深度学习卷积神经网络——经典网络LeNet-5、AlexNet、ZFNet网络的搭建与实现
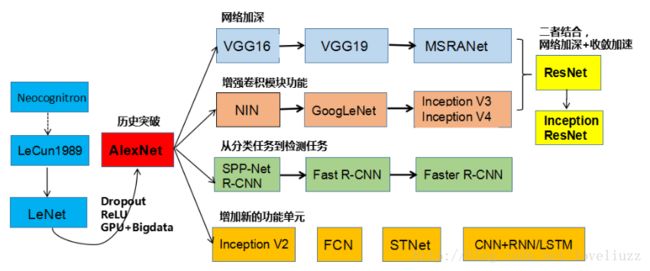
一、CNN卷积神经网络的经典网络综述

下面图片参照博客:http://blog.csdn.net/cyh_24/article/details/51440344
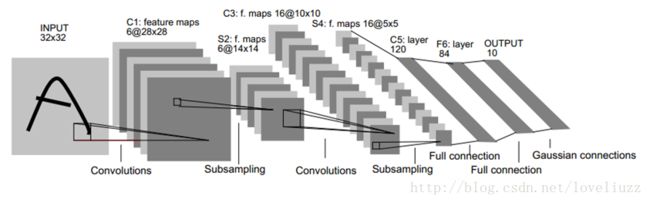
二、LeNet-5网络

- 输入尺寸:32*32
- 卷积层:2个
- 降采样层(池化层):2个
- 全连接层:2个
- 输出层:1个。10个类别(数字0-9的概率)
LeNet-5网络是针对灰度图进行训练的,输入图像大小为32*32*1,不包含输入层的情况下共有7层,每层都包含可训练参数(连接权重)。注:每个层有多个Feature Map,每个Feature Map通过一种卷积滤波器提取输入的一种特征,然后每个Feature Map有多个神经元。
1、C1层是一个卷积层(通过卷积运算,可以使原信号特征增强,并且降低噪音)
第一层使用5*5大小的过滤器6个,步长s = 1,padding = 0。即:由6个特征图Feature Map构成,特征图中每个神经元与输入中5*5的邻域相连,输出得到的特征图大小为28*28*6。C1有156个可训练参数(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器,共(5*5+1)*6=156个参数),共156*(28*28)=122,304个连接。
2、S2层是一个下采样层(平均池化层)(利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息,降低网络训练参数及模型的过拟合程度)。
第二层使用2*2大小的过滤器,步长s = 2,padding = 0。即:特征图中的每个单元与C1中相对应特征图的2*2邻域相连接,有6个14*14的特征图,输出得到的特征图大小为14*14*6。池化层只有一组超参数 f 和 s,没有需要学习的参数。
3、C3层是一个卷积层
第三层使用5*5大小的过滤器16个,步长s = 1,padding = 0。即:由16个特征图Feature Map构成,特征图中每个神经元与输入中5*5的邻域相连,输出得到的特征图大小为10*10*16。C3有416个可训练参数(每个滤波器5*5=25个unit参数和一个bias参数,一共16个滤波器,共(5*5+1)*16=416个参数)。
4、S4层是一个下采样层(平均池化层)
第四层使用2*2大小的过滤器,步长s = 2,padding = 0。即:特征图中的每个单元与C3中相对应特征图的2*2
邻域相连接,有16个5*5的特征图,输出得到的特征图大小为5*5*16。没有需要学习的参数。
5、F5层是一个全连接层
有120个单元。每个单元与S4层的全部400个单元之间进行全连接。F5层有120*(400+1)=48120个可训练参数。
如同经典神经网络,F5层计算输入向量和权重向量之间的点积,再加上一个偏置。
6、F6层是一个全连接层
有84个单元。每个单元与F5层的全部120个单元之间进行全连接。F6层有84*(120+1)=10164个可训练参数。
如同经典神经网络,F6层计算输入向量和权重向量之间的点积,再加上一个偏置。
7、Output输出层
输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。
换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。
用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。
给定一个输式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。
总结:
随着网络越来越深,图像的宽度和高度都在缩小,信道数量一直在增加。目前,一个或多个卷积层后边跟一个
池化层,再接上一个全连接层的排列方式很常用。

| 层(layer) | 激活后的维度(Activation Shape) | 激活后的大小(Activation Size) | 参数w、b(parameters) |
| Input | (32,32,1) | 1024 | 0 |
| CONV1(f=5,s=1) | (28,28,6) | 4704 | (5*5+1)*6=156 |
| POOL1 | (14,14,6) | 1176 | 0 |
| CONV2(f=5,s=1) | (10,10,16) | 1600 | (5*5*6+1)*16=2416 |
| POOL2 | (5,5,16) | 400 | 0 |
| FC3 | (120,1) | 120 | 120*(400+1)=48120 |
| FC4 | (84,1) | 84 | 84*(120+1)=10164 |
| Softmax | (10,1) | 10 | 10*(84+1)=850 |

三、AlexNet网络的框架介绍
AlexNet网络共有:卷积层 5个,池化层 3个,全连接层:3个(其中包含输出层)。
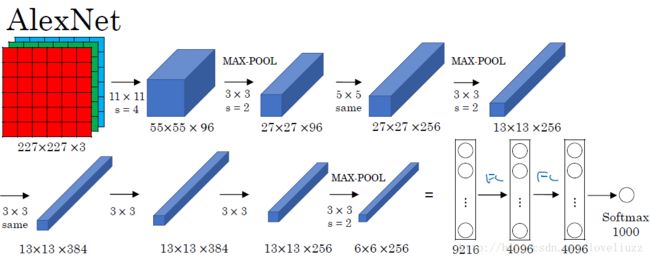

卷积神经网络的结构并不是各个层的简单组合,它是由一个个“模块”有机组成的,在模块内部,
各个层的排列是有讲究的。比如AlexNet的结构图,它是由八个模块组成的。
1、AlexNet——模块一和模块二
结构类型为:卷积-激活函数(ReLU)-降采样(池化)-标准化
这两个模块是CNN的前面部分,构成了一个计算模块,这个可以说是一个卷积过程的标配,从宏观的角度来看,
就是一层卷积,一层降采样这样循环的,中间适当地插入一些函数来控制数值的范围,以便后续的循环计算。
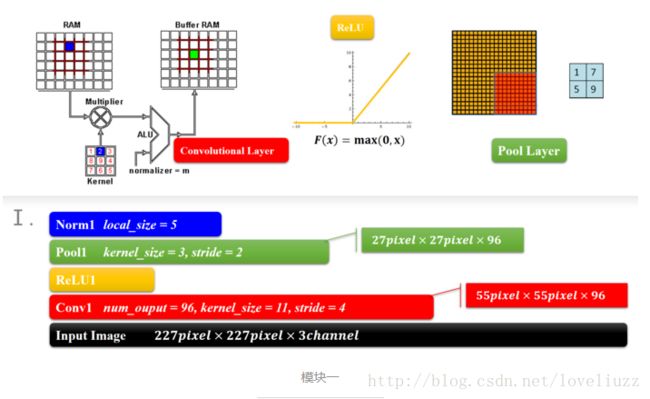
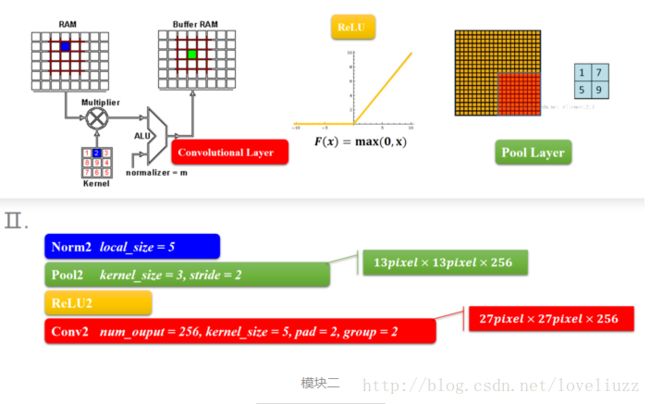
2、AlexNet——模块三和模块四
模块三和四也是两个same卷积过程,差别是少了降采样(池化层),原因就跟输入的尺寸有关,特征的数据量已经比较小了,
所以没有降采样。
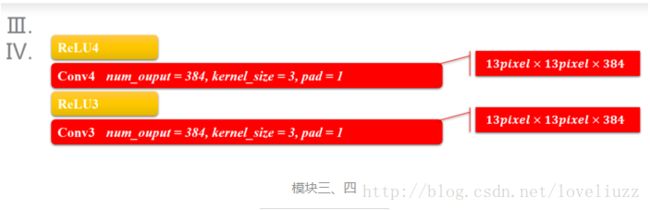
3、AlexNet——模块五
模块五也是一个卷积和池化过程,和模块一、二一样的。模块五输出的其实已经是6\6的小块儿了。
(一般设计可以到1\1的小块,由于ImageNet的图像大,所以6\6也正常的。)
原来输入的227\227像素的图像会变成6\*6这么小,主要原因是归功于降采样(池化层),
当然卷积层也会让图像变小,一层层的下去,图像越来越小。

4、模块六、七、八
模块六和七就是所谓的全连接层了,全连接层就和人工神经网络的结构一样的,结点数超级多,连接线也超多,
所以这儿引出了一个dropout层,来去除一部分没有足够激活的层。
模块八是一个输出的结果,结合上softmax做出分类。有几类,输出几个结点,每个结点保存的是属于该类别的概率值。

AlexNet总结:
- 输入尺寸:227*227*3
- 卷积层:5个
- 降采样层(池化层):3个
- 全连接层:2个
- 输出层:1个。1000个类别

(二)整体架构
1、AlexNet.py文件实现前向传播过程以及网络的参数。
2、train.py文件实现训练的过程。
3、eval.py文件实现测试的过程。
四、应用的基础知识点
1、tf.get_variable函数:获取变量。在训练神经网络时会创建这些变量,在测试时会通过保存的模型加载这些变量的值。而且更方便的是,可以在变量加载时将滑动平均变量重命名,所以可以直接通过同样的名字在训练时使用变量自身,而在测试时使用变量的滑动平均值。
2、name_scope与variable_scope的区别:
name_scope 是给op_name加前缀, variable_scope是给get_variable()创建的变量的名字加前缀。

![]()
详见链接:http://blog.csdn.net/u012436149/article/details/53081454

3、sparse_softmax_cross_entropy_with_logits与softmax_cross_entropy_with_logits区别
见链接:https://www.jianshu.com/p/75f7e60dae95
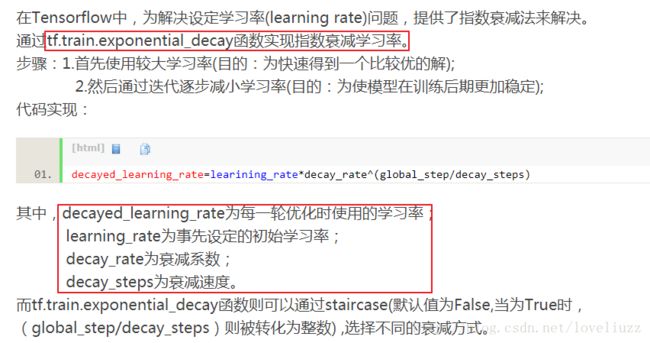
4、Tensorflow中tf.train.exponential_decay函数(指数衰减法)
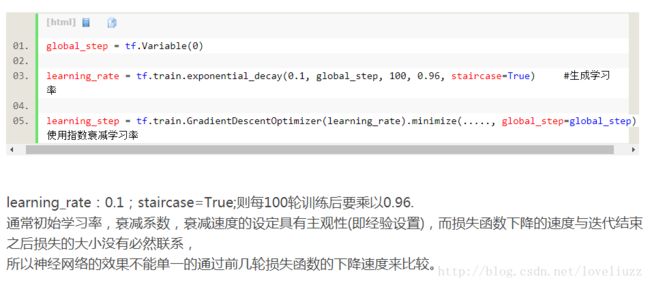
五、AlexNet.py文件实现前向传播过程以及网络的参数的代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
#用AlexNet实现电脑破译手语——SIGNG datasets
#训练集:1080张图片,每张图片大小为:64*64*3,表示数字0至5,每个数字的图片为180张
#测试集:120张图片,每张图片大小为:64*64*3,表示数字0至5,每个数字的图片为20张
#AlexNet网络框架实现前向传播过程及网络的参数
import tensorflow as tf
#显示网络每一层结构的函数,展示每一个卷积层或池化层输出Tensor的尺寸
def print_acrivations(t):
"""
显示每一层的名称(t.op.name)和tensor的尺寸(t.get_shape.as_list())
param :
t -- Tensor类型的输入
"""
print(t.op.name," ",t.get_shape.as_list())
#配置AlexNet网络的参数
NUM_CHANNELS = 3 #图片的通道数
#第一层卷积层的尺寸和深度(卷积核个数)
CONV1_SIZE = 11
CONV1_DEEP = 96
#第二层卷积层的尺寸和深度(卷积核个数)
CONV2_SIZE = 5
CONV2_DEEP = 256
#第三层卷积层的尺寸和深度(卷积核个数)
CONV3_SIZE = 3
CONV3_DEEP = 384
#第四层卷积层的尺寸和深度(卷积核个数)
CONV4_SIZE = 3
CONV4_DEEP = 256
#第五层卷积层的尺寸和深度(卷积核个数)
CONV5_SIZE = 3
CONV5_DEEP = 256
#第六、七层全连接层的尺寸
FC6_SIZE = 4096
FC7_SIZE = 4096
#输出层的尺寸(分类数目)
OUTPUT_NODE = 10
def AlexNet(input_tensor,train,regularizer):
"""
AlexNet网络框架实现前向传播过程
param :
input_tensor -- 输入的张量,一般为图片
train -- 用于区分训练和测试过程
regularizer -- 正则化
return:
out -- 输出最后一层
"""
# 第一个卷积层
with tf.variable_scope("conv1"):
# 第一个卷积层,用截断的正态分布函数tf.truncated_normal_initializer 初始化卷积核conv1_weights
# 卷积核大小为 11*11*3,个数为96个
conv1_weights = tf.get_variable(name="weight",shape=[CONV1_SIZE,CONV1_SIZE,NUM_CHANNELS,CONV1_DEEP],
dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1))
# 初始化偏向biases全部为0
conv1_biases = tf.get_variable(name="bias",shape=[CONV1_DEEP],
dtype=tf.float32,initializer=tf.constant_initializer(0.0))
# 卷积操作,步长s = 4,padding = "SAME"
conv1 = tf.nn.conv2d(input=input_tensor,filter=conv1_weights,strides=[1,4,4,1],padding="SAME")
# 将conv和baises加起来并进行relu激活
conv1 = tf.nn.relu(tf.nn.bias_add(conv1,conv1_biases))
# 打印conv1的结构
print_acrivations(conv1)
# 卷积层后添加LRN层(除AlexNet其他经典网络基本无LRN层,效果不明显且速度有所降低)
lrn1 = tf.nn.lrn(conv1, depth_radius=4, bias=1.0, alpha=0.001 / 9, beta=0.75, name="lrn1")
# 最大池化层(尺寸为 3*3,步长s=2*2)
pool1 = tf.nn.max_pool(lrn1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="VALID", name="pool1")
# 打印pool1的结构
print_acrivations(pool1)
#第二个卷积层,卷积核大小为(5,5,96,256)
with tf.variable_scope("conv2"):
conv2_weights = tf.get_variable(name="weight",shape=[CONV2_SIZE,CONV2_SIZE,CONV1_DEEP,CONV2_DEEP],
dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable(name="bias",shape=[CONV2_DEEP],
dtype=tf.float32,initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(input=pool1,filter=conv2_weights,strides=[[1,1,1,1]],padding="SAME")
conv2 = tf.nn.relu(tf.nn.bias_add(conv2,conv2_biases))
print_acrivations(conv2)
lrn2 = tf.nn.lrn(conv2, depth_radius=4, bias=1.0, alpha=0.001 / 9, beta=0.75, name="lrn2")
pool2 = tf.nn.max_pool(lrn2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="VALID", name="pool2")
print_acrivations(pool2)
# 第三个卷积层,卷积核大小为(3,3,256,384),无LRN与最大池化
with tf.variable_scope("conv3"):
conv3_weights = tf.get_variable(name="weight",shape=[CONV3_SIZE,CONV3_SIZE,CONV2_DEEP,CONV3_DEEP],
dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1))
conv3_biases = tf.get_variable(name="bias",shape=[CONV3_DEEP],
dtype=tf.float32,initializer=tf.constant_initializer(0.0))
conv3 = tf.nn.conv2d(input=pool2,filter=conv3_weights,strides=[1,1,1,1],padding="SAME")
conv3 = tf.nn.relu(tf.nn.bias_add(conv3,conv3_biases))
print_acrivations(conv3)
# 第四个卷积层,卷积核大小为(3,3,384,256),无LRN与最大池化
with tf.variable_scope("conv4"):
conv4_weights = tf.get_variable(name="weight",shape=[CONV4_SIZE,CONV4_SIZE,CONV3_DEEP,CONV4_DEEP],
dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1))
conv4_biases = tf.get_variable(name="bias",shape=[CONV4_DEEP],
dtype=tf.float32,initializer=tf.constant_initializer(0.0))
conv4 = tf.nn.conv2d(input=conv3,filter=conv4_weights,strides=[1,1,1,1],padding="SAME")
conv4 = tf.nn.relu(tf.nn.bias_add(conv4,conv4_biases))
print_acrivations(conv4)
# 第五个卷积层,卷积核大小为(3,3,256,256)
with tf.variable_scope("conv5"):
conv5_weights = tf.get_variable(name="weight",shape=[CONV5_SIZE,CONV5_SIZE,CONV4_DEEP,CONV5_DEEP],
dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1))
conv5_biases = tf.get_variable(name="bias",shape=[CONV5_DEEP],
dtype=tf.float32,initializer=tf.constant_initializer(0.0))
conv5 = tf.nn.conv2d(input=conv4,filter=conv5_weights,strides=[1,1,1,1],padding="SAME")
conv5 = tf.nn.relu(tf.nn.bias_add(conv5,conv5_biases))
print_acrivations(conv5)
pool5 = tf.nn.max_pool(conv5,ksize=[1,3,3,1],strides=[1,2,2,1],padding="VALID",name="pool5")
print_acrivations(pool5)
# 第六层 —— 全连接层及dropout
#将第五层输出转化为第六层全连接层输入为向量的格式,即:将矩阵拉成一个向量
#每层输入输出都为一个batch矩阵,得到的维度包含pool5_shape[0] = batch中数据的个数
pool5_shape = pool5.get_shape().as_list()
nodes = pool5_shape[1]*pool5_shape[2]*pool5_shape[3]
dense = tf.reshape(pool5,shape=[pool5_shape[0],nodes]) #向量化
with tf.variable_scope("fc6"):
fc6_weights = tf.get_variable(name="weight",shape=[nodes,FC6_SIZE],dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.1))
#当给出了正则化生成函数,将当前变量的正则化损失加入名字为losses的集合
#add_to_collection函数将一个张量加入一个集合,自定义的集合losses,不在tensorflow自动管理的集合列表中中
if regularizer != None:
tf.add_to_collection("losses",regularizer(fc6_weights))
fc6_biases = tf.get_variable(name="bias",shape=[FC6_SIZE],dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
fc6 = tf.nn.relu(tf.add(tf.matmul(dense,fc6_weights),fc6_biases))
#dropout只在训练时使用
if train:
fc6 = tf.nn.dropout(fc6,keep_prob=0.7)
# 第七层 —— 全连接层及dropout
with tf.variable_scope("fc7"):
fc7_weights = tf.get_variable(name="weight",shape=[FC6_SIZE,FC7_SIZE],dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection("losses",regularizer(fc7_weights))
fc7_biases = tf.get_variable(name="bias",shape=[FC7_SIZE],dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
fc7 = tf.nn.relu(tf.add(tf.matmul(fc6,fc7_weights),fc7_biases))
if train:
fc7 = tf.nn.dropout(fc7,keep_prob=0.7)
# 第八层 —— 全连接层/输出层
with tf.variable_scope("fc8"):
fc8_weights = tf.get_variable(name="weight",shape=[FC7_SIZE,OUTPUT_NODE],dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection("losses",regularizer(fc8_weights))
fc8_biases = tf.get_variable(name="bias",shape=[OUTPUT_NODE],dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
fc8 = tf.add(tf.matmul(fc7,fc8_weights),fc8_biases)
return fc8
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
#AlexNet网络的训练过程
import os
from tensorflow.python.framework import ops
import tensorflow as tf
from SIGNG_AlexNet import *
#配置神经网络参数
BATCH_SIZE = 32 #一个batch数据的数目
TRAINING_EPOCH = 30000 #训练迭代次数
LEARNING_RATE_BASE = 0.8 #基础学习率
LEARNING_RATE_DECAY = 0.99 #学习率衰减
REGULARAZTION_RATE = 0.0001 #描述模型复杂度的正则化在损失函数中的系数
MOVING_AVERAGE_DECAY = 0.99
#模型保存的路径和文件名
MODEL_SAVE_PATH = "/path/to/model"
MODEL_NAME = "model.ckpt"
#训练模型
def AlexNet_train(X_train,Y_train,X_test,Y_test,learning_rate=LEARNING_RATE_BASE,
num_epochs=TRAINING_EPOCH, minibatch_size=BATCH_SIZE, print_cost=True):
ops.reset_default_graph() # 在没有tf变量重写的情况下重新运行模型
(m, n_H0, n_W0, n_C0) = X_train.shape
n_y = Y_train.shape[1]
costs = [] # 列表存放目标函数值
#创建占位符
X = tf.placeholder(dtype=tf.float32,shape=(None,n_H0, n_W0, n_C0),name="X")
Y = tf.placeholder(dtype=tf.float32,shape=(None,n_y),name="Y")
#正则化
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
#前向传播
out = SIGNG_AlexNet.AlexNet(X,regularizer)
#变量模拟神经网络中的迭代次数,可用于动态控制衰减率
global_step = tf.Variable(0,trainable=False)
#定义损失函数、学习率、滑动平均操作机训练过程
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=out,labels=tf.argmax(Y,1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
cost = cross_entropy_mean + tf.add_n(tf.get_collection("losses"))
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,
m/BATCH_SIZE,LEARNING_RATE_DECAY)
optm = tf.train.AdamOptimizer(learning_rate).minimize(cost,global_step=global_step)
with tf.control_dependencies([optm,variable_averages_op]):
train_op = tf.no_op(name="train")
#初始化tensorflow持久化
saver = tf.train.Saver()
with tf.Session() as sees:
init = tf.initialize_all_variables()
sees.run(init)
#循环进行模型训练
for epoch in range(TRAINING_EPOCH):
minibatch_cost = 0
num_minibatch = int(m / minibatch)
minibatchs = random_mini_batches(X_train, Y_train, minibatch)
for minibatch in minibatchs:
#选择一个minibatch
(minibatch_X,minibatch_Y) = minibatch
_,temp_cost,step = sees.run([train_op,cost,global_step],
feed_dict={X:minibatch_X,Y:minibatch_Y})
minibatch_cost += temp_cost / num_minibatch
# 每 1000 次epoch打印目标函数值cost
if print_cost == True and epoch % 1 == 0:
costs.append(minibatch_cost)
if print_cost == True and epoch % 1000 == 0:
print("Cost after epoch %i:%f" % (step, minibatch_cost))
saver.save(
sees,os.path.join(MODEL_SAVE_PATH,MODEL_NAME),global_step==global_step
)
# 计算准确的预测
correct_predict = tf.equal(tf.argmax(out, 1), tf.argmax(Y, 1))
# 在测试集上计算准确率
accuracy = tf.reduce_mean(tf.cast(correct_predict, tf.float32))
print(accuracy)
train_accuracy = accuracy.eval({X: X_train, Y: Y_train})
test_accuracy = accuracy.eval({X: X_test, Y: Y_test})
print("Train Acurracy :" + str(train_accuracy))
print("Test Acurracy :" + str(test_accuracy))
return train_accuracy, test_accuracy
#加载数据集
X_train_orig,Y_train_orig,X_test_orig,Y_test_orig,classes = load_dataset()
#标准化特征值,使得数值在0至1之间
X_train = X_train_orig/255
X_test = X_test_orig/255
Y_train = convert_to_one_hot(Y_train_orig,6).T
Y_test = convert_to_one_hot(Y_test_orig,6).T
#调用构建的模型
AlexNet_train(X_train,Y_train,X_test,Y_test)
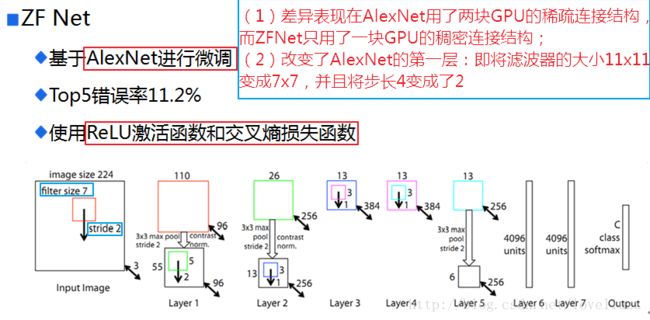
七、ZFNet