看一下:http://www.cnblogs.com/zhangyinhua/p/7803486.html,写得很全面。
2、 Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成
3、 每一个agent相当于一个数据传递员( Source 到 Channel 到 Sink之间传递数据的形式是Event事件;Event事件是一个数据流单元。),内部有三个组件:
a) Source:采集源,用于跟数据源对接,以获取数据。
b) Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据。
c) Channel:angent内部的数据传输通道,用于从source将数据传递到sink,
Source与sink都有一个统一的父类,
1.1.4 Flume采集系统结构图
1. 简单结构
单个agent采集数据

2. 复杂结构
多级agent之间串联,可以实现多个agent融合到一个agent中。
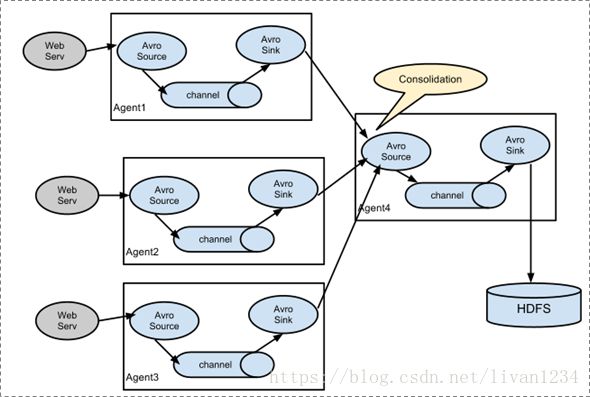

1.2 Flume实战案例
1.2.1 Flume的安装部署
1、Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境
上传安装包到数据源所在节点上
然后解压 tar -zxvfapache-flume-1.6.0-bin.tar.gz
然后进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME
2、根据数据采集的需求配置采集方案,描述在配置文件中(文件名可任意自定义)
3、指定采集方案配置文件,在相应的节点上启动flume agent
先用一个最简单的例子来测试一下程序环境是否正常
1、先在flume的conf目录下新建一个文件
vi netcat-logger.conf
| # 定义这个agent中各组件的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 描述和配置source组件:r1 # 类型:具体实现的名称,如果接受linux下的nc端口,则为这个名称,下面为绑定的IP和端口 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost # 如果需要其他电脑访问,则可以将本机的机器名设置上。 a1.sources.r1.port = 44444 # 描述和配置sink组件:k1 a1.sinks.k1.type = logger #如果要下沉到屏幕上则显示为console # 描述和配置channel组件,此处使用是内存缓存的方式 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 # 1000条记录传输一次; a1.channels.c1.transactionCapacity = 100 # 描述和配置source、channel、sink之间的连接关系 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
2、启动agent去采集数据
在启动agent之前,需要先将hadoop启动起来,否则会报:ERROR node.Application: A fatal error occurred while running.错误,错误会显示netcat-logger.conf文件不存在,此时启动一下hadoop集群就好了。
| ./bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console |
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.con 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
启动完成后,服务端的样式为:

3、测试
先要往agent采集监听的端口上发送数据,让agent有数据可采。
在本机(也可以在有网络通讯的其他电脑)上在起一个CRT端口,telnet44444 端口,并向这个端口发送数据:
telnet anget-hostname port :(telnetlocalhost 44444)

此时就会产生数据流,flume会采集这个数据流,并以一个event的形式传输给后台:

上面为按照telnet方式,下面可以进行其他方式的处理,主要是对conf文件的处理;
1)对HDFS日志文件的获取,即设置固定文件夹,如果文件夹中存在内容,则flume会按行将数据读取出来,存放到指定的位置中;

2)向/usr/apps/hadoop/hadoop-2.6.5/flumespool文件夹中放文件,然后在后台查看:

编写一个test.txt文件,将其move到flumespool文件夹下面,flume会自动将flumespool下面的文件导入到后台:

与此同时,flumespool中的文件会添加后缀:.COMPLETED;

1.2.2 采集案例
1)采集目录到HDFS
采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去
根据需求,首先定义以下3大要素
l 采集源,即source——监控文件目录 : spooldir
l 下沉目标,即sink——HDFS文件系统 : hdfs sink
l source和sink之间的传递通道——channel,可用filechannel 也可以用内存channel
配置文件编写:
| #定义三大组件的名称 agent1.sources = source1 agent1.sinks = sink1 agent1.channels = channel1 # 配置source组件 agent1.sources.source1.type = spooldir agent1.sources.source1.spoolDir = /home/hadoop/logs/ agent1.sources.source1.fileHeader = false #配置拦截器 agent1.sources.source1.interceptors = i1 agent1.sources.source1.interceptors.i1.type = host agent1.sources.source1.interceptors.i1.hostHeader = hostname # 配置sink组件 agent1.sinks.sink1.type = hdfs agent1.sinks.sink1.hdfs.path =hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H-%M agent1.sinks.sink1.hdfs.filePrefix = access_log agent1.sinks.sink1.hdfs.maxOpenFiles = 5000 agent1.sinks.sink1.hdfs.batchSize= 100 agent1.sinks.sink1.hdfs.fileType = DataStream agent1.sinks.sink1.hdfs.writeFormat =Text agent1.sinks.sink1.hdfs.rollSize = 102400 agent1.sinks.sink1.hdfs.rollCount = 1000000 agent1.sinks.sink1.hdfs.rollInterval = 60 #agent1.sinks.sink1.hdfs.round = true #agent1.sinks.sink1.hdfs.roundValue = 10 #agent1.sinks.sink1.hdfs.roundUnit = minute agent1.sinks.sink1.hdfs.useLocalTimeStamp = true # Use a channel which buffers events in memory agent1.channels.channel1.type = memory agent1.channels.channel1.keep-alive = 120 agent1.channels.channel1.capacity = 500000 agent1.channels.channel1.transactionCapacity = 600 # Bind the source and sink to the channel agent1.sources.source1.channels = channel1 agent1.sinks.sink1.channel = channel1 |
Channel参数解释:
capacity:默认该通道中最大的可以存储的event数量
trasactionCapacity:每次最大可以从source中拿到或者送到sink中的event数量
keep-alive:event添加到通道中或者移出的允许时间
2)采集文件到HDFS
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs。
根据需求,首先定义以下3大要素:
l 采集源,即source——监控文件内容更新 : exec ‘tail -F file’
l 下沉目标,即sink——HDFS文件系统 : hdfs sink
l Source和sink之间的传递通道——channel,可用filechannel 也可以用内存channel
配置文件编写:
| agent1.sources = source1 agent1.sinks = sink1 agent1.channels = channel1 # Describe/configure tail -F source1 agent1.sources.source1.type = exec agent1.sources.source1.command = tail -F /home/hadoop/logs/access_log agent1.sources.source1.channels = channel1 #configure host for source agent1.sources.source1.interceptors = i1 agent1.sources.source1.interceptors.i1.type = host agent1.sources.source1.interceptors.i1.hostHeader = hostname # Describe sink1 agent1.sinks.sink1.type = hdfs #a1.sinks.k1.channel = c1 agent1.sinks.sink1.hdfs.path =hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H-%M agent1.sinks.sink1.hdfs.filePrefix = access_log agent1.sinks.sink1.hdfs.maxOpenFiles = 5000 agent1.sinks.sink1.hdfs.batchSize= 100 agent1.sinks.sink1.hdfs.fileType = DataStream # 生成的文件类型,默认是sequencefile,可用datastream,则为普通文本; agent1.sinks.sink1.hdfs.writeFormat =Text agent1.sinks.sink1.hdfs.rollSize = 102400 # 产生多大的文件就发生滚动; agent1.sinks.sink1.hdfs.rollCount = 1000000 # 发生了多少个事件就发生滚动; agent1.sinks.sink1.hdfs.rollInterval = 60 # rollInterval:文件滚动周期; agent1.sinks.sink1.hdfs.round = true agent1.sinks.sink1.hdfs.roundValue = 10 # 10分钟生成一个新的目录; agent1.sinks.sink1.hdfs.roundUnit = minute agent1.sinks.sink1.hdfs.useLocalTimeStamp = true # Use a channel which buffers events in memory agent1.channels.channel1.type = memory agent1.channels.channel1.keep-alive = 120 agent1.channels.channel1.capacity = 500000 agent1.channels.channel1.transactionCapacity = 600 # Bind the source and sink to the channel agent1.sources.source1.channels = channel1 agent1.sinks.sink1.channel = channel1 |
1.3 更多source和sink组件
Flume支持众多的source和sink类型,详细手册可参考官方文档
http://flume.apache.org/FlumeUserGuide.html

Exec:执行命令;
Tail:当有tail命令运行时,对应的tail的数据就会被收集出来;
也会用到其他的命令:比如软链接与硬链接;

Source是用来链接收集端的,相对比较简单;Sink端需要将数据下沉,其对应的配置较多。
1.4 flume中多个agent的连接:
从tail命令获取数据发送到avro端口,另一个节点可配置一个avro源来中继数据,发送外部存储:
串联的机器为:
##################
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/log/test.log
a1.sources.r1.channels = c1
# Describe the sink
#绑定的不是本机, 是另外一台机器的服务地址, sink端的avro是一个发送端, avro的客户端, 往hadoop01这个机器上发
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = master #另一台服务器的名称;
a1.sinks.k1.port = 8888
a1.sinks.k1.batch-size = 2
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
另一个机器上的avro需要绑定一个固定的端口,即8888端口:

另一台机器(被串联)的配置为:
从avro端口接收数据,下沉到logger
bin/flume-ng agent -c conf -f conf/avro-logger.conf -n al-Dflume.root.logger=INFO,console
#########
采集配置文件,avro-hdfs.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#source中的avro组件是接收者服务, 绑定本机
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 8888
# Describe the sink
a1.sinks.k1.type = logger # 可以立刻在屏幕上显示出来
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
发送数据:
$ bin/flume-ng avro-client -H localhost -p 4141 -F /usr/logs/log.10
Flume存在一些问题,即如果串联的flume一旦挂掉,就需要重启服务,然后再串联使用,无法实现flume的高可用。