人生苦短,我用Python(三)— 全字段爬取 EasyChair Smart CFP
上一篇博文介绍了一个过程化编程实现的爬虫,可以爬取EasyChair Smart CFP的七个字段。这次我们介绍CrawlerEasychair2.0版,应用面向对象模式,引入python类和方法。
制定爬取策略
接上一篇博文,我们可以得到每个CFP页面的具体Link,访问这些链接,观察它们的页面格式:

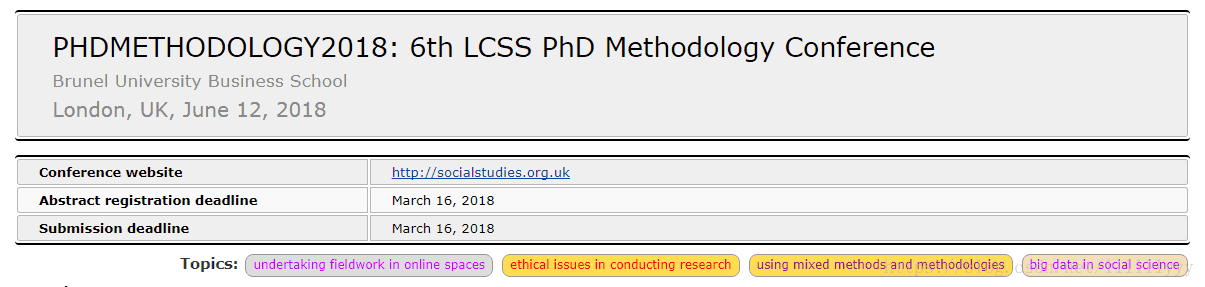
标题中的会议名称、时间、地点,下方的Topics字段已经在上一个爬虫中抓取到了,这样我们的抓取对象就是中间那个表格中的信息了。
需要注意的是,抓取的表格信息不能仅是右侧一列具体的值,左侧的属性名称也要抓取下来,并用字典{key : value}的形式储存下来;同时需要注意到,字段数目是不固定的,所以不可能用写列表的方法写入文件,下面会详细讲解。
所以,爬虫的具体流程是这样的:
- 从文件中读取/先爬取link, link入队;
- link出队,爬取表格中字段,生成字典;
- 字典写入文件;
- 可根据需要与上篇博文中的文件进行连接,用来连接的码就是Link。
面向对象编程
依据爬取策略的分析,我们的爬虫类应该至少包含三个方法:
class EasyChair(object):
def __init__(self):
pass
'''
爬取Link,Link入队
'''
def getLink(self):
pass
'''
Link出队,爬取字段,生成字典
'''
def getItems(self):
pass
'''
字典写入文件
'''
def writeCsv(self):
pass字典生成过程
# 抓取表格,生成字典
selector = etree.HTML(content)
# 提取左侧属性名称 //*[@id="cfp"]/table[2]/tbody/tr[1]/td[1]
thead = selector.xpath('//*[@id="cfp"]/table[2]/tr/td[1]/text()')
# 提取右侧具体内容
tcontent = selector.xpath('//*[@id="cfp"]/table[2]/tr/td[2]')
tds = []
for td in tcontent:
tds.append(td.xpath('string(.)'))
# 使用dict()函数将两个列表转成字典形式:{thead:tds}
table = dict(zip(thead,tds))
# 字典存入列表
table_list = []
table_list.append(table)Ps:
Chrome生成的xpath是不能直接应用到代码中的,必须作适当的修改:
- 原xpath:
//*[@id="cfp"]/table[2]/tbody/tr[1]/td[1],表示第一行第一列,且自动添补了标签; - 修改后xpath:
//*[@id=”cfp”]/table[2]/tr/td[1]/text(),表示所有行的第一列文本内容,返回一个列表; xpath('string(.)')是处理td标签中有其他标签的情况,如下图:

selector.xpath('//*[@id="cfp"]/table[2]/tr[1]/td[2]').xpath('string(.)')会匹配第一行第二列标签中的所有文本内容,而不管中间是否有或者有多少个子标签,即会忽略图中标签。
字典写入文件操作
写入文件的时候我们会遇到字典内容不一致的难题,我用一种比较简单直接的方式来解释:
问题:
有三个字典,{‘name’:’小明’, ‘sex’:’M’, ‘ID’:’001′},{‘name’:’小红’, ‘sex’:’F’, ‘class’:’A’},{‘name’:’小刚’, ‘ID’:’003′},怎样才能把它们按下面的格式写入文件呢?结果:
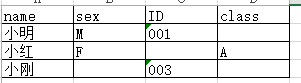
写文件时,首先要写表头,所以我们必须要求得所有属性名称的集合。但是感觉写循环遍历所有字典的key太傻(没错,我就是这么觉得,太蠢了,简直跟卖萌差不多~( ̄▽ ̄)~*),而且随着数据量的增加,复杂度也会增大。
这时候,python内建函数map()和reduce()的强大之处就体现出来了。具体内容就不在这里详细介绍了,可以参考这篇博文:http://www.cnblogs.com/shiyu404/p/5945161.html,博主也是受这篇博文的启发才写出下面三种方法。
解决上述问题的代码如下:
# _*_ coding: UTF-8 _*_
s1 = {'name':'小明', 'sex':'M', 'ID':'001'}
s2 = {'name':'小红', 'sex':'F', 'class':'A'}
s3 = {'name':'小刚', 'ID':'003'}
s_list = []
s_list.append(s1)
s_list.append(s2)
s_list.append(s3)
for s in s_list:
print s.viewkeys()
# 方法一:
# 判断s2和s3中是否有s1中没有的key
res = list(s1.viewkeys())
for s in s_list:
for k in s:
if k not in res:
res.append(k)
print "方法一:"
print res
# 方法二: 字典数目确定且较少
total = s1.viewkeys() | s2.viewkeys() | s3.viewkeys()
print "方法二:"
print list(total)
# 方法三:字典数目不确定
# lambda表达式,即匿名函数
# map和reduce的作用: map(f,list) reduce(f,list)
# reduce的f参数必须是两个!!!
result = reduce(lambda x,y:x|y, map(dict.viewkeys, s_list))
print "方法三:"
print list(result)运行结果:
dict_keys(['ID', 'name', 'sex'])
dict_keys(['class', 'name', 'sex'])
dict_keys(['name', 'ID'])
方法一:
['ID', 'name', 'sex', 'class']
方法二:
['ID', 'class', 'name', 'sex']
方法三:
['ID', 'class', 'name', 'sex']有了上面的实践为基础,回到我们的爬虫,它写文件的方法实现如下:
def writeCsv(self):
table_list = self.getItems()
# 取key的并集
key_total = reduce(lambda x,y:x|y, map(dict.viewkeys, table_list))
# 写入csv文件
with open('easychair.csv', 'wb',) as f:
# 表头在这里传入,作为第一行数据
writer = csv.DictWriter(f, key_total)
writer.writeheader()
# 写入多行数据
writer.writerows(table_list)Ps:
- 把字典写入csv文件调用的是DictWriter()函数,而将列表写入csv时调用的是write()函数。
- 而且还要记得调用writeheader()函数写入表头。
完整代码
# coding:utf-8
'''
Created on 2018年1月22日
爬取策略:
- 从文件中读取/先爬取link, link入队
- link出队,爬取字段,生成字典,写入文件
- 根据link/Acronym连接两个表格
@author: li_yan
'''
import urllib2
from lxml import etree
import time
import csv
from Queue import Queue
import sys
import socket
reload(sys)
sys.setdefaultencoding('utf-8')
class EasyChair(object):
def __init__(self, pagenum, q): # q 用来存链接
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
self.pagenum = pagenum
self.q = q
def getLink(self):
url = 'https://easychair.org/cfp/area.cgi?area=' + str(self.pagenum)
try:
request = urllib2.Request(url, headers=self.headers)
response = urllib2.urlopen(request)
html = response.read()
response.close()
# lxml 抓取link //*[starts-with(@id,"row") and @class="yellow"]/td[1]/a
selector = etree.HTML(html)
links = selector.xpath('//*[starts-with(@id,"row") and @class="yellow"]/td[1]/a/@href')
for link in links:
self.q.put(link)
except urllib2.URLError, e:
if hasattr(e, 'code'):
print e.code
if hasattr(e, 'reason'):
print e.reason
def getItems(self):
self.getLink()
table_list = []
while not self.q.empty():
try:
chilurl = self.q.get()
#time.sleep(1)
request = urllib2.Request(chilurl, headers = self.headers)
response = urllib2.urlopen(request)
content = response.read()
response.close()
# 抓取表格,生成字典 //*[@id="cfp"]/table[2]/tbody/tr[1] //*[@id="cfp"]/table[2]/tbody/tr[1]/td[1]
selector = etree.HTML(content)
thead = selector.xpath('//*[@id="cfp"]/table[2]/tr/td[1]/text()')
tcontent = selector.xpath('//*[@id="cfp"]/table[2]/tr/td[2]')
tds = []
for td in tcontent:
tds.append(td.xpath('string(.)'))
thead.append('Link')
tds.append(chilurl)
table = dict(zip(thead,tds))
print table
table_list.append(table)
except urllib2.URLError, e:
if hasattr(e, 'code'):
print e.code
if hasattr(e, 'reason'):
print e.reason
except socket.error, e:
if hasattr(e, 'code'):
print e.code
if hasattr(e, 'reason'):
print e.reason
time.sleep(10)
return table_list
def writeCsv(self):
table_list = self.getItems()
# 取key的并集,
key_total = reduce(lambda x,y:x|y, map(dict.viewkeys, table_list))
for key in key_total:
print key
# 写入csv文件
with open('1.csv', 'wb',) as f:
# 表头在这里传入,作为第一行数据
writer = csv.DictWriter(f, key_total)
csv.DictWriter
writer.writeheader()
# 写入多行数据
writer.writerows(table_list)
if __name__ == '__main__':
num = 1 #1~24
q = Queue()
spider = EasyChair(num,q)
spider.writeCsv()Ps:
- 代码中涉及到队列操作,就是很简单的q.put()和q.get(),这里就不赘述啦 。
- 因为访问过快会被ban,所以用
except socket.error忽略错误,如果出现错误则sleep(10)。
程序运行结果
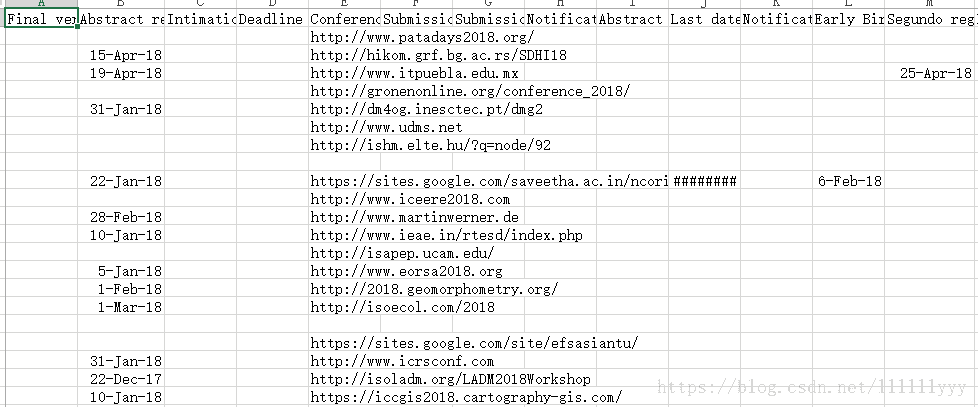
可以看出,爬取的表格非常大,有的字段可能只有一两条CFP有具体的值,其他CFP该字段都为空……
附上源码地址:https://github.com/lyandut/CrawlerEasychair.git
综合楼4F
18/02/01晚