【机器学习笔记】通俗易懂解释高斯混合聚类原理
0前言
最近在看周志华《机器学习》中聚类这一章。其它聚类方法都比较容易看懂,唯有高斯混合聚类这种方法看上去比较复杂,有点难理解。但是,当将它的原理和过程看懂之后,其实这节书所讲的内容并不复杂,只是将高斯分布、贝叶斯公式、极大似然法和聚类的思路混合在这一种方法中,所以理解起来有点绕。
下文致力于用最最最通俗易懂的方法来说清楚高斯混合聚类做了什么、能做什么和为什么可以这么做。
文章目录
- 0前言
- 1高斯分布
- 2贝叶斯公式
- 2.1数理统计概率三个公式
- 2.1.1概率乘法公式
- 2.1.2全概率公式
- 2.1.3贝叶斯公式
- 2.2假如概率是连续的
- 2.3高斯混合分布
- 3极大似然法
- 4聚类
1高斯分布
首先是高斯分布的概念。高斯分布即正态分布。一般我们最常见最熟知的一元正态分布的标准形式和曲线是这样的:
f ( x ) = 1 2 π σ e x p ( − ( x − μ ) 2 2 σ 2 ) f(x)=\frac{1}{\sqrt{2 \pi}\sigma } exp(-\frac{(x-\mu)^2}{2\sigma ^2}) f(x)=2πσ1exp(−2σ2(x−μ)2)
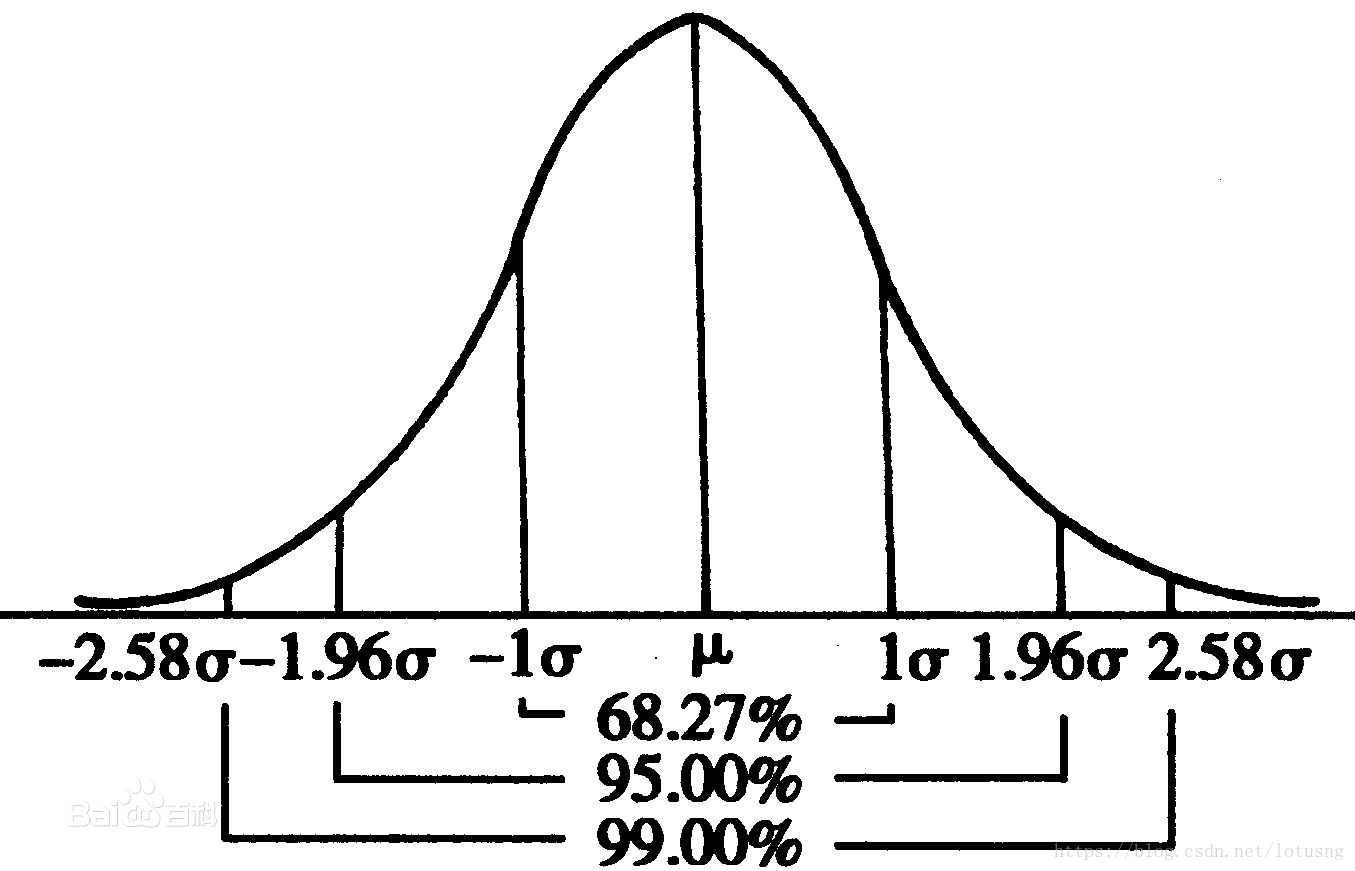
正态分布可以记为 N ( μ , σ 2 ) N(μ,σ^2) N(μ,σ2)。从上面的公式很明显可以看出一元正态分布只有两个参数 μ μ μ和 σ σ σ,且这两个参数决定了正态曲线的“宽窄”、“高矮”。 曲线下面积为1。
举一个附合正态分布的例子:人群中的身高。从一个很大的人群中随机抽取一个人的身高,这个概率是服从正态分布的。因样本可近似看成无穷大,可看成是有放回的随机抽取。人群中绝大多数人的身高都在平均值附近,越靠近平均值的人越多,极高和极矮的人只占人群极少数。
那么,二元及以上(多元)多元高斯的标准形式:
p ( x ) = ∏ i = 1 n 1 2 π e x p ( − 1 2 x i 2 ) = 1 2 π n 2 e x p ( − 1 2 x T I x ) p(x)=\prod_{i=1}^{n}\frac{1}{2\pi }exp(-\frac{1}{2}x_i^2)=\frac{1}{{2\pi}^\frac{n}{2}}exp(-\frac{1}{2}x^TIx) p(x)=∏i=1n2π1exp(−21xi2)=2π2n1exp(−21xTIx)
一般的多元高斯具有形式:
p ( x ) = 1 2 π n 2 ∣ Σ ∣ n 2 e x p ( − 1 2 x T Σ − 1 x ) p(x)=\frac{1}{{2\pi}^\frac{n}{2} \left |\Sigma \right |^\frac{n}{2} }exp(-\frac{1}{2}x^T\Sigma ^{-1} x) p(x)=2π2n∣Σ∣2n1exp(−21xTΣ−1x)
从公式可看到多元正态分布只有两个参数 μ μ μ和 Σ \Sigma Σ。上面的一元正态公式其实就是当 n = 1 n=1 n=1的时候的特殊化。
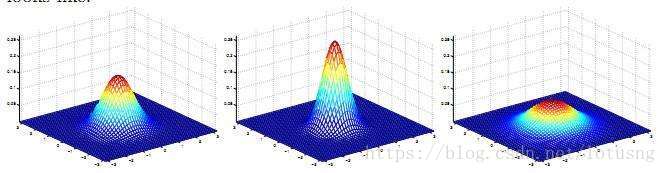
二元高斯曲线如下图。曲线下面积为1。它多了一个变量。例如x轴是身高,y轴是体重,有了身高体重的数据就可以在z轴找到该身高体重在人群中所占的比例。同样地,中等身高且中等体重的人在人群中是最常见的,正如路上普普通通的路人。
2贝叶斯公式
2.1数理统计概率三个公式
首先复习一下数理统计中概率公式的概念。
假设,有三个箱子X、Y、Z,箱子里有红黄蓝色的球若干。
事 件 A : 把 手 伸 向 一 个 箱 子 准 备 抽 取 球 。 事件A:把手伸向一个箱子准备抽取球。 事件A:把手伸向一个箱子准备抽取球。
事 件 B : 从 某 个 箱 子 里 抽 出 一 个 球 。 事件B:从某个箱子里抽出一个球。 事件B:从某个箱子里抽出一个球。
事件A、B中各个情况发生的概率是不等的。例如:
P ( A 1 ) = P ( A = X 箱 ) = 0.2 P(A_1)=P(A=X箱)=0.2 P(A1)=P(A=X箱)=0.2, P ( A 2 ) = P ( A = Y 箱 ) = 0.5 P(A_2)=P(A=Y箱)=0.5 P(A2)=P(A=Y箱)=0.5, P ( A 3 ) = P ( A = Z 箱 ) = 0.3 P(A_3)=P(A=Z箱)=0.3 P(A3)=P(A=Z箱)=0.3。
在第Y箱里 P ( B 1 ) = P ( B = Y 箱 红 球 ) = 0.2 P(B_1)=P(B=Y箱红球)=0.2 P(B1)=P(B=Y箱红球)=0.2, P ( B 2 ) = P ( B = Y 箱 黄 球 ) = 0.7 P(B_2)=P(B=Y箱黄球)=0.7 P(B2)=P(B=Y箱黄球)=0.7, P ( B 3 ) = P ( B = Y 箱 蓝 球 ) = 0.1 P(B_3)=P(B=Y箱蓝球)=0.1 P(B3)=P(B=Y箱蓝球)=0.1。
2.1.1概率乘法公式
概率乘法公式: P ( A B ) = P ( A ) P ( B ∣ A ) P(AB)=P(A)P(B|A) P(AB)=P(A)P(B∣A)
-
Question1:随机抽一个球,从 Y Y Y箱抽到黄球的概率是多少?
-
Answer:很明显,乘法公式告诉我们,先随机决定手伸向 Y Y Y箱(即事件 A 2 A_2 A2)的概率是0.5,在已经决定在 Y Y Y箱抽的前提下然后抽到黄球(即事件 P ( B ∣ A ) P(B|A) P(B∣A)的概率是0.7。它们相乘就是所求。
2.1.2全概率公式
全概率公式: P ( B ) = P ( A 1 ) P ( B ∣ A 1 ) + P ( A 2 ) P ( B ∣ A 2 ) + … + P ( A n ) P ( B ∣ A n ) P(B)=P(A_1)P(B|A_1)+ P(A_2)P(B|A_2)+…+ P(A_n)P(B|A_n) P(B)=P(A1)P(B∣A1)+P(A2)P(B∣A2)+…+P(An)P(B∣An)
-
Question2:随机抽一个球,抽到黄球的概率是多少?
-
Answer:在Question1的解答思路上,将 X X X箱抽到黄球概率+ Y Y Y箱抽到黄球概率+ Z Z Z箱抽到黄球概率即是所求。
2.1.3贝叶斯公式
贝叶斯公式: P ( A i ∣ B ) = P ( A i ) P ( B ∣ A i ) ∑ j = 1 n P ( A j ) P ( B ∣ A j ) P(A_i|B)=\frac{P(A_i)P(B|A_i)}{\sum_{j=1}^{n}P(A_j)P(B| A_j)} P(Ai∣B)=∑j=1nP(Aj)P(B∣Aj)P(Ai)P(B∣Ai)
-
Question3:现在随机抽一个球,已知结果是抽到黄球,求这个黄球是从 Y Y Y箱的概率是多少?
-
Answer:即求 P ( A 2 ∣ B ) P(A_2|B) P(A2∣B)。贝叶斯公式实际上分子就是乘法公式,求的是从 Y Y Y箱抽到黄球概率。分母实际上就是全概率公式,求的是从三个箱抽到黄球概率之和。分子分母相除,正是所求。
再回到乘法公式来看, P ( A B ) = P ( A ) P ( B ∣ A ) = P ( B ) P ( A ∣ B ) P(AB)=P(A)P(B|A)= P(B)P(A|B) P(AB)=P(A)P(B∣A)=P(B)P(A∣B)。后面的表达式用箱子抽球实例来理解:随机抽一个球,先随机决定抽黄球,再决定从哪个箱子抽。
其实贝叶斯公式只是乘法公式转换一下而已。贝斯叶公式也可以写成 P ( A ∣ B ) = P ( A B ) / P ( B ) P(A|B) = P(AB)/P(B) P(A∣B)=P(AB)/P(B)。
2.2假如概率是连续的
在Y箱中球的颜色概率分布图如下。颜色只有三个,概率是三个常数,这是一个散点图。
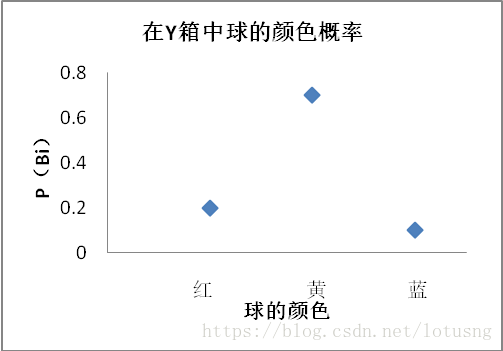
那假如,箱里的球的标签是数字,并且是连续的呢?比如从箱子里抽,可以任意抽到1~20的数字,包括这个区间内的任何整数或小数例如2、4.52、8.1等。那么,这个概率分布图可能是一条连续的直线。再假如,它是一条曲线,甚至它不是在平面上的,是三维立体的曲线呢?比如文章开头所说的多元高斯曲线。


现在问题就稍微变得复杂了一点点了。我们的事件A依然是3个箱子,概率是离散的。事件B变成了连续的曲线(三维的曲线、甚至更多维)。
2.3高斯混合分布
周志华《机器学习》9.4.3节给出一个把30个西瓜聚类的例子,我们只有西瓜的两个特征向量:密度和含糖率。目标是用高斯混合聚类把这堆西瓜分为3簇(即设定k=3)。
现在用西瓜例子来理解一下贝叶斯公式。在自然界无数的西瓜里,假设可分为三类瓜:坏瓜、一般瓜和好瓜。可能一般瓜是占大多数的,坏瓜和好瓜分别只占一小部分。并且各类瓜均符合高斯分布,即坏瓜、一般瓜、好瓜分别有自己的一个二元高斯分布曲线,那么它们可能是这样的三条曲线:
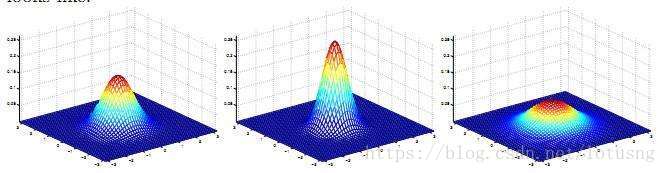
事 件 A : 随 机 从 坏 瓜 、 一 般 瓜 和 好 瓜 三 类 中 选 一 类 事件A:随机从坏瓜、一般瓜和好瓜三类中选一类 事件A:随机从坏瓜、一般瓜和好瓜三类中选一类。( P ( A i ) P(A_i) P(Ai)是三个常数, i i i=3)
事 件 B : 随 机 在 一 类 瓜 中 选 一 个 含 量 糖 为 某 值 、 密 度 为 某 值 的 瓜 。 事件B:随机在一类瓜中选一个含量糖为某值、密度为某值的瓜。 事件B:随机在一类瓜中选一个含量糖为某值、密度为某值的瓜。( P ( B j ) P(B_j) P(Bj) 是二维高斯曲线, j j j=3)
再花一点点时间回忆并理解一下刚刚三个概率公式。
-
乘法公式告诉我们,在自然界中随机选择一个瓜(事件 A B AB AB), P ( A B ) = P ( A ) P ( B ∣ A ) = P ( B ) P ( A ∣ B ) P(AB) = P(A)P(B|A) = P(B)P(A|B) P(AB)=P(A)P(B∣A)=P(B)P(A∣B),操作是选一个类再在这个类里选一个瓜。或者先随机决定要选的瓜的含糖量和密度数值,再随机决定要去哪类瓜里找。
-
全概率公式,我事先写下我想要的dream瓜的含糖量和密度数值( 事 件 B 事件B 事件B),随机选一个瓜,选中瓜的刚好是我的dream瓜的概率: P ( B ) = P ( A 1 ) P ( B ∣ A 1 ) + P ( A 2 ) P ( B ∣ A 2 ) + … + P ( A n ) P ( B ∣ A n ) P(B) = P(A_1)P(B|A_1) + P(A_2)P(B|A_2) + … + P(A_n)P(B|A_n) P(B)=P(A1)P(B∣A1)+P(A2)P(B∣A2)+…+P(An)P(B∣An)。将这个数值已确定的瓜是来自坏瓜、一般瓜、好瓜的概率分别相加。
-
贝叶斯公式: P ( A i ∣ B ) = P ( A i ) P ( B ∣ A i ) ∑ j = 1 n P ( B j ) P ( A ∣ B j ) P(A_i|B)=\frac{P(A_i)P(B|A_i)}{\sum_{j=1}^{n}P(B_j)P(A|B_j)} P(Ai∣B)=∑j=1nP(Bj)P(A∣Bj)P(Ai)P(B∣Ai)。随机抽个瓜,假如我抽到了一个含量糖为某值、密度为某值的瓜,这个瓜是来自第 i i i类瓜的概率?在第 i i i类中抽到这个数值的瓜的概率除以从各类中抽到这个数值的瓜的概率之和。
在周志华《机器学习》中是这样定义高斯混合分布的:


显然混合系数即上文中的 P ( A ) P(A) P(A),上图中的公式 ( 9.29 ) (9.29) (9.29)其实就是全概率公式。我们已知样本集30个瓜的含量糖、密度的值。先重点研究其中一个编号为 x x x的样本瓜 x x x, P m ( x ) Pm(x) Pm(x)是指我们在自然界中随机选一个瓜,选中恰好的是这个样本瓜 x x x的概率。
公式 ( 9.29 ) (9.29) (9.29)的说明:
- 首先,当 i i i=1,比如这里是指坏瓜类,那么这时坏瓜的高斯曲线已知已确定了(即 μ 1 、 Σ 1 \mu_1、\Sigma_1 μ1、Σ1已确定)。根据这个确定高斯曲线可以得到样本瓜 x x x在坏瓜类中存在的概率 p ( x ∣ μ 1 ) p(x|\mu_1) p(x∣μ1)。
- 然后, p ( x ∣ μ i ) p(x|\mu_i) p(x∣μi) 与 α i \alpha_i αi相乘的结果就是从坏瓜类中抽中样本瓜 x x x的概率。
- 最后,分别计算 i i i=1(从坏瓜类中抽)、 i i i=2(从一般瓜类中抽)和 i i i=3(从好瓜类中抽)的情况下抽到样本瓜 x x x的概率,将这三种情况下的概率相加,得到的 P m ( x ) Pm(x) Pm(x)即是在自然界中抽一个瓜正好抽中样本瓜 x x x的概率。
由于每类瓜分别拥有3个参数 α \alpha α、 μ \mu μ、 Σ \Sigma Σ,因为类 i i i=3,即这个例子里一共有9有参数。
3极大似然法
极大似然法比较有趣,它是在讲一件事会发生,我们已经看到了发生了这事件这个结果,那么我们就假设这件事可能是冥冥之中会发生的概率本来就很大。
比如,根据我们已知的条件,已知 a 、 μ 、 Σ a、\mu、\Sigma a、μ、Σ。一般瓜占三类瓜最大比例,每类中含糖量和密度整体又服从高斯分布。如果在自然界中随机抽一个瓜,那我们可以猜这个瓜是来自一般瓜类并且含糖量和密度在平均值附近的可能性最大(乘法公式)。
反过来想,假如已知 μ 、 Σ \mu、\Sigma μ、Σ,现在我们已经拿到了一个瓜,已知这个瓜的含糖量和密度数值,但不知道这个瓜来自哪个类,怎么办?我们可以将这个瓜的含糖量和密度数值分别代入3类瓜的高斯分布曲线,在哪类瓜中的概率高,即说明这个瓜来自哪类瓜的可能性最大。(下图公式是贝叶斯)

现在再换一个角度想,假如已知的是30个瓜的含糖量和密度数值,现在要求 α \alpha α、 μ \mu μ、 Σ \Sigma Σ,即猜出自然界已有但我们不知道的西瓜规律,怎么办?
因为我们相信这30个瓜是冥冥之中的天选之瓜,并且随机选的第1个瓜和第2个瓜是独立事件。先假设自然界中 α \alpha α、 μ \mu μ、 Σ \Sigma Σ是存在的,那么,算出这30个瓜的 P m ( x ) Pm(x) Pm(x),然后将30个 P m ( x ) Pm(x) Pm(x)相乘,得到的结果值 ∏ P m ( x ) \prod Pm(x) ∏Pm(x)理论上应该是最大的。
所以,假如我们在 α \alpha α、 μ \mu μ、 Σ \Sigma Σ为某值时算出了最大的结果值 ∏ P m ( x ) \prod Pm(x) ∏Pm(x),此时我们猜的西瓜规律很有可能是对的,这些天选之瓜才会随机地恰好地被我们选中,出现在我们面前。这就是我们这样设置求解限制条件和算法流程中迭代的停止条件的原因。
上述就是极大似然法做的事情。我们在已有的结果面前推测我们未知但存在的规律。至于具体的解法,因为是求30个 P m ( x ) Pm(x) Pm(x)的乘积的最大值,先将这个式子取对数,就可以将多个数的乘法转化成加法了。接下来的变换、化简、求解就可以交给高数和计算机来解决啦。

求出 α \alpha α、 μ \mu μ、 Σ \Sigma Σ之后,相当于我们已经掌握了自然界分类瓜的神秘规律,那么这时按照这个规律来给瓜分类并贴上分类标签,就是很简单的事情了。把某个瓜代进3条我们求出来的高斯曲线,选出所在最大概率的曲线,就说明这个瓜来自这个类的可能性最大。这就是高斯混合聚类算法的最后一步:根据已知参数来分类。
4聚类
高斯混合聚类的步骤:首先假设样本集具有一些规律,包括可以以 α \alpha α参数作为比例分为 k k k类且每类内符合高斯分布。然后根据贝叶斯原理利用极大似然法同时求出决定分类比例的 α \alpha α和决定类内高斯分布的 μ \mu μ、 Σ \Sigma Σ。最后将样本根据 α \alpha α、 μ \mu μ、 Σ \Sigma Σ再次通过贝叶斯原理求出样本该分在哪个簇。
整个步骤下来,这种做法其实就是一种原型聚类:通过找到可以刻画样本的原型( α \alpha α、 μ \mu μ、 Σ \Sigma Σ参数),迭代得到 α \alpha α、 μ \mu μ、 Σ \Sigma Σ参数的最优解。
将逻辑思路理清楚之后,高斯混合聚类并不复杂,只是因为它同时运用了高斯分布、贝叶斯公式、极大似然法和聚类的原理和思想,加上高数化简求解的步骤,而导致初读时比较容易感到有些混乱。
p.s. 第一次写博文,反反复复修改,还是感觉自己把简单的事情讲复杂了却还没有讲清楚……欢迎大家留言交流呀~