记一次 Centos7.4 搭建 Hadoop 3.2.0(HA) YARN(HA)集群
一、基本信息
官网 http://hadoop.apache.org/
快速入门 http://hadoop.apache.org/docs/r1.0.4/cn/quickstart.html
在线文档 http://tool.oschina.net/apidocs/apidoc?api=hadoop
易百教程 https://www.yiibai.com/hadoop/
W3Cschool教程 https://www.w3cschool.cn/hadoop/?
二、环境、工具说明
1、操作系统 Centos7.4 x64 Minimal 1708
安装5台虚拟机
NameNode :2台 2G内存 1核CPU
DataNode :3台 2G内存 1核CPU
2、JDK版本:jdk1.8
3、工具:xshell5
4、VMware 版本:VMware Workstation Pro15
5、Hadoop:3.2.0
6、Zookeeper:3.4.5
三、安装部署(基础环境准备)
1、虚拟机安装(安装5台虚拟机)
参考 https://blog.csdn.net/llwy1428/article/details/89328381
2、每台虚拟机均接入互联网(5个节点均要配置好网卡)
网卡配置可参考:
https://blog.csdn.net/llwy1428/article/details/85058028
3、修改主机名(5个节点均要修改主机名)
编辑集群中的各个节点主机名(以第一个节点 node1.cn 为例)
[root@localhost~]# hostnamectl set-hostname node1.cnnode1.cn
node2.cn
node3.cn
node4.cn
node5.cn4、JDK8环境搭建(5个节点均要搭建)
参考 https://blog.csdn.net/llwy1428/article/details/85232267
5、配置防火墙(5个节点均要操作)
关闭防火墙,并设置开机禁止启动
关闭防火墙 : systemctl stop firewalld
查看状态 : systemctl status firewalld
开机禁用 : systemctl disable firewalld6、配置静态IP
此处以node1.cn节点为例(其他节点 略):
[[email protected] ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33说明:红框内为修改、增加的部分
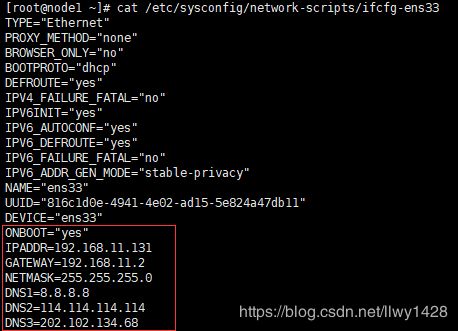
可参考:https://blog.csdn.net/llwy1428/article/details/85058028
7、配置hosts文件
此处以node1.cn节点为例:
[root@node1 ~]# vim /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.11.131 node1.cn
192.168.11.132 node2.cn
192.168.11.133 node3.cn
192.168.11.134 node4.cn
192.168.11.135 node5.cn
8、安装基本工具
[root@node1 ~]# yum install -y vim wget lrzsz tree zip unzip net-tools ntp
[root@node1 ~]# yum update -y (可选)(根据自身的网络情况,可能需要等待几分钟)
9、配置节点间免密登录
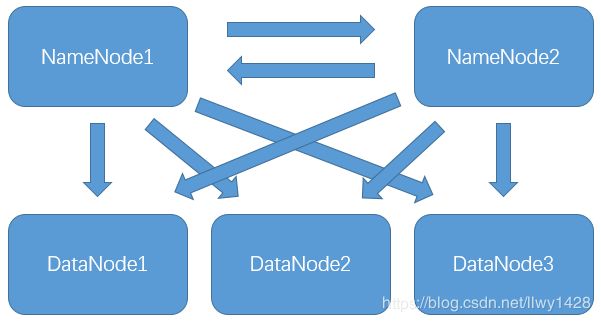
具体步骤参照:
https://blog.csdn.net/llwy1428/article/details/85911160
https://blog.csdn.net/llwy1428/article/details/85641999
10、集群各节点修改系统文件打开数
此处以node1.cn节点为例:
[root@node1 ~]# vim /etc/security/limits.conf参考
https://blog.csdn.net/llwy1428/article/details/89389191
11、集群各节点配置时间同步
本文以阿里时间服务器为准,阿里云时间服务器地址:ntp6.aliyun.com
说明:如有专用时间服务器,请更改时间服务器的主机名或者IP地址,主机名需要在etc/hosts文件中做好映射。
以node1.cn为例:
设置系统时区为东八区(上海时区)
[root@node1 ~]# timedatectl set-timezone Asia/Shanghai关闭ntpd服务
[root@node1 ~]# systemctl stop ntpd.service设置ntpd服务禁止开机启动
[root@node1 ~]# systemctl disable ntpd设置定时任务
[root@node1 ~]# crontab -e写入以下内容(每10分钟同步一下阿里云时间服务器):
0-59/10 * * * * /usr/sbin/ntpdate ntp6.aliyun.com重启定时任务服务
[root@node1 ~]# /bin/systemctl restart crond.service设置定时任务开机启动
[root@node1 ~]# vim /etc/rc.local加入以下内容后,保存并退出 :wq
/bin/systemctl start crond.service
集群中其他各个节点同node1.cn节点。
参考 https://blog.csdn.net/llwy1428/article/details/89330330
12、集群各节点禁用SELinux
以node1.cn为例:
[root@node1 ~]# vim /etc/selinux/config修改如下内容后,保存并退出 :wq
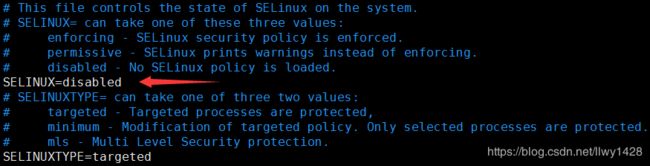
集群中其他各个节点同node1.cn节点。
13、集群各节点禁用Transparent HugePages
参考 https://blog.csdn.net/llwy1428/article/details/89387744
14、配置系统环境为UTF8
以node1.cn为例:
[root@node1 ~]# echo "export LANG=zh_CN.UTF-8 " >> ~/.bashrc
[root@node1 ~]# source ~/.bashrc集群中其他各个节点同node1.cn节点。
15、安装数据库
说明:安装MariaDb(Mysql)是为了给Hive、Spark、Oozie、Superset等提供元数据支持,如果用不到这些工具可以不安装Mysql数据库。
MariaDb(Mysql)安装过程可参照:
https://blog.csdn.net/llwy1428/article/details/84965680
https://blog.csdn.net/llwy1428/article/details/85255621
四、安装部署Hadoop集群(HA模式)
(注意:集群搭建和运行过程中,要确保集群中所有节点的时间要同步)
1、创建目录、文件上传、
说明:先在 node1.cn 上配置好基本信息,再把配置好的文件分发给各个节点,再进行进一步配置
在各个节点上创建目录 /opt/cluster/
以node1.cn为例:
[root@node1 ~]# mkdir /opt/cluster2、文件下载(文件上传)、解压缩
直接下载
[root@node1 opt]# wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz或
手动下载文件:hadoop-3.2.0.tar.gz
把已下载好的文件 hadoop-3.2.0.tar.gz 上传至 /opt/cluster 路径下,并解压缩 hadoop-3.2.0.tar.gz
进入 /opt/cluster 目录
解压文件
[root@node1 cluster]# tar zxvf hadoop-3.2.0.tar.gz查看目录结构
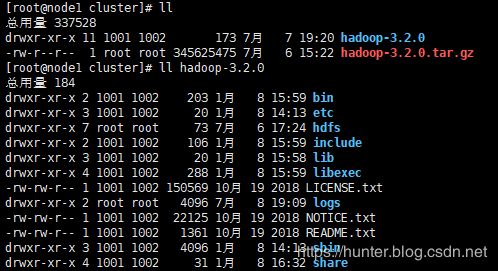
3、在 hadoop 中创建几个目录
[root@node1 ~]# mkdir /opt/cluster/hadoop-3.2.0/hdfs
[root@node1 ~]# mkdir /opt/cluster/hadoop-3.2.0/hdfs/tmp
[root@node1 ~]# mkdir /opt/cluster/hadoop-3.2.0/hdfs/name
[root@node1 ~]# mkdir /opt/cluster/hadoop-3.2.0/hdfs/data
[root@node1 ~]# mkdir /opt/cluster/hadoop-3.2.0/hdfs/journaldata
4、配置 hadoop 环境变量(追加 hadoop 的环境变量信息)
[root@node1 ~]# vim /etc/profile
在最后追加如下信息
export HADOOP_HOME="/opt/cluster/hadoop-3.2.0"
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
保存退出 :wq
使配置文件生效
[root@node1 ~]# source /etc/profile查看版本
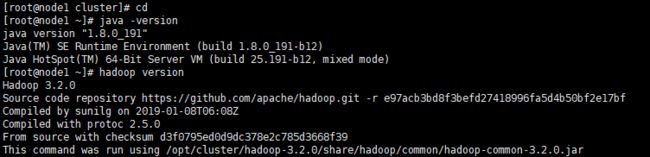
5、配置 hadoop-env.sh
[root@node1 ~]# vim /opt/cluster/hadoop-3.2.0/etc/hadoop/hadoop-env.sh增加如下内容
export JAVA_HOME=/opt/utils/jdk1.8.0_191
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
5、配置 core-site.xml
[root@node1 ~]# vim /opt/cluster/hadoop-3.2.0/etc/hadoop/core-site.xml
fs.defaultFS
hdfs://cluster
hadoop.tmp.dir
/opt/cluster/hadoop-3.2.0/hdfs/tmp
ha.zookeeper.quorum
node3.cn:2181,node4.cn:2181,node5.cn:2181
6、编辑文件 hdfs-site.xml
[root@node1 ~]# vim /opt/cluster/hadoop-3.2.0/etc/hadoop/hdfs-site.xml
dfs.nameservices
cluster
dfs.ha.namenodes.cluster
nn1,nn2
dfs.replication
3
dfs.namenode.rpc-address.cluster.nn1
node1.cn:8020
dfs.namenode.rpc-address.cluster.nn2
node2.cn:8020
dfs.namenode.http-address.cluster.nn1
node1.cn:50070
dfs.namenode.http-address.cluster.nn2
node2.cn:50070
dfs.namenode.shared.edits.dir
qjournal://node3.cn:8485;node4.cn:8485;node5.cn:8485/cluster
dfs.namenode.name.dir
file:/opt/cluster/hadoop-3.2.0/hdfs/name
dfs.datanode.data.dir
file:/opt/cluster/hadoop-3.2.0/hdfs/data
dfs.journalnode.edits.dir
/opt/cluster/hadoop-3.2.0/hdfs/edits
dfs.ha.automatic-failover.enabled
true
dfs.journalnode.edits.dir
/opt/cluster/hadoop-3.2.0/hdfs/journaldata
dfs.client.failover.proxy.provider.cluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
shell(/bin/true)
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.namenode.datanode.registration.ip-hostname-check
false
7、编辑文件 mapred-site.xml
[root@node1 ~]# vim /opt/cluster/hadoop-3.2.0/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=/opt/cluster/hadoop-3.2.0
mapreduce.map.env
HADOOP_MAPRED_HOME=/opt/cluster/hadoop-3.2.0
mapreduce.reduce.env
HADOOP_MAPRED_HOME=/opt/cluster/hadoop-3.2.0
mapreduce.jobhistory.address
node1.cn:10020
mapreduce.jobhistory.webapp.address
node1.cn:19888
8、编辑文件 yarn-site.xml
[root@node1 ~]# vim /opt/cluster/hadoop-3.2.0/etc/hadoop/yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
cluster-yarn
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
node1.cn
yarn.resourcemanager.hostname.rm2
node2.cn
yarn.resourcemanager.webapp.address.rm1
node1.cn:8088
yarn.resourcemanager.webapp.address.rm2
node2.cn:8088
yarn.resourcemanager.zk-address
node3.cn:2181,node4.cn:2181,node5.cn:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
106800
9、配置文件 workers
[root@node1 ~]# vim /opt/cluster/hadoop-3.2.0/etc/hadoop/workersnode3.cn
node4.cn
node5.cn10、把整个 hadoop-3.2.0 目录分发给各个节点
[root@node1 ~]# scp -r /opt/cluster/hadoop-3.2.0 node2.cn:/opt/cluster/
[root@node1 ~]# scp -r /opt/cluster/hadoop-3.2.0 node3.cn:/opt/cluster/
[root@node1 ~]# scp -r /opt/cluster/hadoop-3.2.0 node4.cn:/opt/cluster/
[root@node1 ~]# scp -r /opt/cluster/hadoop-3.2.0 node5.cn:/opt/cluster/11、配置、启动 zookeeper
参考
https://hunter.blog.csdn.net/article/details/96651537
https://hunter.blog.csdn.net/article/details/85937442
12、指定的三个节点启动 journalnode
(此处我选择了node3.cn、node4.cn、node5.cn作为journalnode)
[root@node3 ~]# hdfs --daemon start journalnode
[root@node4 ~]# hdfs --daemon start journalnode
[root@node5 ~]# hdfs --daemon start journalnode13、在 node1.cn 上格式化 namenode
[root@node1 ~]# hdfs namenode -format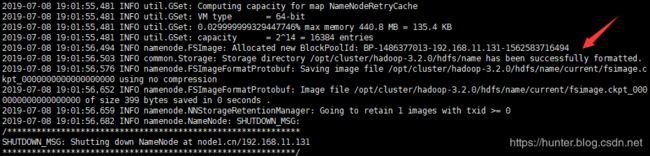
14、在 node1.cn 上启动 namenode
[root@node1 ~]# hdfs --daemon start namenode15、在 node2.cn 上同步 node1.cn 上已经格式化成功的 namenode信息
[root@node2 ~]# hdfs namenode -bootstrapStandby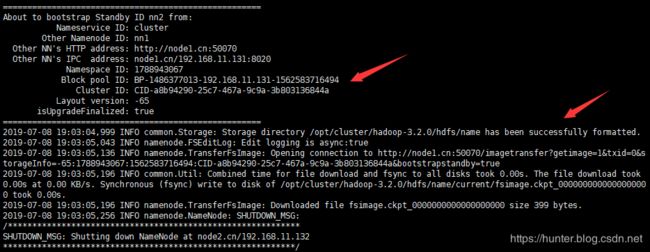
16、在 node2.cn 上启动 namenode
[root@node2 ~]# hdfs --daemon start namenode查看
![]()
17、关闭服务
(1)关闭 node1.cn 和 node2.cn 上的 namenode
[root@node1 ~]# hdfs --daemon stop namenode
[root@node2 ~]# hdfs --daemon stop namenode(2)关闭 node3.cn、node4.cn、node5.cn 上的 JournalNode
[root@node3 ~]# hdfs --daemon stop journalnode
[root@node4 ~]# hdfs --daemon stop journalnode
[root@node5 ~]# hdfs --daemon stop journalnode18、格式化 ZKFC
首先启动 node3.cn、node4.cn、node5.cn 上的 zookeeper
参考 https://blog.csdn.net/llwy1428/article/details/85937442
启动 zookeeper 后,在 node1.cn 节点上执行:
[root@node1 ~]# hdfs zkfc -formatZK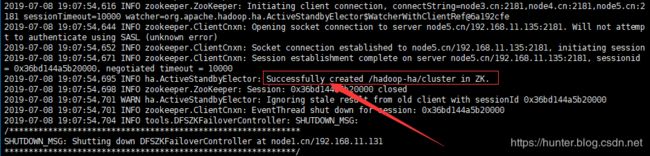
19、启动 hdfs、yarn 服务
[root@node1 ~]# /opt/cluster/hadoop-3.2.0/sbin/start-dfs.sh
[root@node1 ~]# /opt/cluster/hadoop-3.2.0/sbin/start-yarn.sh
20、查看各个节点的服务启动情况
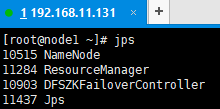
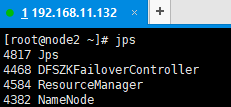
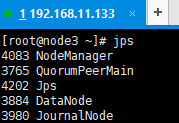
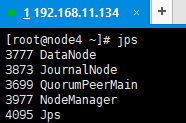

至此,Centos7.4 搭建 Hadoop (HA)集群,操作完毕。
五、基本 shell 操作
(1)在 hdfs 中创建目录
[root@node1 ~]# hdfs dfs -mkdir /hadoop
[root@node1 ~]# hdfs dfs -mkdir /hdfs
[root@node1 ~]# hdfs dfs -mkdir /tmp(2)查看目录
[root@node2 ~]# hdfs dfs -ls /
(3)上传文件
例如:在 /opt 目录下创建一个文件 test.txt 并写入一些单词(过程略)
[root@node3 ~]# hdfs dfs -put /opt/test.txt /hadoop查看已上传的文件
[root@node4 ~]# hdfs dfs -ls /hadoop
[root@node4 ~]# hdfs dfs -cat /hadoop/test.txt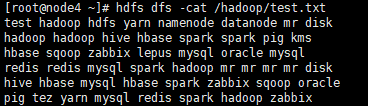
(4)删除文件
[root@node5 ~]# hdfs dfs -rm /hadoop/test.txt
Deleted /hadoop/test.txt六、浏览器查看 部分服务的 UI 页面
1、查看 hdfs 的信息
分别查看node1.cn的ip和node2.cn的ip
http://node1.cn的ip:50070
http://node2.cn的ip:50070
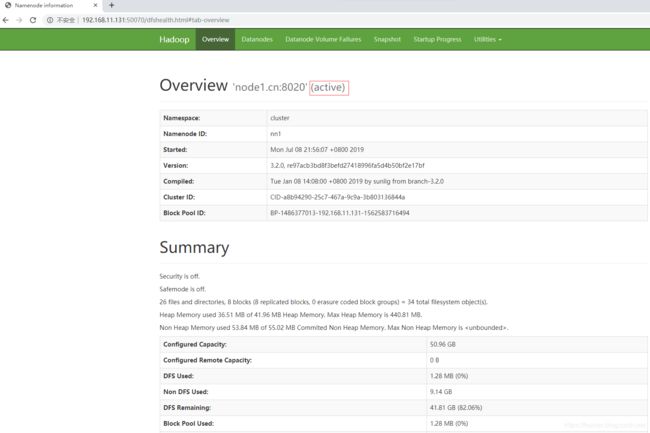

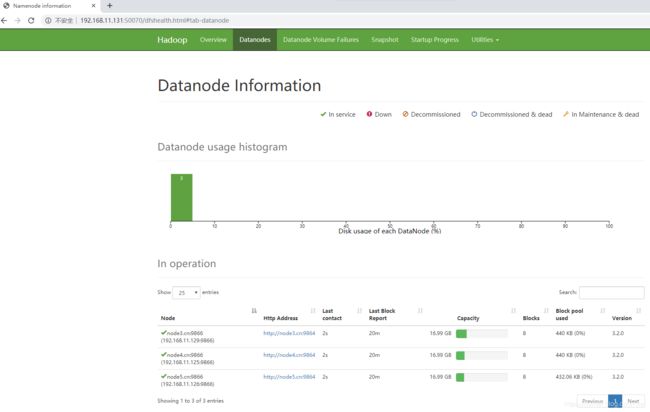
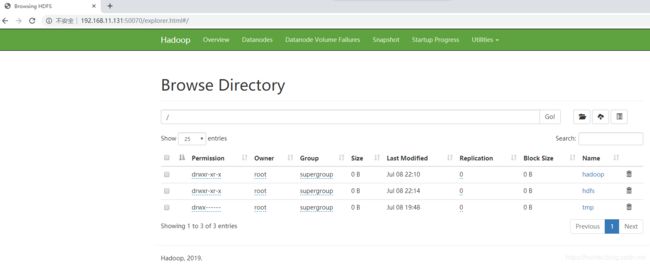
其他页面:略。
2、查看 ResourceManager 信息
输入
http://node1.cn的ip:8088
或
http://node2.cn的ip:8088
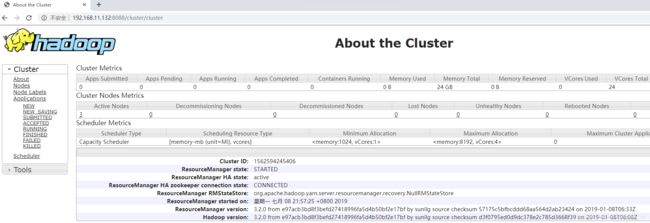

其他页面:略。
七、运行 mapreduce wordcount
以上文的 test.txt 为例
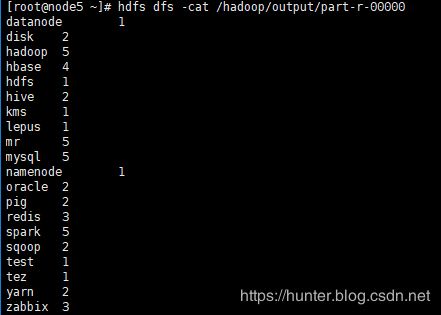
[root@node5 ~]# /opt/cluster/hadoop-3.2.0/bin/yarn jar /opt/cluster/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /hadoop /hadoop/output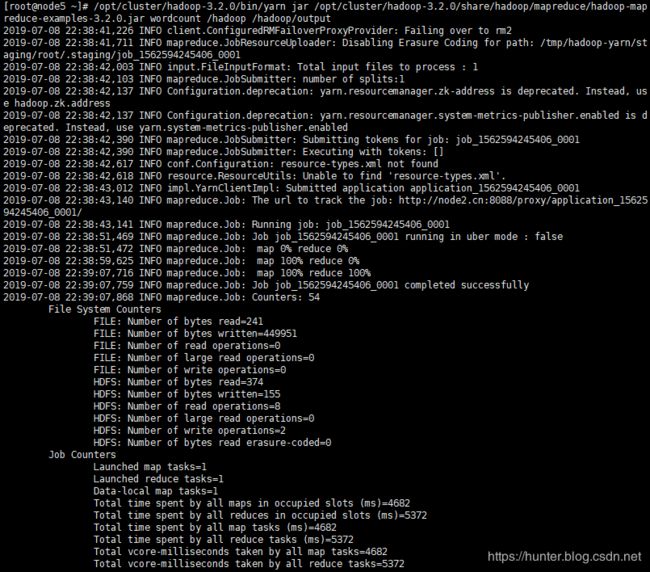
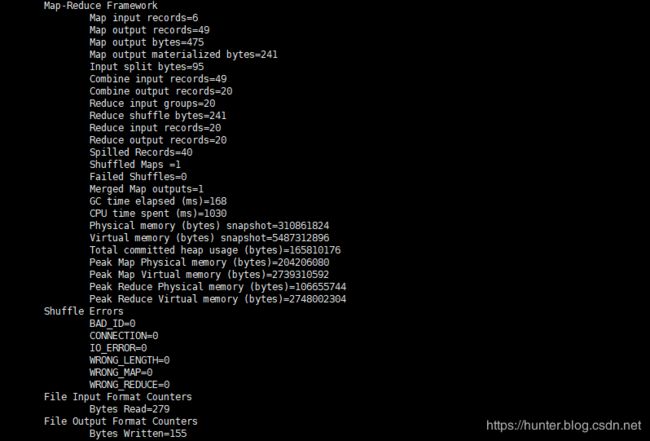
在浏览器查看执行结果

ResourceManager 中执行的结果

查看执行结果
[root@node5 ~]# hdfs dfs -cat /hadoop/output/part-r-00000