OpenCV人脸识别实验(一)——特征脸(Eigenfaces)及其重构的源代码详解
1、介绍Introduction
从OpenCV2.4开始,加入了新的类FaceRecognizer,我们可以使用它便捷地进行人脸识别实验。
本实验采用的编程环境为:opencv3.0+VS2013。人脸识别的实验已经转移到face模块中,
face模块在我这里的路径为:D:\Program Files\opencv3.0\opencv\sources\modules\opencv_contrib-master\modules\face。
代码在OpenCV安装目录下为:D:\Program Files\opencv3.0\opencv\sources\modules\opencv_contrib-master\modules\face\samples\facerec_eigenfaces.cpp.
如果需要在高版本的opencv中使用face模块,需要自己进行编译,其编译和配置流程请参照题目为:
【图像处理】windows 10 + vs2015+ opencv3.0.0 +附加模块opencv_contrib编译和配置的博客,在此不在赘述。
face模块目前支持的算法有:
(1)主成分分析(PCA)——Eigenfaces(特征脸)——函数:createEigenFaceRecognizer()
PCA:低维子空间是使用主元分析找到的,找具有最大方差的哪个轴。
缺点:若变化基于外部(光照),最大方差轴不一定包括鉴别信息,不能实行分类。
(2)线性判别分析(LDA)——Fisherfaces(特征脸)——函数: createFisherFaceRecognizer()
LDA:线性鉴别的特定类投影方法,目标:实现类内方差最小,类间方差最大。
(3)局部二值模式(LBP)——LocalBinary Patterns Histograms——函数:createLBPHFaceRecognizer()
PCA和LDA采用整体方法进行人脸辨别,LBP采用局部特征提取,除此之外,还有的局部特征提取方法为:
盖伯小波(Gabor Waelets)和离散傅里叶变换(DCT)。
2、人脸库及数据准备
在研究人脸识别,所以我们需要人脸图像!你可以自己创建自己的数据集,也可以从这里(http://face-rec.org/databases/)下载一个。本实验采用ORL人脸数据库,40个人,每人10张照片。本次实验ORL人脸库图像解压缩在的目录路径为:D:\Program Files\opencv3.0\opencv\sources\data\FaceData\ORL。CSV文件的目录路径为:
D:\Program Files\opencv3.0\opencv\sources\data\at.txt。我们需要在程序中读取它,我决定使用CSV文件读取它。一个CSV文件包含文件名,紧跟一个标签。
如:D:\Program Files\opencv3.0\opencv\sources\data\FaceData\ORL\s1\1.pgm;0
我们给它一个标签0,这个标签类似代表这个人的名字,所以同一个人的照片的标签都一样。创建一个CSV文件,
at.txt文件的部分内容的截图如下:

3、算法描述
图像表示的问题是他的高维问题。二维灰度图像p*q大小,是一个m=qp维的向量空间,
所以一个100*100像素大小的图像就是10,000维的图像空间。问题是,是不是所有的维数空间对我们来说都有用?
我们可以做一个决定,如果数据有任何差异,我们可以通过寻找主元来知道主要信息。
主成分分析(PrincipalComponent Analysis,PCA)是KarlPearson (1901)独立发表的,
而 Harold Hotelling (1933)把一些可能相关的变量转换成一个更小的不相关的子集。
想法是,一个高维数据集经常被相关变量表示,因此只有一些的维上数据才是有意义的,包含最多的信息。
PCA方法寻找数据中拥有最大方差的方向,被称为主成分。
令 ![]() 表示一个随机特征,其中
表示一个随机特征,其中 ![]() .
.
1. 计算均值向量 ![]()

2. 计算协方差矩阵 S
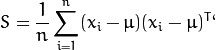
3. 计算 的特征值 ![]() 和对应的特征向量
和对应的特征向量 ![]()
![]()
4. 对特征值进行递减排序,特征向量和它顺序一致. K个主成分也就是k个最大的特征值对应的特征向量。
x的K个主成份:
![]()
其中 ![]() .
.
PCA基的重构:
![]()
其中 ![]() .
.
然后特征脸通过下面的方式进行人脸识别:
A. 把所有的训练数据投影到PCA子空间
B. 把待识别图像投影到PCA子空间
C. 找到训练数据投影后的向量和待识别图像投影后的向量最近的那个。4、代码实现及实验结果
#include
#include
#include
#include
#include
#include //文件操作的集合,以流的方式进行
#include //此库定义了stringstream类,即:流的输入输出操作。
//使用string对象代替字符数组,避免缓冲区溢出的危险
using namespace cv;
using namespace std;
using namespace cv::face;
//归一化图像矩阵函数
static Mat norm_0_255(InputArray _src)
{
Mat src = _src.getMat(); //将传入的类型为InputArray的参数转换为Mat的结构
Mat dst; //创建和返回一个归一化后的图像
switch (src.channels())
{
case 1:
normalize(_src, dst, 0, 255, NORM_MINMAX, CV_8UC1);
break;
case 3:
normalize(_src, dst, 0, 255, NORM_MINMAX, CV_8UC3);
break;
default:
src.copyTo(dst);
break;
}
return dst;
}
//使用CSV文件读取图像和标签,主要使用stringstream和getline方法
static void read_csv(const string& filename, vector& images, vector& labels, char separator = ';')
{
ifstream file(filename.c_str(), ifstream::in); //以输入方式打开文件
//c_str()函数将字符串转化为字符数组,返回指针
if (!file)
{
string error_massage = "No valid input file was given,please check the given filename!";
CV_Error(CV_StsBadArg, error_massage);
}
string line, path, classlabel;
while (getline(file, line)) //getline(字符数组,字符个数n,终止标志字符)
{
stringstream liness(line);
getline(liness, path, separator); //遇到分号就结束
getline(liness, classlabel); //继续从分号后边开始,遇到换行结束
if (!path.empty() && !classlabel.empty())
{
images.push_back(imread(path, 0));
labels.push_back(atoi(classlabel.c_str())); //atoi函数将字符串转换为整数值
}
}
}
int main(int argc, const char* argv[])
{
//[1] 检测合法的命令,显示用法
//如果没有参数输入,则退出
//if (argc < 2)
//{
// cout << "usage:" << argv[0] << " " << endl;
// exit(1);
//}
string output_folder;
output_folder = string("D:\\Program Files\\opencv3.0\\opencv\\sources\\data\\FaceData\\result6");
//[2] 读取CSV文件路径
string fn_csv = string("D:\\Program Files\\opencv3.0\\opencv\\sources\\data\\at.txt");
//两个容器来存放图像数据和对应的标签
vector images;
vector labels;
//读取数据,如果文件不合法就会出错。输入的文件名已经有了
try{
read_csv(fn_csv, images, labels);
}
catch (Exception& e)
{
cerr << "Error opening file" << fn_csv << ".Reason:" << e.msg << endl;
exit(1);
}
//没有读取到足够多的图片,也需要退出
if (images.size() <= 1)
{
string error_message = "This demo need at least 2 images,please add more images to your data set!";
CV_Error(CV_StsError, error_message);
}
//[3] 得到第一张图片的高度,在下面对图像变形得到他们原始大小时需要
int height = images[0].rows;
//[4]下面代码仅从数据集中移除最后一张图片,用于做测试,需要根据自己的需要进行修改
Mat testSample = images[images.size() - 1];
int testLabel = labels[labels.size() - 1];
images.pop_back(); //删除最后一张图片
labels.pop_back(); //删除最后一个标签
//[5] 创建一个特征脸模型用于人脸识别
//通过CSV文件读取的图像和标签训练它
//这里是一个完整的PCA 变换
//如果想保留10个主成分,使用如下代码 cv::createEigenFaceRecognizer(10);
//如果希望使用置信度阈值来初始化,使用代码 cv::createEigenFaceRecognizer(10, 123.0);
//如果使用所有特征并使用一个阈值,使用代码 cv::createEigenFaceRecognizer(0, 123.0);
Ptr model = createEigenFaceRecognizer();
model->train(images, labels);
//[6] 对测试图像进行预测,predictedLabel是预测标签结果
int predictedLabel = model->predict(testSample);
// 还有一种调用方式,可以获取结果同时得到阈值:
// int predictedLabel = -1;
// double confidence = 0.0;
// model->predict(testSample, predictedLabel, confidence);
string result_message = format("Predicted class = %d / Actual class = %d.", predictedLabel, testLabel);
cout << result_message << endl;
//[7] 如何获取特征脸模型的特征值例子,使用getEigenValues方法
Mat eigenvalues = model->getEigenValues();
//[8] 获取特征向量
Mat W = model->getEigenVectors();
//[9] 得到训练图像的均值向量
Mat mean = model->getMean();
//[10] 显示或保存
imshow("mean", norm_0_255(mean.reshape(1, images[0].rows)));
imwrite(format("%s/mean.png", output_folder.c_str()), norm_0_255(mean.reshape(1, images[0].rows)));
//[11] 显示或保存特征脸
for (int i = 0; i < min(10, W.cols); i++) //修改数值10可以修改特征脸的数目
{
string msg = format("Eigenvalue #%d = %.5f", i,eigenvalues.at(i));
cout << msg << endl;
//得到第i个特征向量
Mat ev = W.col(i).clone();
//把它变成原始大小,把数据显示归一化到0-255
Mat grayscale = norm_0_255(ev.reshape(1, height));
//使用伪彩色来显示结果,为了更好的观察
Mat cgrayscale;
applyColorMap(grayscale, cgrayscale, COLORMAP_JET);
//显示或保存
imshow(format("eigenface_%d", i), cgrayscale);
imwrite(format("%s/eigenface_%d.png", output_folder.c_str(), i),norm_0_255(cgrayscale));
}
//[12] 预测过程中,显示或保存重建后的图像
//修改值300可改变重构的图像的数目
for (int num_components = min(W.cols, 10); num_components < min(W.cols,300); num_components += 15)
{
//从模型中的特征向量截取一部分
Mat evs = Mat(W, Range::all(), Range(0, num_components));
//在重构时,images[0]为ORL人脸库的第一张人脸图,
//修改此数值0的大小可对其他人脸图像进行特征脸处理与重构的实验
Mat projection = LDA::subspaceProject(evs, mean, images[0].reshape(1, 1));
//投影样本到LDA子空间
Mat reconstruction = LDA::subspaceReconstruct(evs, mean,projection);
//重构来自于LDA子空间的投影
//归一化结果
reconstruction = norm_0_255(reconstruction.reshape(1, images[0].rows));
//[13] 若不是存放到文件夹中就显示他,使用暂定等待键盘输入
imshow(format("eigenface_reconstruction_%d", num_components),reconstruction);
imwrite(format("%s/eigenface_reconstruction_%d.png",output_folder.c_str(), num_components), reconstruction);
}
waitKey(0);
return 0;
} 



修改代码:
(1)for (int i = 0; i < min(50, W.cols); i++)//修改数值50可以修改特征脸的数目
(2)//修改重构图像的范围或数目,修改值为400
for (int num_components = min(W.cols, 10); num_components < min(W.cols,400); num_components += 15)
实验运行结果截图为:(特征值或特征脸数目为50,重构人脸图像为26)






再次修改代码:(代码中红色注解部分)
//修改此数值0的大小为其他值,可对其他人脸图像进行特征脸处理与重构的实验
Mat projection = LDA::subspaceProject(evs, mean, images[50].reshape(1, 1));
实验截图为:


5、实验结论
(1)50个特征向量可以有效的编码出重要的人脸特征。
(2)对比下面两幅图,重构图像的范围或数目越大,重构的效果越好,重构的图片越清晰!

